之前因为学习Keras的缘故,看到一个图像检索的Demo,代码实现了输入一张查询照片,检索出最相似的n张照片的效果。

进而用t-SNE将所有照片降至2维,以便可视化并观察相似照片是否聚集到了一起。下图是我“复现”了Demo后,一千张图像可视化的结果:可以看到右上角是人脸肖像簇;左边是摩托车簇;左下角是飞机簇等等,效果还不错。
最初看到这个demo,我非常兴奋,兴奋的原因大概有两点。其一是好几年前有这样一篇文章——《你说你看过2000部电影,我笑笑说我也是》——令我至今难忘。文中介绍了法国博主Christophe Courtois对诸多相似风格的电影海报进行了整理。
举几个例子:背靠背的两个人

下方的海滩与上方浮现的人物:

分开的双腿:

渗人的眼睛:

可以看出确实有很多相似的套路,如此说来设计海报也不是件多难的事嘛?!(设计师看了想打人)。不同类型的电影题材会有各自倾向的海报风格,这也并不是多眼前一亮的结论。但上述所引终归是多年前的文章以及他人的归纳结果,对于阅片篇并不多的我来说,更好奇的是,能否通过爬取电影海报(或其他主题,比如音乐专辑照片等)并结合文章开头的技术来挖掘出类似的结论,或者找到更多不曾被人归纳的风格。
为此我专门爬取了豆瓣电影“Top250”和“分类排行榜”的数据(后者通过md5值删除重复海报后从3853张降到2281张)分别进行了研究,这部分从爬虫代码、爬取的数据、海报检索以及可视化的内容均为在后续文章中涉及。
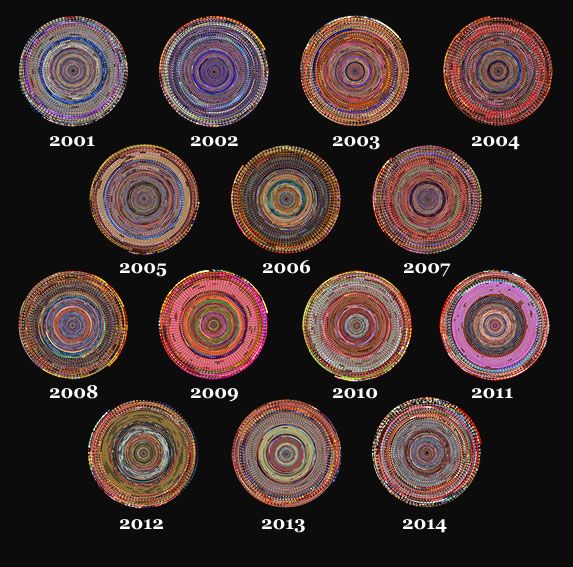
其二是2017年11月公众号上看到小火的清华美院的向帆老师在一席演讲的视频与文稿《如果把每年的春晚都像蚊香一样卷起来的话,它就是这样的》,各种酷炫的可视化作品令人叹为观止,非常推荐大家看一下此视频。相关作品也可到此网站查看。

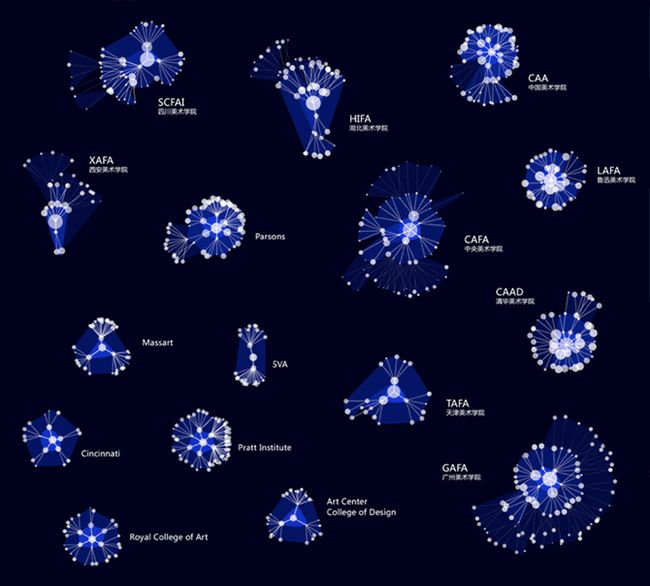
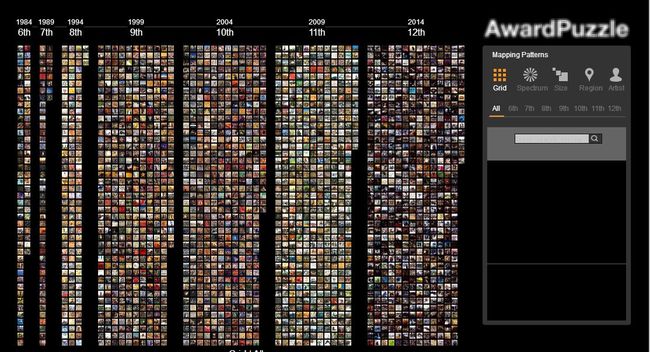
当时看完久久不能平静,想着离2018年春晚还早,要是能了解下这些作品都是怎么做出来的,然后趁着过年时“不进则已,一鸣惊人”下,也是美滋滋哈。但搜寻后却发现可能用到的软件等似乎蛮难上手,现今也记不得许多,唯有那会第一次知道“t-SNE”可以用来可视化高维数据这件事,觉得挺神奇的就存了些图。
但也并不清楚背后的数学原理以及具体如何操作照片数据集。以下是以动画的方式直观感受下使用t-SNE后MNIST手写数字类别不断分开的过程。
所谓:“念念不忘,必有回响”。一切因缘际会,万没想到却在学Keras时都撞上了。那么,这Keras又是什么东西呢?

简单的说,Keras 就是一个深度学习的python 库,可以以Tensorflow、Theano 以及CNTK 为后端。它简单易用,能像搭积木一般构建神经网络,对于新手小白而言,是最易上手深度学习的库,没有之一。
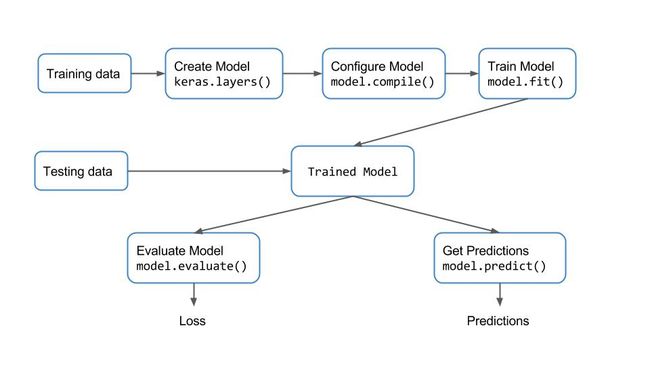
怎么个简单易用,本文暂且不表,后续系列再来讲解。你可能又会好奇,标题不是说好了介绍图像检索的嘛,怎么又扯到深度学习上了,到底是如何实现检索出相似图像,如何用t-SNE对海量图像进行可视化的呢?这其中的缘故,且听我慢慢道来。
深度学习、卷积神经网络有多火,想必大家都是知道的。但对于不曾了解过其原理的人而言,或许会觉得是很艰深晦涩、很高大上的事。如果一上来看到下面这样的图,心情一定不会美妙,一脸懵逼,这tm是个啥。
本文当然不会过多涉及这部分讲解,感兴趣的小伙伴可以阅读下这两个不错的知乎话题,看完你就比90%的人清楚CNN到底是怎么回事了:
能否对卷积神经网络工作原理做一个直观的解释?
CNN(卷积神经网络)是什么?有入门简介或文章吗?
那么原本用于图像识别,比如识别一张图像里到底是猫还是狗的卷积神经网络,又是结合到图像检索上的呢?以下图为例,CNN可以看成是特征提取和分类器两部分,通过一层层的神经网络对图像逐渐提取出抽象的特征,有了特征就有了可以区分和评判的指标,分类器就能识别出是猫还是狗了。
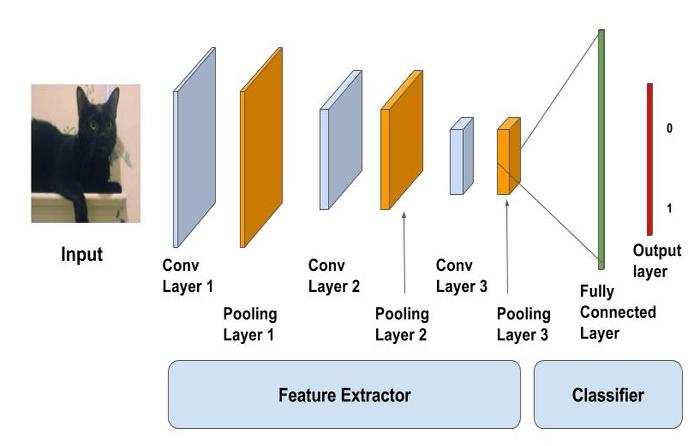
而如果把分类器去掉,用剩下的特征提取器对海量图像分别提取特征,并借助余弦相似度等衡量指标,我们就能实现上述的图像检索效果了。
类似流程图大致如下,相关阅读:《基于deep learning的快速图像检索系统》:
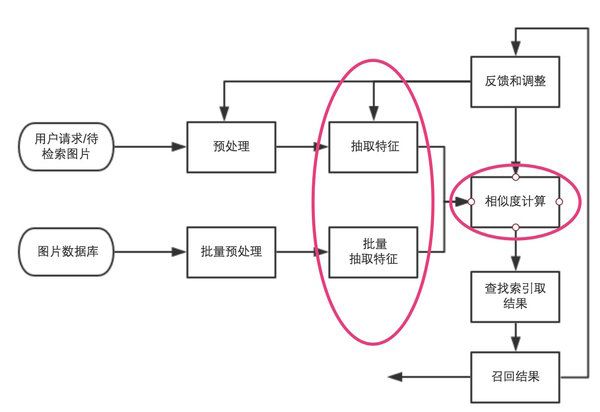
经过上述的介绍,你就对图像检索有了一定的了解,如果非常技痒,可以直接看Demo的代码:Image Search。当然后续我也会基于此继续更新本系列文章,涉及原始代码一些小BUG的修改与复现、豆瓣电影海报的爬取与研究、以及Keras的更多介绍、基于内容的图像检索(CBIR)的更多细节,以及可能的改进方向等等。敬请期待。
PS:欢迎关注公众号:牛衣古柳(ID:Deserts-X),以及欢迎加QQ群:Python交友娱乐会所(613176398)哈。娱乐会所,没有嫩模。