CMS垃圾回收器详解
https://www.jianshu.com/p/08f0b85ad665
垃圾回收器组合
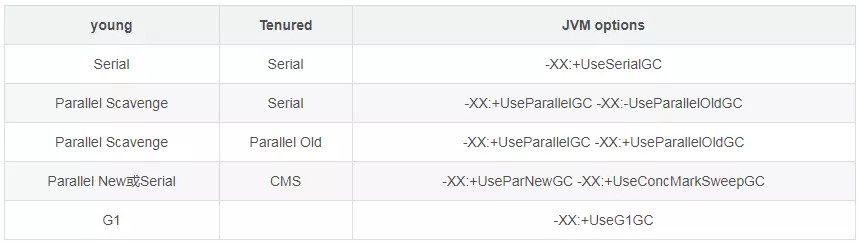
垃圾回收器从线程运行情况分类有三种:
- 串行回收,Serial回收器,单线程回收,全程stw;
- 并行回收,名称以Parallel开头的回收器,多线程回收,全程stw;
- 并发回收,cms与G1,多线程分阶段回收,只有某阶段会stw;
CMS垃圾回收
CMS垃圾回收特点
- cms只会回收老年代和永久带(1.8开始为元数据区,需要设置CMSClassUnloadingEnabled),不会收集年轻带;
- cms是一种预处理垃圾回收器,它不能等到old内存用尽时回收,需要在内存用尽前,完成回收操作,否则会导致并发回收失败;所以cms垃圾回收器开始执行回收操作,有一个触发阈值,默认是老年代或永久带达到92%;
CMS垃圾回收器工作原理
CMS的GC过程有6个阶段(4个并发,2个暂停其它应用程序):
1. 初次标记(STW initial mark):标记老年代中所有的GC Roots引用的对象;标记老年代中被年轻代中活着的对象引用的对象(初始标记也会扫描新生代);会导致stw。
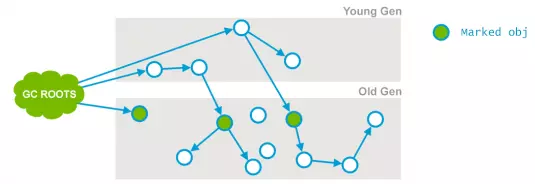
2. 并发标记(Concurrent marking):从初次标记收集到的‘根’对象引用开始,遍历所有能被引用的对象。
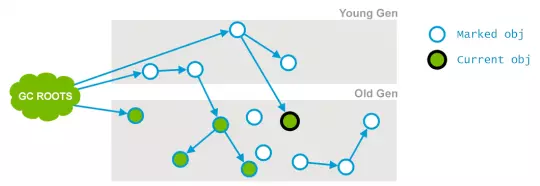
3. 并发可中断预清理(Concurrent precleaning):改变当运行第二阶段时,由应用程序线程产生的对象引用,以更新第二阶段的结果。标记在并发标记阶段引用发生变化的对象,如果发现对象的引用发生变化,则JVM会标记堆的这个区域为Dirty Card。

那些能够从Dirty Card到达的对象也被标记(标记为存活),当标记做完后,这个Dirty Card区域就会消失。
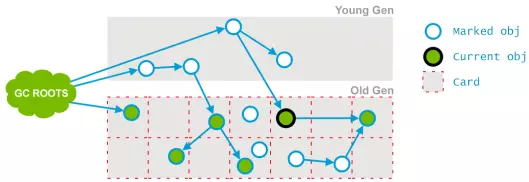
4. 最终重新标记(STW remark):由于并发预处理是并发的,对象引用可能发生进一步变化。因此,应用程序线程会再一次被暂停(stw)以更新这些变化,并且在进行实际的清理之前确保一个正确的对象引用视图。这一阶段十分重要,因为必须避免收集到仍被引用的对象。
5. 并发清理(Concurrent sweeping):清理垃圾对象,这个阶段收集器线程和应用程序线程并发执行。
6. 并发重置(Concurrent reset):CMS清除内部状态,为下次回收做准备。
问题思考
1. 并发预处理阶段意义何在?
并发预处理阶段做的工作还是标记,与4的重标记功能相似。既然相似为什么要有这一步?
前面我们讲过,CMS是以获取最短停顿时间为目的的GC。重标记需要STW(Stop The World),因此重标记的工作尽可能多的在并发阶段完成来减少STW的时间。
此阶段标记从新生代晋升的对象、新分配到老年代的对象以及在并发阶段被修改了的对象。
2. 如何确定老年代的对象是活着的?
答案很简单,通过GC ROOT TRACING可到达的对象就是活着的。

老年代进行GC时如何确保上图中Current Obj标记为活着的?答案是必须扫描新生代来确保。这也是为什么CMS虽然是老年代的gc,但仍要扫描新生代的原因。
在CMS日志中我们可以清楚地看到扫描日志:
[GC[YG occupancy: 820 K (6528 K)] [Rescan (parallel) , 0.0024157 secs] [weak refs processing, 0.0000143 secs] [scrub string table, 0.0000258 secs] [1 CMS-remark: 479379K(515960K)] 480200K(522488K), 0.0025249 secs] [Times: user=0.01 sys=0.00, real=0.00 secs] Rescan阶段(STW remark的一个子阶段)会扫描新生代和老年代中的对象。在日志中可以看到此阶段标识为Rescan (parallel),说明此阶段是并行进行的。
重点来了:全量的扫描新生代和老年代会不会很慢?肯定会。CMS号称是停顿时间最短的GC,如此长的停顿时间肯定是不能接受的。如何解决呢?那就是必须要有一个能够快速识别新生代和老年代活着的对象的机制。
新生代垃圾回收完剩下的对象全是活着的,并且活着的对象很少。如果能在并发可中断预清理阶段发生一次Minor GC,那STW remark的时间就会缩短很多。
CMS 有两个参数:CMSScheduleRemarkEdenSizeThreshold、CMSScheduleRemarkEdenPenetration,默认值分别是2M、50%。
- -XX:CMSScheduleRemarkEdenSizeThreshold(默认2m):控制abortable-preclean阶段什么时候开始执行,即当eden使用达到此值时,才会开始abortable-preclean阶段。
- -XX:CMSScheduleRemarkEdenPenetratio(默认50%):控制abortable-preclean阶段什么时候结束执行。
所以两个参数组合起来的意思是eden空间使用超过2M时启动可中断的并发预清理,直到eden空间使用率达到50%时中断,进入remark阶段。
那可终止的预清理要执行多长时间来保证发生一次Minor GC呢?答案是没法保证。道理很简单,因为垃圾回收是JVM自动调度的,什么时候进行GC我们控制不了。
但此阶段总有一个执行时间吧。CMS提供了一个参数CMSMaxAbortablePrecleanTime ,默认为5S。只要到了5S,不管发没发生Minor GC,有没有到CMSScheduleRemardEdenPenetration都会中止此阶段,进入remark。
如果在5S内还是没有执行Minor GC怎么办?CMS提供CMSScavengeBeforeRemark参数,使remark前强制进行一次Minor GC。
这样做利弊都有:
- 好的一面是减少了remark阶段的停顿时间;
- 坏的一面是Minor GC后紧跟着一个remark pause。如此一来,停顿时间也比较久。
CMS日志如下:
7688.150: [CMS-concurrent-preclean-start]
7688.186: [CMS-concurrent-preclean: 0.034/0.035 secs]
7688.186: [CMS-concurrent-abortable-preclean-start] 7688.465: [GC 7688.465: [ParNew: 1040940K->1464K(1044544K), 0.0165840 secs] 1343593K->304365K(2093120K), 0.0167509 secs]7690.093: [CMS-concurrent-abortable-preclean: 1.012/1.907 secs] 7690.095: [GC[YG occupancy: 522484 K (1044544 K)] 7690.095: [Rescan (parallel) , 0.3665541 secs]7690.462: [weak refs processing, 0.0003850 secs] [1 CMS-remark: 302901K(1048576K)] 825385K(2093120K), 0.3670690 secs] 7688.186启动了可终止的预清理,在随后的三秒内启动了Minor GC,然后进入了Remark阶段。
实际上为了减少remark阶段的STW时间,预清理阶段会尽可能多做一些事情来减少remark停顿时间。remark的rescan阶段是多线程的,为了便于多线程扫描新生代。
3. 进行Minor GC时如果有老年代引用新生代,怎么识别?
有研究表明,在所有的引用中,老年代引用新生代这种场景不足1%。
CMS将老年代的空间分成大小为512bytes的块,card table中的每个元素对应着一个块。
并发标记时,如果某个对象的引用发生了变化,就标记该对象所在的块为 dirty card。并发预清理阶段就会重新扫描该块,将该对象引用的对象标识为可达。
当有老年代引用新生代,对应的card table被标识为相应的值(card table中是一个byte,有八位,约定好每一位的含义就可区分哪个是引用新生代,哪个是并发标记阶段修改过的。所以,Minor GC通过扫描card table就可以很快的识别老年代引用新生代。
关于CMS的JVM参数调优
第一次调优
运营一段时间后,发现CMSGC超过一秒的情况非常多,GC日志:

可以看出,在remark中的Rescan阶段耗费了1.57秒,并且这个过程是会导致应用暂停的。问题定位在了Rescan阶段。
发现在Rescan时新生代过大(4313641 K(7188480 K)),是导致Rescan慢的关键原因,如果能尽量保持新生代很小的时候就终止preclean阶段,就可以控制住在Rescan时新生代的大小。
查看JVM参数发现-XX:CMSScheduleRemarkEdenPenetration的意思是当新生代存活对象占EdenSpace的比例超过多少时,终止preclean阶段并进入remark阶段。这个参数的默认值是50%,按照现在的配置,就是7800m*50%=3900m左右,所以更改此参数设置为:-XX:CMSScheduleRemarkEdenPenetration=1。
进行压力测试,发现remark阶段的耗时确实降低了不少,说明优化有效。
第二次调优
运行几天后观察GC日志(2011-09-05),发现每隔100000秒的CMSGC的峰值情况确实大大降低了,但是还是偶尔有超过1~2秒的CMSGC情况:
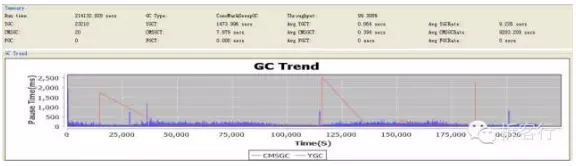
GC日志:

发现concurrent-abortable-preclean阶段超过了-XX:CMSMaxAbortablePrecleanTime设置的最大值10秒,所以强制终止了preclean阶段而进入remark阶段。而这段时间的两次ParNew之间的间隔了17秒之多。希望的是在preclean阶段产生一次MinorGC,所以将preclean的最大时长调整为30秒:-XX:CMSMaxAbortablePrecleanTime=30000。
第三次调优
运行一段时间后,发现居然出现了FullGC,大概在3~5天左右出现一次,以下是FullGC时的日志:
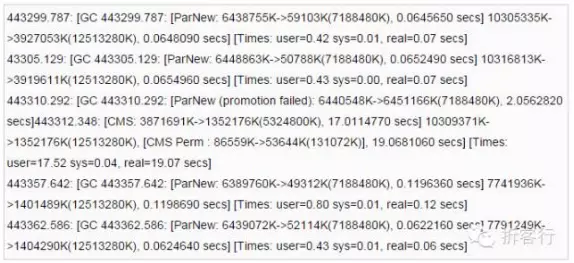
发现在443310秒有promotion failed出现(新生代晋升到老生代空间不足导致的FullGC),但是此时的OldGen可以算出还剩1.45G的空间(5324800K-3871691K=1453109K),而根据gcLogViewer的统计,每次MinorGC后平均新生代晋升到老生代的内存大小仅为58K。所以并不是OldGen空间不够,而是OldGen的连续空间不够造成的promotion failed。
换句话说,是由于OldGen在距离上次CMSGC后,又产生了大量内存碎片,当某个时间点在OldGen中的连续空间没有一块足够58K的话,就会导致的promotion failed。
考虑如果能够缩短CMSGC的周期,保证在出现promotion failed之前就进行CMSGC,就可以避免这个问题了。所以考虑将新生代空间缩小(相对来说就增加了老生代的空间),并且将CMSGC触发比率降低,同时保证Survivor空间不变。所以优化参数改动如下:
-Xmn7800m -> -Xmn7020m
-XX:SurvivorRatio=8 –> -XX:SurvivorRatio=7 -XX:CMSInitiatingOccupancyFraction=80 -> -XX:CMSInitiatingOccupancyFraction=70 第四次调优
上面的调优保持系统稳定运行了很长时间后,突然有一台机器出现大量FullGC,观察gc.log发现是由于持久带满造成的:
应对的方法为加大持久带,并让持久带也使用CMSGC方式回收:
-XX:PermSize=64m -> -XX:PermSize=200m -XX:MaxPermSize=128m -> -XX:MaxPermSize=200m -XX:+CMSClassUnloadingEnabled 引用自:https://m.aliyun.com/yunqi/articles/54413