数据仓库概述
什么是数据仓库?
创始人W.H.Inmon在《建立数据仓库》一书中对数据仓库的定义是:数据仓库就是面向主题的、集成的、相对稳定的、随时间不断变化(不同时间)的数据集合,用以支持经营管理中的决策制定过程、数据仓库中的数据面向主题,与传统数据库面向应用相对应。
主题导向(Subject-Oriented)
主题是一个在较高层次上将数据归类的标准,每一个主题对应一个宏观的分析领域。有别于一般OLTP系统,数据仓库的资料模型设计,着重将资料按其意义归类至相同的主题区(subject
area),因此称为主题导向。举例如Party、Arrangement、Event、Finance、Market、Sales、Product等。
集成性(Integrated)
数据仓库中的数据是从原有分散的数据库中抽取出来的,由于数据仓库的每一主题所对应的源数据在原有分散的数据库中可能有重复或不一致的地方,加上综合数据不能从原有数据库中直接得到,因此数据在进入数据仓库之前必须经过数据加工和集成。这是建立数据仓库的关键步骤,首先要统一原始数据中的矛盾之处,还要将原始数据结构做一个从面向应用向面向主题的转变。
不变动性(Nonvolatile)
数据仓库的稳定性是指数据仓库反映的是历史数据,而不是日常事务处理产生的数据,数据经加工和集成进入数据仓库后是极少或根本不修改的,即使资料是错误的亦同。(i.e.错误的后续修正,便可因上述时间差异性的特性而被追踪)
时间差异性(Time-Variant)
数据仓库中数据的不可更新性是针对应用来说的,即用户进行分析处理时是不进行数据更新操作的。但并不是说,从数据集成入库到最终被删除的整个数据生成周期中,所有数据仓库中的数据都永远不变,而是随时间不断变化的。数据仓库是不同时间的数据集合,它要求数据仓库中的数据保存时限能满足进行决策分析的需要。
目标:为给数据集市装载数据提供基础组件,并用数据集市为最终用户提供数据。
功能包括:
获取数据
清洗数据
转换数据
管理粒度数据
管理一个特定主题所需的所有数据
能以多种方式存储数据
扁平、无结构文件
RDBMS
其它技术(压缩)
并保证:
对业务系统的影响最小
数据集市之间数据定义的一致性
一致的维表!
保存适量的历史数据
基础架构
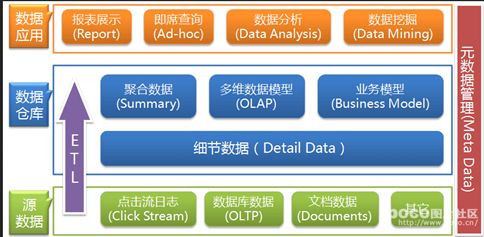
数据仓库只是存储数据的一种组织形式,是适合分析、决策用的特定的数据存储系统。
数据仓库的逻辑结构
数据仓库的物理结构
数据仓库系统(DWS)的体系结构
数据仓库的使用:
主要是在两个方面
1.使用浏览分析工具在数据仓库中寻找有用的信息;
2.基于数据仓库,在数据仓库系统上建立应用,形成决策支持系统。
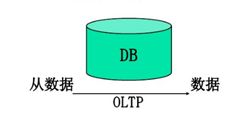
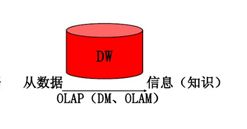
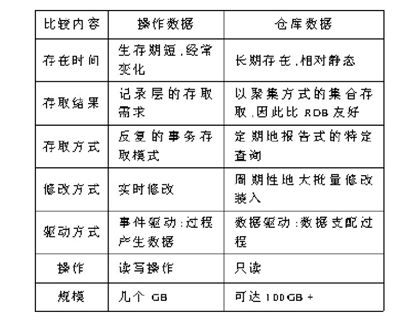
数据仓库与数据库的区别
acid(数据库事务正确执行的四个基本要素的缩写)
ACID,指数据库事务正确执行的四个基本要素的缩写。包含:原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、持久性(Durability)。一个支持事务(Transaction)的数据库,必需要具有这四种特性,否则在事务过程(Transaction
processing)当中无法保证数据的正确性,交易过程极可能达不到交易方的要求。
什么是OLAP,有什么用途
用户和系统的面向性:
OLTP是面向顾客的,用于事务和查询处理
OLAP是面向市场的,用于数据分析
数据内容:
OLTP系统管理当前数据.
OLAP系统管理大量历史数据,提供汇总和聚集机制。
数据库设计:
OLTP采用实体-关系(ER)模型和面向应用的数据库设计.
OLAP采用星型或雪花模型和面向主题的数据库设计.
视图:
OLTP主要关注一个企业或部门内部的当前数据,不涉及历史数据或不同组织的数据。
OLAP则相反.
访问模式:
OLTP系统的访问主要由短的原子事务组成.这种系统需要并行和恢复机制.
OLAP系统的访问大部分是只读操作.
元数据
数据仓库的核心
关于数据的数据,可理解为数据仓库的数据字典
存储数据模型、定义数据结构、转换规则、仓库结构和控制信息等。
元数据的功能:
描述仓库数据的来源信息
描述有关数据模型的信息
描述业务数据与仓库数据结构间的映射
描述仓库中信息的使用情况
好的元数据是数据仓库开发成功的关键因素
元数据分类:技术元数据;商业元数据;数据仓库的操作型信息。
什么是数据集市?
数据集市是一种具有特定应用的更小、更集中的数据仓库。
针对某个具有战略意义的应用或具体部门级的应用,它支持客户利用已有的数据获得重要的竞争优势或找到进入新市场的整体解决方案。
是为企业提供分析商业数据的一条廉价途径。
两种数据集市:依赖型和非依赖型
什么是维度,度量值/指标
维度分类:
普通维:普通维是基于一个维表的维度,由维表中的不同列来表示维度中的不同级别。
雪花维:雪花维是基于多个维表的维度,各个维表间以外键关联,分别存储同一维度中不同级别的成员列值。
父子维:父子维是基于两个维表列的维度,由维表中的两列来共同定义各个成员的隶属关系。一列称为成员键列,标识每个成员;另一列称为父键列,标识每个成员的父代。
缓慢变化维度(scd),有什么解决方法
处理缓慢变化维一般按不同情况有以下几种解决方案:
1.新数据覆盖旧数据
2.保存多条记录,并添加字段加以区分
3.不同字段保存不同值
4.另外建表保存历史记录
5.混合模式
一、新数据覆盖旧数据
此方法必须有前提条件,即你不关心这个数剧的变化。例如,某个纳税人的所属税务机关改了,如果你不关心纳税人的所属税务机关有什么变化则可直接覆盖(修改)数据仓库中的数据。
二、保存多条记录,并添加字段加以区分
这种情况下直接新添一条记录,同时保留原有记录,并用单独的专用的字段保存区别。如:
纳税人ID
纳税人识别号
纳税人名称
主管税务机关
有效标志
001
411402574988433
测试户
二七
N
002
411402574988433
测试户
金水
Y
纳税人ID
纳税人识别号
纳税人名称
主管税务机关
版本
001
411402574988433
测试户
二七
0
002
411402574988433
测试户
金水
1
以上是添加数据版本信息或是否可用来标识新旧数据。下面一种则是添加记录的生效日期和失效日期来标识新旧数据:
纳税人ID
纳税人识别号
纳税人名称
主管税务机关
有效日期始
有效日期止
001
411402574988433
测试户
二七
2012-01-01
2012-03-31
002
411402574988433
测试户
金水
2012-04-01
空的有效日期止表示当前版本数据,或者你也可一用一个默认的大时间(如: 12/31/9999)来代替空值,这样数据还能被索引识别到。
三、不同字段保存不同值
纳税人ID
纳税人识别号
纳税人名称
原主管税务机关
当前主管税务机关
001
411402574988433
测试户
二七
金水
这种方法用不同的字段保存变化痕迹.但是这种方法不能象第二种方法一样保存所有变化记录,它只能保存两次变化记录.适用于变化不超过两次的维度。
四、另外建表保存历史记录
即另外建一个历史表来表存变化的历史记录,而维度只保存当前数据。
纳税人维:
纳税人ID
纳税人识别号
纳税人名称
主管税务机关
有效日期始
有效日期止
001
411402574988433
测试户
金水
2012-04-01
纳税人维历史表:
纳税人ID
纳税人识别号
纳税人名称
主管税务机关
有效日期始
有效日期止
001
411402574988433
测试户
二七
2012-01-01
2012-03-31
这种方法仅仅记录一下变化历史痕迹,其实做起统计运算来还是不方便的。
五、混合模式
这种模式是以上几种模式的混合体,相对而言此种方法更全面,更能应对错综复杂且易变化的用户需求,也是较为常用的。
纳税人ID
纳税人识别号
纳税人名称
主管税务机关
有效日期始
有效日期止
有效标志
001
411402574988433
测试户
二七
2012-01-01
2012-03-31
N
002
411402574988433
测试户
金水
2012-04-01
Y
此中方法有以下几条优点:
1.能用简单的过滤条件选出维度当前的值。
2.能较容易的关联出历史任意一时刻事实数据的值。
3.如果事实表中有一些时间字段,那么我们很容易选择哪一条维度数据进行关联分析。
星型模型
星型模型是由单个事实数据表和一些维度表组成的构架模型。在这种模型中每个维度表均联接到事实数据表上。
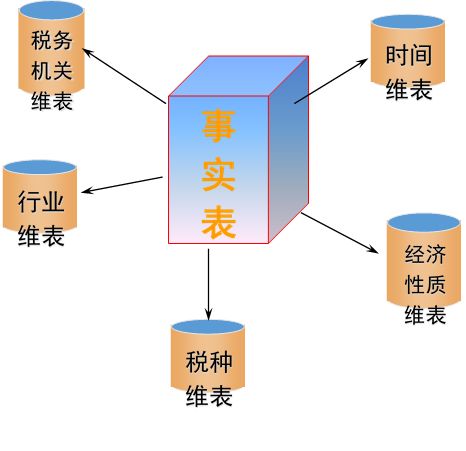
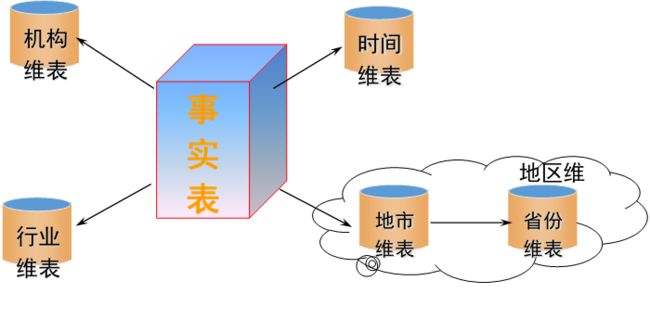
雪花型模型
雪花型架构比星型模型增加了次要维表,有一个或多个维表是联接到其它维表上,而非事实数据表上。
ETL:ETL(Extract/Transformation/Load)—用户从数据源抽取出所需的数据,经过数据清洗、转换,最终按照预先定义好的数据仓库模型,将数据加载到数据仓库中去。