一.Solr4.x新特性
1.近实时搜索
Solr的近实时搜索【Near Real-Time,NRT】功能实现了文档添加到搜索的快速进行,以应对搜索快速变化的数据。
2.原子更新与乐观并发
原子更新功能允许客户端应用对已有文档上进行添加、更新、删除和对字段增值等操作,而且无需重新发送整个文档。当存在两个请求同时更改同一个文档时,Solr使用乐观机制防止不兼容的更新。简单来说就是Solr使用特殊的_version_版本字段来确保文档的安全更新语义。两个请求中后提交更改的请求将会获得一个过时的版本【这个版本是两请求都未执行之前的版本,然后先提交的请求会执行并修改版本号】,所以会执行失败【请求执行之前需要先确认版本,只有版本一致才可以执行请求】。
3.实时GET功能
无论文档是否已经提交到索引,使用实时GET功能都可以使用唯一标识符检索最新版本的索引【事务日志提供支撑】。这与使用行键【row key】检索数据的Cassandra的键-值存储方式类似。在Solr4之前,除非文档提交到Lucene的索引,否则是检索不出来的。且提交很花费时间,影响查询性能。
4.使用事务日志实现写持续性
当文档发送到Solr进行索引时,会被写到事务日志中,以防止服务器发生故障造成数据丢失。Solr的事务日志处在客户端应用与Lucene索引之间,对实时GET功能提供必要的支持,使其可以不考虑文档是否已经提交到Lucene,直接通过唯一标识符进行检索文档。Solr的事务日志解除了更新可见性与更新持久性之间的绑定。也就是说,文档可以持久存储,但不出现在搜索结果中。事务日志可以控制提交的文档在搜索结果中出现的时机,避免在提交之前因服务器出现故障而导致数据丢失。
5.使用Zookeeper实现简易分片和复制
在Solr4.x之前,需手动进行扩容。在Solr4.x之后,SolrCloud让扩容变得简单和自动化。在Solr中,Zookeeper负责指定分片代表与分片副本,并对服务请求可用的服务器机芯跟踪。SolrCloud与Zookeeper是绑定的,因此SolrCloud的启动无需做任何额外的配置和安装。
6.在以前的版本中,Solr主目录有配置文件solr.xml进行配置。从Solr4.4之后,内核可以被自动发现,不再需要在solr.xml中进行配置。
二.Solr5.x新特性
1.schema文件改名为managed-schema。
2.Solr4.x中的deprecated被去掉。
3.从Solr5开始,Solr不再以war的形式发布,Solr已然成为了一个独立的Java服务端应用,已经包括了start和stop脚本,并支持Unix和Windows平台。
4.solr.xml中的单位从cores变为solrcloud。
5.在Solr5.x中引入的Streaming表达式允许查询Solr并将结果作为数据流进行排序和聚合。
三.Solr6.x新特性
1.对Solr5.x中引入的Streaming表达式增加几种新的表达式类型:
>使用类似MapReduce的并行表达式来加快high-cardinality字段的吞吐量。
>守护程序表达式以支持持续推送或拉取流。
>高级并行关系代数,如分布式连接、交集、联合和补充。
>发布/订阅消息。
>用于从其他系统中提取数据并与Solr索引中的文档连接的JDBC连接。
2.并行SQL接口
构建在Streaming表达式的基础上,Solr6.x中的新增功能是一个并行SQL接口,可以将SQL查询发送到Solr。SQL语句被即时编译为Streaming表达式,提供可用于Streaming表达式请求的全部聚合。包含一个JDBC驱动程序,它允许使用SQL客户端和数据库可视化工具查询Solr索引并将数据导入到其它系统中。
3.跨数据中心复制
使用主动-被动模型,SolrCloud集群可以被复制到另一个数据中心,并用一个新的API进行监控。
4.QueryParse图
一个新的图形查询解释器可以使Solr文档建模的定向【循环】图的遍历查询成为可能。
5.DocValues
在Solr示例配置集中的大多数非文本字段类型现在默认为使用DocValues。
6.需要使用Java8
Solr6.x【SolrJ客户端】的Java最低支持的版本是Java8。
7.索引格式更改
Solr6.x不支持读取Lucene/Solr4.x以及更早版本的索引。如果索引中仍存在旧的4.x格式的字段,必须运行Solr5.x附带的Lucene IndexUpgrader。另外,使用Solr5.x充分优化索引,以确保只包含一个最新的索引段。
8.默认为托管模式
当solrconfig.xml没有明确定义
9.默认的相似性改变
当Schema没有明确地定义全局
10.副本和碎片删除命令更改
DELETESHARD和DELETEREPLICA修改为默认删除任何复制副本的实例目录、数据目录和索引目录。
11.删除facet.date.*参数
Solr3.x中被废弃的facet.date参数【以及相关facet.date.*参数】已被完全删除。
四.Solr7.x新特性
1.复制模式
直到Solr7.x,SolrCloud模型允许任何复制副本在领导者丢失时成为领导者。这对大多数用户来说非常有效,在集群出现问题的情况下提供可靠的故障切换。但是,由于所有副本必须在任何时候都保持同步,因此在大型集群中需要付出代价【副本本身就需要保持同步】。为了提供更多的灵活性,已经添加两种新类型的副本,TLOG&PULL。这些新类型提供了一些选项,以便仅通过从前导项复制索引段与引线同步副本。TLOG类型还有一个额外的好处,就是其维护一个事务日志【名字叫tlog】,如果需要的话,它可以恢复并成为领导者。PULL类型不维护事务日志,因此不能成为领导者。作为这种改变的一部分,传统的副本现在被命名为NRT。如果没有明确定义TLOG或PULL副本,则Solr默认创建NRT副本。
2.自动缩放
Solr自动缩放是Solr中的一个新功能套件,用于管理SolrCloud集群更加简单和自动化。Solr自动缩放的核心是为用户提供一个规则语法来定义在集群中分发节点和碎片的首选项和策略,目的是在集群中保持平衡。从Solr7.x开始,Solr将在确定创建或移动各种Collection API命令的新碎片或副本放置到何处时考虑策略和首选项规则。
3.新的默认配置集
data_driven_configset与basic_configset已被删除,取而代之的是_defaultconfigset。sample_techproducts_configset还被保留了下来,专门与example/exampledocs目录中的Solr附带的示例文档一起使用。当创建一个新的collection时,如果不指定configSet,默认_default将被使用。如果使用SolrCloud,_defaultconfigSet会自动上传到zookeeper。如果使用单独模式,instanceDir将会自动创建,使用_defaultconfigSet作为基础。
Solr7.x之前的版本【以6.6版本为例】:
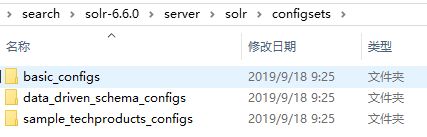
Solr7.x版本:
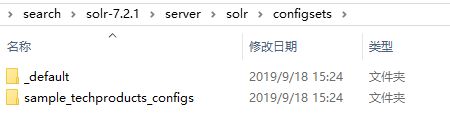
4.无模式的改进
默认情况下,传入的字段将被索引为text_general【可以修改】。该字段的名称将与文档中定义的字段名称相同。复制字段规则将被插入到模式中,以将新的text_general字段复制到具有名称的新字段。这个字段的类型是一个strings字段【允许多值】。默认文本字段的前256【可以修改】个字符将被插入到新的字符串字段中。
由于复制字段规则会降低索引的速度并增加索引大小,所以建议只在需要时使用复制字段。如果不需要对字段进行排序或分面,则应该删除自动生成的复制字段规则。可以禁用update.autoCreateFields属性禁用自动字段创建。使用命令修改配置:curl http://host:8983/solr/mycollection/config -d '{"set-user-property":{"update.autoCreateFields":"false"}}'。
5.对默认行为的更改
>JSON现在是默认的响应格式。如果依赖XML响应,现在必须在请求中定义:wt=xml。另外,行缩进是默认启用的【indent=on】。
>sow参数【Split on Whitespace】现在默认为false,允许支持多字同义词。该参数与eDismax和standard/lucene查询解析器一起使用。如果此参数没有明确指定为true,查询文本将不会在空白上拆分。
>legacyCloud参数现在默认为false。如果副本的项不存在state.json,则该副本将不会被注册。这可能会影响到复制副本的用户,并自动将其注册为分片的一部分。通过使用一下命令在集群属性中设置属性legacyCloud=true,可以退回到旧的行为。命令如下:./sever/scripts/cloud-scripts/zkcli.sh -zkhost 127.0.0.1:2181 -cmd clusterprop -name legacyCloud -val true。
>如果solrconfig中的luceneMatchVersion是7.0.0或以上版本则eDismax查询分析器参数lowercaseOperator默认为false。luceneMatchVersion低于7.0.0的行为是不变的【true】。这意味着客户端必须以大写的方式发送布尔运算符【AND/OR/NOT】才能被识别,或者必须明确设置该参数为true。
>如果luceneMatchVersion是7.0.0或以上版本,则solrconfig中的handleSelect参数默认为false。这会导致Solr忽略qt参数,如果它存在于请求中,请求处理程序没有前导'/',则可以设置handleSelect="true"或者考虑迁移配置。该qt参数仍用作指定要使用的请求处理程序的Solr特殊参数。
>lucenePlusSort查询解析器【旧的lucene查询解析器】已被弃用,不再隐式定义。若想继续使用这个解析器直到Solr8【该版本将删除这个解析器】,必须将它注册到solrconfig.xml中。如下:
>TemplateUpdateRequestProcessorFactory名称从Template更改为template,AtomicUpdateProcessorFactory的名称从Atomic改为atomic,此外,TemplateUpdateRequestProcessorFactory现在使用{}而不是${}作为模板。
五.备注
1.对于Solr升级,将数据重新编入索引被认为是最佳做法。如果重新索引不可行,请注意,Solr一次只能升级一个大版本【例如从6.x升级到7.x】。因此,Solr6.x索引与Solr7.x兼容,但Solr5.x索引则不会。