W1
1.1 机器学习的策略
机器学习策略是一个方法论范畴的东西(而不是方法范畴)。举栗如下:
一个图像识别模型当前准确率为90%,未能达到应用要求。进一步优化该模型则有很多方法,如:增加样本量、改变算法、改变优化算法等,如下图。

但这些方法不见得有用,或者说,大部分是没用的,少部分真正解决模型当前瓶颈的方法才是有用的。但是我们不能无脑的把所有的方法都试一遍(时间成本、经济成本、人力成本等),而是用一些分析方法,分析出哪些优化方向可能是正确的。这里所说的分析方法,就是“机器学习策略”的概念
1.2 正交化
1. 举个栗子说明正交化
把汽车驾驶简化为两个操作项:方向盘控制方向、油门控制速度,这就是一组正交化的操作。假设一个汽车的驾驶操作如下:调整方向盘会导致方向和速度分别按某一组系数发生变化,调整油门则会导致方向和速度按另一组系数变化。这样的操作设置下,要想达到某一个方向和速度,或单纯的调节速度或方向时,都要同时操作方向盘和油门才能实现。这就叫非正交化。
所谓正交,就像空间几何或线性代数中所说的向量正交概念。方向盘和速度是正交的,方向盘的变化不会影响速度,油门和汽车行驶方向是正交的,油门变化不会影响汽车的行驶方向。
2. 正交化和机器学习的关系
机器学习的基本链条为:训练集 -> 验证集 -> 测试集 -> 现实世界,如下图所示。

在对模型进行调优时,每一次操作(可能是同时调整了一组参数),都是针对上述四个方面之一进行优化。
当发现在训练集表现不好时,为了优化训练集表现,可以尝试加大训练集、增加迭代次数等;
当发现在训练集表现可以但在验证集上表现不行时,为了优化在验证集上的表现,可以加入一些正则项等;
当发现在训练集和验证集上表现均可以,但在测试集上表现不行时,为了优化在测试集上的表现,可以调大验证集(推测此时是在验证集上发生了过拟合)等;
当发现在训练集、验证集、测试集上表现均可以,但在现实世界中表现不行时,为了优化模型,可以考虑加大整个数据集、改变损失函数(可以推测当前的优化目标与现实世界不符)等。
以上就是所谓“正交化调参”的操作。举例来说,early stopping就是一个非正交化的操作(%%)
1.3 单一评估指标
在评估一个模型时,应该根据模型的实际使用场景事先确定好一个单一的指标。比如准确率、召回率、F1、AUC、KS等。不管是用什么指标,关键是指标要确定且单一。举例来说,如果一个场景要求非常高的准确率,但对其它指标要求不高,那就应该把准确率当作评估模型的指标。此时如果模型A的准确率高于B,召回率、F1等都低于B,结论是A是更优的模型。
1.4 要优化的指标和要满足的指标
如1.3所言,评估模型应该用单一指标,这个指标也就是要优化的指标。但其它指标有时也要兼顾,比如模型预测耗时。这种指标不可能是要优化的指标,但也肯定有要求。如果一个猫脸识别的模型预测很准确,但每次预测都要花费1个小时,那也是不可用的。最终目标则可能描述为:在预测耗时<100ms的条件(要满足的指标)下,调优以提高模型的准确率(要优化的指标)。

另一个典型的栗子是精确率和召回率的平衡问题。比如癌症预测,我们比较care的是如果一个人得了癌症,我们能不能尽可能大概率的把他检测出来(召回率),而相对而言不太care我们判断为癌症的人里,有多少人是真正得了癌症(精确率)。所以可以把召回率定位优化目标。但精确率也不能太低,不然无脑把所有人都判为癌症就好了。最终目标可能描述为,在精确率不低于0.05(要满足的指标,误诊率不要太高)的前提下,召回率优化到0.99999(要优化的指标)
1.5 训练/验证/测试集的划分
(为什么还在说这个问题,大雾)
1. 数据集整体要与未来模型应用场景相符:你要把猫脸识别模型应用到全世界,就要收集全世界的猫的照片作为数据集,而非仅仅收集河北唐山的。
2. 训练集/验证集/测试集的划分一定要保证三者是同分布的(即随机划分)。不能说把欧亚的猫片作为训练集,把美洲的猫片作为训练集,这种操作是不行的。
1.6 训练/验证/测试集的大小
1. 传统的划分方式:把数据按照7:3划分为训练集/测试集 或 按6:2:2划分为训练集/验证集/测试集。这种方式在样本量还不大(比如1W以下)的时候是合理的。
2. 但是当样本量已经有百万集的时候,上述划分方式不合理。设想以下我们有一个一百万样本量的数据集,如果按照7:3划分出测试集,那就是30W。不管是准确率、精确率、召回率、F1、AUC、KS的哪一个,任何指标都不需要用30W个样本才能准确的衡量出来。对于一个100W的样本集,一个合理的划分方式为:98W作为训练集、1W作为验证集、1W作为测试集。足矣。
1.7 什么时候改变优化指标?什么时候改变数据集?
1. 什么时候改变优化指标?有A、B两个猫脸识别模型,假设使用的优化指标是准确率,结果A为95%,B为97%。从优化指标上看,B是更好的模型。但在实际应用中发现,B模型会错误的把一些色情图片识别成猫然后推送给用户,带来了极其恶劣的影响,是公司坚决不能接受的(滑稽)。因此实际应用来看,其实A是更好的模型。这就是“优化指标没有正确的评估出更好的模型”的问题。此时应该改变优化指标,比如变准确率为加权准确率,如果是把色情图片识别成猫,把这个错误加倍加倍再加倍,这个加权准确率显然是更接近实际场景的优化指标。
2. 什么时候该改变数据集?如果在训练猫脸识别模型时,所用的图片都是从正经网站上down下来的高清大图,要构图有构图,要聚焦有聚焦,并训出了一个看起来很好用的模型。但这个模型实际给用户使用时却发现很差,因为用户所拍的照片烂得一逼,构图聚焦全没有。这就是模型开发所用数据集与实际场景不符的问题。这个时候应该搞一些实际场景所用到的照片来作为数据集进行模型开发。
1.8 人的表现
1. 贝叶斯错误率:不管是模型还是人,对于一个事情的判断都不能做到百分之百准确,有些声音就是如此嘈杂以至于无法识别,有些图片就是如此地模糊以至于无法判断有没有猫。在理论上能达到的一个最优的错误率叫做“贝叶斯错误率”,无论是人还是模型的表现都不会超过这个理论界线。
2. 模型优化的过程:一般来说,当模型表现差于人时,优化起来容易一些;当模型超过人类时,优化则开始变得困难;随着模型表现不断逼近贝叶斯最优表现,优化会变得越来越难。


3. 如上图所示,当模型表现差于人时。我们可以1)利用人工标注为模型提供更多的数据集,即所谓的先有人工再有只能(大雾);2)通过分析bad case探索模型可以优化的点,即增强业务理解(大雾*2);3)更好的偏差方差分析(?)
1.9 可避免偏差

大概内容:对于图像识别问题,人类可以说是非常擅长的,所以可以把人类的错误率认为成贝叶斯错误率。当模型与人类的表现差很多时,意味着有进一步优化的空间。
问题:人类的错误率是指每个人的错误率,还是指全体人类的错误率呢?如果任意一个人的错误率是1%,多叫几个人进行标注然后bagging一下就能大幅降低错误率。贝叶斯错误率到底指的什么?
1.10 理解人的表现
本节恰好解释了上一节的问题。贝叶斯错误率指的是理论上的最优错误率,而实际上不管是人还是模型都不会超过贝叶斯错误率所表达的上限。

在上图中,判断一个医学影像时,一个普通人、一个普通医生、一个经验丰富的医生、一个医师团队所能达到的正确率是不一样的。比如团队的表现最佳,可以达到0.5%的错误率,这个时候可以说:贝叶斯错误率不超过0.5%,至于是多少反倒不重要。
1.11 超越人的表现

在点击率预测、商品推荐、贷款审核等业务领域,模型的表现早就远远超过人类了,所以讨论超越人的表现没什么意义。本节略。
1.12 改善模型的基本策略
1. 首先要保证模型在训练集上表现足够好(即偏差足够小)。“足够小”的含义是与“人类表现”接近或差的不多。
2. 在1的基础上通过加大数据集等使得模型在测试集上的表现也要足够好。
3. 就本人所从事的信贷风控领域,由于模型表现本就远超于人,所以很难再第1条有定性的衡量。如果人的最优表现是AUC=0.75,那么模型在训练集上再往上调的意义就不大了,反倒是学了一堆没有用的东西。问题是人的表现能有多好是未知的(或者说贝叶斯错误率是未知的),所以就只能靠经验了。
W2 误差/错误分析策略
2.1 错误分析

本节以猫片识别模型为例,阐述如何进行错误分析。猫片识别模型是二分类模型,在进行错误分析时,应该
1)随机或全部取出被分错的样本,对错误的样本进行归类分析,比如分别是大型猫科动物类、狗类等。
2)如果看到大部分被分错的样本都是狗,那么可以针对性的优化,比如收集更多的狗片并进行正确标注以丰富这类样本,或提高这类样本的权重。
3)不同的错误所占的比例,也代表了这个优化方向的上限。比如错误的10%是狗片,那么如果把优化方向放到狗这个方向上,就算能把所有的狗都识别对(不再识别成猫),也只能降低10%的错误率。
本节讲错误分析的思路,但我觉得更重要的是提供了“case分析”的思路。在信贷风控领域,模型本质并不是分类,而是排序或回归模型。在模型训练完成后,可以分别取出是好人却被打出很低的分数 和 是坏人却被打出很高的分数 的一些case,研究其特征,从而为优化模型提供思路和灵感。
2.2 清除标记错误的样本
错误样本:数据集是有X和Y构成,而Y不可避免的会有一些错误,有时候是标记错误,比如把一些小奶狗标记成了猫,有时候是定义上的问题,比如在信贷风控领域,是很难界定一个阈值说逾期天数大于这个值就是坏,小于这个值就是好,等。
处理方式:深度学习模型对于随机错误有较好的鲁棒性,如果数据集中有少量、随机的标签错误,可以不加整改。但系统性错误则一定会影响模型效果,比如如果把所有的白色的狗标记成猫,那模型必然会学到这个错误知识,此时则必须修正数据集(这还用说)。
验证集评估角度:如果错误的样本是少量且随机的,是不是一定不需整改呢?不是的。举例来说,如果目前在验证集上错误率是10%,然后发现其中的0.8%是由标签错误导致的,此时不需整改,而应该把重点放在降低整体的10%上。但如果错误率已经降到了2%,,仍然有其中的0.8%是标签错误导致,此时就必须整改了。可以说此时验证集已经失去了评估功能,因为有太多错误样本。
2.3 快速搭建简单地模型,然后进行迭代
本节的内容可以用标题概括:当面对一个业务场景,需要一个模型去解决问题时,首先要的一定不是去设计一个复杂而精细的模型。
首先:需要分析业务场景,从而准备出基础但是正确的数据集(样本、标签、可用的特征集),在此基础上用一个较简单地算法/网络结构迅速开发出一个简单地模型。
然后:进行偏差/方差分析等,找到可以优化的点,不断从样本层面、特征层面、算法层面去优化模型,最终解决问题。
如果一开始就搭建了复杂的模型,会导致接下来的误差分析难以进行,且更复杂的设计代表更多的潜在的坑。
2.4 训练集/测试集不遵从同一分布的情况
(训练集/测试集划分是个永恒的问题,大雾)
本节回答的问题是:如果模型应用场景所涉及的样本量较少,同时有大量与模型应用场景不符、但类似的样本,此时应该如何利用整个数据集,应该如何划分训练集/验证集/测试集。
说人话:仍然以猫脸识别模型为例,为了开发该模型,在网上采集了20W张猫片,该模型将用于猫脸识别手机app,而app采集了用户自己上传的猫片,2W张。一个问题是:网上采集的20W张猫片都是些高清大图,而用户自拍的2W张猫片大都模糊不清、没有任何构图美感可言,这两者显然不是同一分布。另一个问题是:模型最终要应用到手机app上,换言之,模型应用所面临的是和2W张用户自拍猫片类似的。此时应该如何划分训练集/测试集。
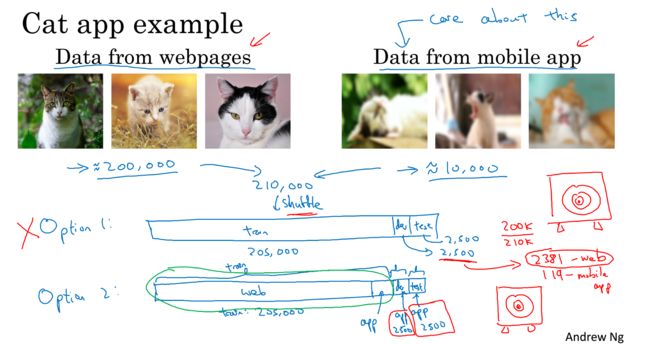
按照以往“训练集/测试集应遵从同一分布”的要求,应该把这22W样本混合在一起,随机划分train/test。但这样的训练结果是:模型可能在测试集上表现较好,但测试集里只有少量用户猫片,这意味着模型可能擅长识别高清大图猫片,但应用到手机APP上去识别用户自拍时,可能并不好用。
正确的划分方式是:把20W高清大图全部加入训练集,把2W用户猫片按0.5:0.5或0.5:0.25:0.25加入训练集/验证集/测试集。简言之,我们要保证验证集和测试集的分布是和模型应用场景一样的。
就个人所从事的互金信贷风控领域,会经常面临类似的问题:一个新接入的渠道只有少量可用样本,不足以建模;老渠道积攒了足够的样本量,但与新的渠道在流量上有一些差异。此时应该如何建立一个较好的模型?在训练集/测试集的划分上本节提供了答案。
2.5 训练集/测试集不是同一分布时如何进行偏差/方差分析
在讲解偏差/方差分析时,前提假设是训练集/测试集遵从同一分布,基本思路是:若训练集与贝叶斯误差(或人类水平)相差较多,则是偏差问题,若测试集与训练集相差较多,则是方差问题。
当训练集/测试集不是同一分布时,引来新的问题:数据不匹配。测试集与训练集相差较多,有可能不是方差问题,而是两者不是同一分布造成的。
以下是解决方案:
1)首先按照2.4所描述的方式,划分为train/./test
2)把train以随机的方式划分为train-train / train-dev(类似9:1的比例)
3)使用train-train集进行训练
4)在train-dev和test上进行验证
5)若train-train与贝叶斯误差(或人类误差)相差较多,则优化偏差;若train-train与train-dev相差较多,则优化方差;若train-train与train-dev接近,但与test相差较大,则是数据集不匹配导致。
2.6 如何解决数据不匹配的问题
没什么好的解决办法,本节略。
2.7 迁移学习(transfer learning)
1. 什么是迁移学习?

假设我们有一个较大的猫片集(20W),设计了如上的网络结构,并训练了一个猫脸识别模型。现在我们希望搞一个X片判别模型,但是现在只有100张可用的X片。因此设想利用一下现有的猫脸识别模型,利用方法如下:
① 保留现有的猫脸识别模型,但丢掉其输出层(以及由最后一个隐藏层到输出层的权重矩阵),或输出层及最后若干个隐藏层(及所有相应的权重矩阵);
② 重新初始化最后一层或若干层的权重矩阵;
③ 利用100张X片进行训练,此时网络的前n-1层权重都是固定的(来自猫片),得到训练的仅是输出层前的权重;
④ 训练完成,得到X片判别模型。
2. 何时应用迁移学习?

在满足以下条件时方可使用任务A到任务B的迁移学习:
① 任务A和任务B的输入数据格式是一样的,比如都是图片、都是声音等;
② 任务A可用的数据量较大,任务B可用的数据量较小;
③ 任务A从输入中提取的低级特征对任务B有帮助
3. 迁移学习的直观理解
为什么猫脸识别模型对X片判别模型会有帮助?因为两者本质都是图像识别模型(2-①)。
对于一个猫脸识别模型而言,它首先要学的是点、线、弯曲等低级特征的表示,并基于此学习高级特征,然后再学习什么样的高级特征代表着这个输入是猫或不是猫。而显然这种低级特征识别是所有的图像识别类任务共有的,因此利用猫脸识别模型的低级特征提取模块(也就是前几层)会对X片判别有帮助(2-③)。
但迁移学习不见得总有必要。当我们只有100张X片时,要基于如此小的样本量让模型完成低级特征提取、高级特征提取、阴阳性判断,是相当不现实的。此时应用迁移学习把猫脸识别模型拿过来用一下前几层,是有帮助的。但如果我们已经有100W张X片了,就没有必要非要把猫脸识别模型迁移过来了(2-②)。
2.8 多任务学习
1. 什么是多任务学习
以无人驾驶场景为例。我们给定一个数据集,是关于各种路况的照片。现在开发一个模型,该模型对路况的元素进行识别,包括红绿灯、斑马线、车道线、行人、停止标志等等。这就算是多任务学习了。因为该模型并不是简单的“红灯识别模型”或“斑马线识别模型”,而是要同时识别场景中有没有红灯、有没有斑马线、有没有行人...同时学习/完成多个任务。
2. 什么时候使用多任务学习
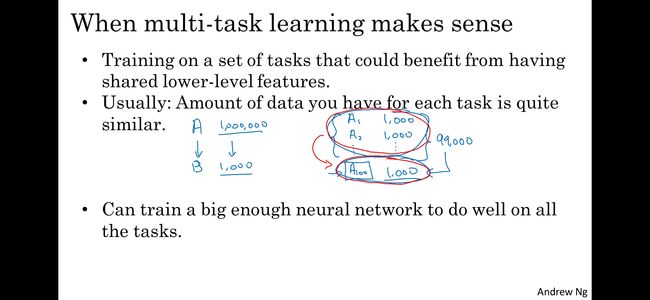
如上图所示,在满足以下描述时,适用多任务学习:
(1)这些任务可以共用/共享一些低级特征,如点/线/弯曲这种;
(2)这些任务所用的数据集(输入特征)是相似的(比如都是路况图片);
(3)在一个足够大的网络上,可以实现一个把各个任务都完成得很好的“大一统模型”。
3. 多任务学习与多分类问题的区别
从标签来看,多分类问题的标签是one-hot向量;多任务学习的标签是由0和1构成的向量,但不一定是one-hot的。
2.9~2.10 端到端(end to end)的深度学习
1. 什么是端到端的深度学习
假如要开发一个语音翻译模型,该模型输入是一段中文语音,输出是对应的英文翻译语音。
非端到端(带人工组件设计)的模型大概是这样的:先搞一个从中文语音到中文文字的语音识别模型,再搞一个从中文文字到英文文字的机器翻译模型,再搞一个从英文文字到英文语音的语音合成模型,最后把三个模型串起来使用。
端到端的深度学习是这样的:设计一个神经网络,输入时中文语音,输出是英文语音,训去吧~
2. “端到端”的优缺点

优点:更少的人为设计,更多的让数据说话。
缺点:需要非常大量的数据;有时候人为设计会起到很大的作用(所以优点也不见得是优点了)
3. 什么时候使用端到端的设计
什么时候都不该用。(hehe)
4. 端到端学习的直观理解
以人脸识别门禁系统为例。数据集是这样的:X是一堆照片,这堆照片是人走进门禁时摄像头抓拍的,Y是照片上对应的人是或不是公司员工(以及是的话具体是谁)。
端到端就是直接把X和Y甩到网络里去训。最大的问题是:X是原始照片,这个人或远或近、或高或低、或明或暗、衣服千奇百怪,但这些其实都不是这个人是谁(Y)的决定因素。模型不得不从包含大量无用信息的输入中去学习到核心的因素(人脸特征信息),这就加大了训练的难度。
所以如果不采用端到端,而是先开发出一个“人脸裁剪模型”,能够把照片中的人脸部分裁剪出来并形成相对标准的图片X'。然后再基于X'训练人脸识别模型。毫无疑问这样设计的模型肯定更准确。
所以理解来就是,“非端到端”就是加入了一些人为设计的中间环节,而人为设计大部分时候是有用的。除非确认某个人为设计是无效的,负责不要使用所谓的“端到端学习”。