上一篇笔记在这里:《机器学习》西瓜书学习笔记(五)
第九章 聚类
9.1 聚类任务
无监督学习(unsupervised learning):训练样本的标记信息是未知的,目标是通过对无标记训练样本的学习来揭示数据的内在性质及规律。
聚类:将数据集中的样本划分为若干个通常是不相交的子集(称为簇)。
9.2 性能度量

聚类性能度量外指标
- Jaccard系数(Jaccard Coefficient,简称JC)
- FM指数(Fowlkes and Mallows Index,简称FMI)
- Rand指数(Rand Index,简称RI)
上述性能度量的结果值均在[0,1]区间,值越大越好。
对于簇划分C={C1,C2,...,Ck},定义
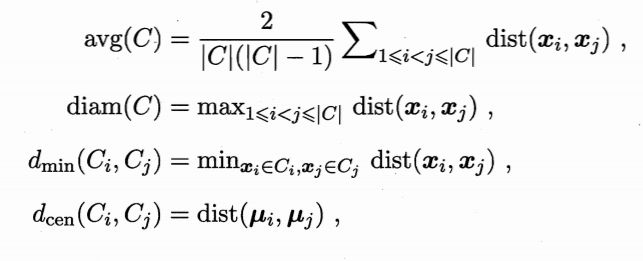
dist(·,·)是两个样本间距离
μ代表簇C的中心点
avg(C)对应于簇C内样本间平均距离
diam(C)对应于簇C内样本间的最远距离
dmin(Ci,Cj)对应于簇Ci与簇Cj最近样本点间的距离
dcen(Ci,Cj)对应于簇Ci与簇Cj中心点间的距离
聚类性能度量内指标
- DB指数(Davies-Bouldin Index,简称DBI)
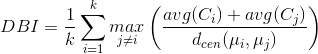
- Dunn指数(Dunn Index,简称DI)
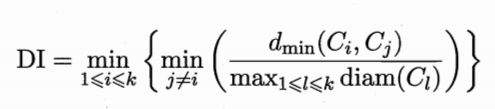
9.3 距离计算
距离度量(distance measure):函数dist(·,·)满足以下性质:
- 非负性:dist(xi,xj)>=0;
- 同一性:dist(xi,xj)=0当且仅当xi=xj;
- 对称性:dist(xi,xj)=dist(xj,xi);
- 直递性:dist(xi,xj)<=dist(xi,xk)+dist(xk,xj).
闵科夫斯基距离(Minkowski distance)
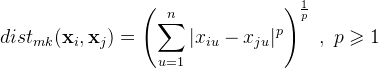
加权闵科夫斯基距离
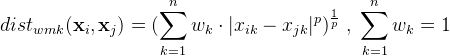
p=2时,闵科夫斯基距离就是欧氏距离(Euclidean distance)
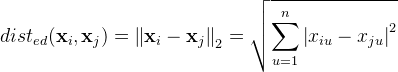
p=1时,闵科夫斯基距离就是曼哈顿距离(Manhattan distance):
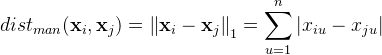
能直接在属性值上计算距离的属性称为有序属性,反之称为无序属性。
对无序属性可采用VDM(Value Difference Metric)。令mu,a表示在属性u上取值为a的样本数,mu,a,i表示在第i个样本簇中在属性u上取值为a的样本数,k为样本簇数,则属性u上两个离散值a与b之间的VDM距离为
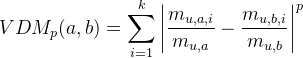
将闵科夫斯基距离和VDM结合起来
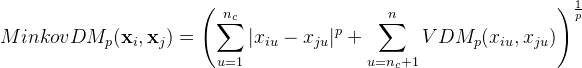
非度量距离(non-metric distance):不满足直递性。
9.4 原型聚类
算法先对原型进行初始化,然后对原型进行迭代更新求解。
9.4.1 k均值算法

9.4.2 学习向量量化

学得一组原型向量{p1,p2,...,pq}后,即可实现对样本空间X的簇划分。对任意样本x,它能被划入其距离最近的原型向量所代表的簇中,即
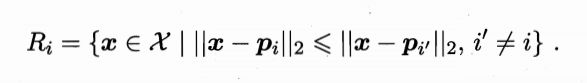
称为Voronoi划分。
9.4.3 高斯混合分类
高斯分布的概率密度函数:
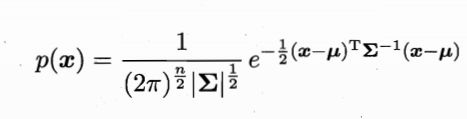
μ为n维均值,Σ是n×n的协方差矩阵,概率密度函数记为p(x|μ,Σ)
混合高斯分布:由k个高斯分布混合而成。
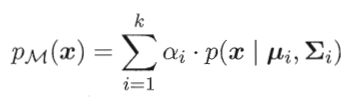
其中,“混合系数”αi>0
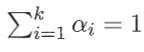
假设样本的生成过程由高斯混合分布给出:首先,根据混合系数αi(也是第i个混合成分的概率)定义的先验分布选择高斯混合成分;然后,根据被选择的混合成分的概率密度函数进行采样,从而生成相应的样本。
若训练集D={x1,x2,...,xm}由上述过程生成,令随机变量zj∈{1,2,...,k}表示生成样本xj的高斯混合成分,其取值未知。显然zj的先验概率P(zj=i)对应于αi(i=1,2,...,k).根据贝叶斯定理,zj的后验分布对应于
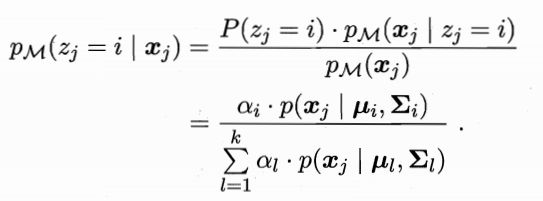
简记为γji(i=1,2,...,k)
将样本D划分成k个簇C,样本xj的簇标记为λj要最大化γji。
做一下极大似然估计
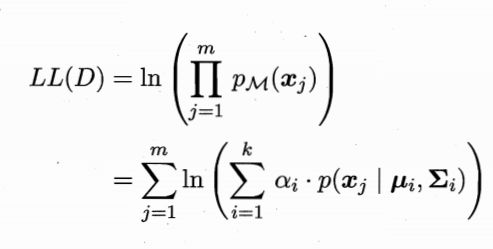
求导置0,解得
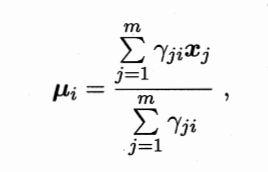
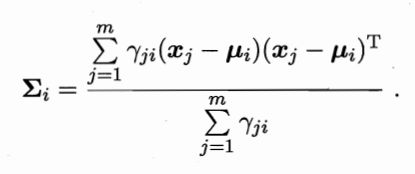
此外还要考虑αi的和为1,则有拉格朗日函数


9.5 密度聚类
密度聚类算法假设聚类结构能通过样本分布的紧密程度确定。
- ε-邻域:Nε(xj)={xi∈D|dist(xi,xj)<=ε}
- 核心对象xj:|Nε(xj)|>=MinPts
- 密度直达:若xj位于xi的ε-邻域中,且xi是核心对象,则称xj由xi密度直达。
- 密度可达:对xi与xj,若存在样本序列p1,p2,...,pn,其中p1=xi,pn=xj且pi+1由pi密度直达,则称xj由xi密度可达。
- 密度相连:对xi与xj,若存在xk使得xi与xj均由xk密度可达,则称xi与xj密度相连。

9.6 层次聚类
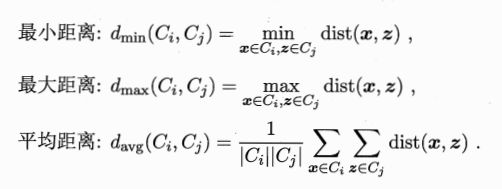

下一篇:《机器学习》西瓜书学习笔记(七)