1. Scrapy框架
1.1 Selector的用法
我们之前介绍了利用Beautiful Soup、正则表达式来提取网页数据,这确实非常方便。而Scrapy还提供了自己的数据提取方法,即Selector(选择器)。Selector 是基于lxml来构建的,支持XPath选择器、CSS选择器以及正则表达式,功能全面,解析速度和准确度非常高。
Selector是一个可以独立使用的模块。我们可以直接利用Selector这个类来构建一个选择器对象,然后调用它的相关方法如xpath()、css()等来提取数据。
案例:
from scrapy import Selector body= 'Hello World ' selector = Selector(text=body) title = selector.xpath('//title/text()').extract_first() print(title)
结果:
![]()
我们没有在Scrapy框架中运行,而是把Scrapy中的Selector单独拿出来使用了,构建的时候传入text参数,就生成了Selector选择器对象,然后就可以像前面我们所用的Scrapy中的解析方式一样,调用xpath()、css()等方法来提取。
在这里我们查找的是源代码中的title中的文本,在Path选择器最后加 text()方法就可以实现文本的提取了。
以上内容就是Selector的直接使用方式Beautiful Soup等库类似,Selector其实也是强大的网页解析库。如果方便的话,我们也可以在其他项目中直接使用Selector来提取数据。
Selector选择器的使用可以分为三步:
导入选择器from scrapy.selector import Selector
创建选择器实例selector = Selector(response=response)
使用选择器selector.xpath()或者selector.css()
不过Scrapy项目里我们可以直接response.css()或response.xpath(),怎么方便怎么用。
1.2 Spider的用法
在Scrapy中,要抓取网站的链接配置、抓取逻辑、解析逻辑里其实都是在Spider中配置的在上一章的实例中,我们发现抓取逻辑也是在Spider中完成的。
1.2.1 Spider运行流程
在实现Scrapy爬虫项目时,最核心的类便是Spider类了,它定义了如何爬取某个网站的流程和解析方式。简单来说,Spider要做的事就是两件:定义爬取网站的动作和分析爬取下来的网页。
Spider循环爬取过程:
以初始的URL初始化Request,并设置回调函数。当该Request成功请求并返回时,Response生成并作为参数传给该回调函数。
在回调函数内分析返回的网页内容。返回结果有两种形式。一种是解析到的有效结果返回字典或Item对象,它们可以经过处理后(或直接)保存。另一种是解析得到下一个(如下页)链接,可以利用此链接构造Reque并设置新的回调函数,返回Request等待后续调度。
如果返回的是字典或Item对象,我们可通过Feed Exports等组件将返回结果存入到文件。如果设置了Pipeline的话,我们可以使用Pipeline处理(如过滤、修正等)并保存。
如果返回的是Reqeust,那么Request执行成功得到Response之后,Response会被传递给Request中定义的回调函数,在回调函数中我们可以再次使用选择器来分析新得到的网页内 容,并根据分析的数据生成Item。
通过以上几步循环往复进行,我们完成了站点的爬取。
1.2.2 Spider类分析
在上一章的例子中,我们定义的Spider是继承自scrapy.spiders.Spider。scrapy.spiders.Spider这个类是最简单最基本的Spider类,其他Spider必须继承这个类。还有后面一些特殊Spider类也都继承自它。
scrapy.spiders.Spider这个类提供了start_requests()方法的默认实现,读取并请求start_urls属性,并根据返回的结果调用 parse()方法解析结果。
基础属性:
name:爬虫名称,是定义Spider名字的字符串。Spider的名字定义了Scrapy如何定位并初始化Spider,它必须是唯一的。不过我们可以生成多个相同的Spider实例,数量没有限制。name是Spider最重要的属性。如果Spider爬取单个网站,一个常见的做法是以该网站的域名名称来命名Spider。例如,Spider爬取mywebsite.com,该Spider通常会被命名为mywebsite。
allowed_domains:允许爬取的域名,是可选配置,不在此范围的链接不会被跟进爬取。
start_urls:它是起始URL列表,当我们没有实现start_requests()方法时,默认会从这个列表开始抓取。
custom_settings:它是一个字典,是专属于本Spider的配置,此设置会覆盖项目全局的设置。此设置必须在初始化前被更新,必须定义成类变量。
crawler:它是由from_crawler()方法设置的,代表的是本Spider类对应的Crawler对象。Crawler对象包含了很多项目组件,利用它我们可以获取项目的一些配置信息,如最常见的获取项目的设置信息,即Settings。
settings:它是一个Settings对象,利用它我们可以直接获取项目的全局设置变量。
除了基础属性,Spider还有一些常用的方法:
start_requests():此方法用于生成初始请求,它必须返回一个可迭代对象。此方法会默认使用start_urls里面的URL来构造Request,而且Request是GET请求方式。如果我们想在启动时以POST方式访问某个站点,可以直接重写这个方法,发送 POST请求时使用FormRequest即可。
parse():当Response没有指定回调函数时,该方法会默认被调用。它负责处理Response处理返回结果,并从巾提取处想要的数据和下一步的请求,然后返回。该方法需要返回一个包含Request或ltem的可迭代对象。
closed():当Spider关闭时,该方法会被调用,在这里一般会定义释放资源的一些操作或其他收尾操作。
1.3 Downloader Middleware的用法
Downloader Middleware即下载中间件,它是处于Scrapy的Request和Response之间的处理模块。
我们上一章已经看过Scrapy框架的架构了。
Scheduler从队列中拿出一个Request发送给Downloader执行下载,这个过程会经过Downloader Middleware的处理。另外,当Downloader将Request下载完成得到Response返回给Spider时会再次经过Downloader Middleware处理。
也就是说,Downloader Middleware在整个架构中起作用的位置有两个,分别是:
在Scheduler调度出队列的Request发送给Doanloader下载之前,也就是我们可以在Request执行下载之前对其进行修改。
在下载后生成的Response发送给Spider之前,也就是我们可以在生成Resposne被Spider解析之前对其进行修改。
Downloader Middleware的功能非常强大,修改User-Agent处理重定向、设置代理、失败重试、设置 Cookies等功能都需要借助它来实现。
1.3.1 使用说明
Scrapy其实已经提供了许多Downloader Middleware,比如负责失败重试、自动重定向等功能的Middleware,它们被DOWNLOADER_MIDDLEWARES_BASE变量所定义。
官网:https://scrapy-chs.readthedocs.io/zh_CN/0.24/topics/settings.html#std:setting-DOWNLOADER_MIDDLEWARES_BASE
DOWNLOADER_MIDDLEWARES_BASE变量的内容如下所示:

这是一个字典格式,字典的键名是Scrapy内置的Downloader Middleware的名称,键值代表了调用的优先级,优先级是一个数字,数字越小代表越靠近Scrapy引擎,数字越大代表越靠近Downloader,数字小的Downloader Middleware会被优先调用。
如果向己定义的Downloader Middleware要添加到项目里,DOWNLOADER_MIDDLEWARES_BASE变量不能直接修改。Scrapy提供了另外一个设置变量DOWNLOADER_MIDDLEWARES,我们直接修改这个变量就可以添加自己定义的DownloaderMiddleware,以及禁用DOWNLOADER_MIDDLEWARES_BASE里面定义的Downloader Middleware。
1.3.2 核心方法
Scrapy内置的Downloader Middleware为Scrapy提供了基础的功能,但在项目实战中我们往往需要单独定义Downloader Middleware。不用担心,这个过程非常简单,我们只需要实现某几个方法即可。
每个Downloader Middleware都定义了一个或多个方法的类,核心的方法有如下三个:
process_request(request,spider)
process_response(request,response,spider)
pro cess_exception(request,exception,spider)
我们只需要实现至少一个方法,就可以定义一个Downloader Middleware下面我们来看看这三个方法的详细用法。
(1) process_request(request,spider)
Request被Scrapy引擎调度给Downloader之前,process_request()方法就会被调用,也就是在Request从队列里调度出来到Downloader下载执行之前,我们都可以用process_request()方法对 Request进行处理。方法的返回值必须为None、Response对象、Request对象之一,或者抛出IgnoreRequest异常。
process_request()方法的参数有如下两个:
request,是Request对象,即被处理的Request。
spider,是Spdier对象,即此Request对应的Spider。
返回类型不同,产生的效果也不同。下面归纳一下不同的返回情况。
- 当返回是None时,Scrapy将继续处理该Request,接着执行其他Downloader Middleware的process_request()方法,一直到Downloader把Request执行后得到Response才结束。这个过程其实就是修改Request的过程,不同的Downloader Middleware按照设置的优先级顺序依次对Request进行修改,最后送至Downloader执行。
- 当返回为Response对象时,更低优先级的Downloader Middleware的process_request()和process_exception()方法就不会被继续调用,每个Downloader Middleware的process_response()方法转而被依次调用。调用完毕之后,直接将Response对象发送给Spider来处理。
- 当返回为Request对象时,更低优先级的Downloader Middleware的process_request()方法会停止执行。这个Request会重新放到调度队列里,其实它就是一个全新的Request,等待被调度。如果被Scheduler调度了,那么所有的Downloader Middleware的process_request()方法会被重新按照顺序执行。
- 如果IgnoreRequest异常抛出,则所有的Downloader Middleware的process_exception()方法会依次执行。如果没有一个方法处理这个异常,那么Request的errorback()方法就会回调。如果该异常还没有被处理,那么它便会被忽略。
(2) process_response (request, response,spider)
Downloader执行Request下载之后,会得到对应的Response。Scrapy引擎便会将Response发送给 Spider进行解析。在发送之前,我们都可以用process_response()方法来对Response进行处理。方法的返回值必须为Request对象、Response对象之一,或者抛出IgnoreRequest异常。
process_response()方法的参数有如下三个:
request,是Request对象,即此Response对应的Request。
response,是Response对象,即此被处理的Response。
spider,是Spider对象,即此Response对应的Spider。
下面归纳下不同的返回情况。
- 当返回为Request对象时,更低优先级的Downloader Middleware的process_response()方法不会继续调用。该Request对象会重新放到调度队列里等待被调度,它相当于一个全新的Request。然后,该Request会被process_request()方法依次处理。
- 当返回为Response对象时,更低优先级的Downloader Middleware的process_response()方法会继续调用,继续对该Response对象进行处理。
- 如果IgnoreRequest异常抛出,则Request的errorback()方法会回调。如果该异常还没有被处理,那么它便会被忽略。
(3) process_exception(request,exception,spider)
当Downloader或process_request()方法抛出异常时,例如抛出IgnoreRequest异常,process_exception()方法就会被调用。方法的返回值必须为None、Response对象、Request对象之一。
process_exception()方法的参数有如下:
request,是Request对象,即产生异常的Request。
exception,是Exception对象,即抛出的异常。
spdier,是Spider对象,即Request对应的Spider。
下面归纳一下不同的返回情况。
- 当返回为None时,更低优先级的Downloader Middleware的process_exception()会被继续依次调用,直到所有的方法都被调度完毕。
- 当返回为Response对象时,更低优先级的Downloader Middleware的process_exception()方法不再被继续调用,每个Downloader Middleware的process_response()方法转而被依次调用。
- 当返回为Request对象时,更低优先级的Downloader Middleware的process_exception()也不再被继续调用,该Request对象会重新放到调度队列里面等待被调度,它相当于一个全新的Request。然后,该Request又会被process_request()方法依次处理。
以上内容便是这三个方法的详细使用逻辑。在使用它们之前,请先对这三个方法的返回值的处理情况有一个清晰的认识。在自定义Downloader Middleware的时候,也一定要注意每个方法的返回类型。
1.3.3 项目实战
新建一个项目。
scrapy startproject scrapydownloadertest
新建了一个Scrapy项目,名为scrapydownloadertest。进入项目,新建一个Spider。
scrapy genspider httpbin httpbin.org
新建了一个Spider,名为httpbin。
# -*- coding: utf-8 -*- import scrapy class HttpbinSpider(scrapy.Spider): name = 'httpbin' allowed_domains = ['httpbin.org'] start_urls = ['http://httpbin.org/'] def parse(self, response): pass
接下来我们修改start_urls,将parse()方法添加一行日志输出,将response变量的text属性输出出来,这样我们便可以看到Scrapy发送的Request信息了。
修改Spider内容如下:
# -*- coding: utf-8 -*- import scrapy class HttpbinSpider(scrapy.Spider): name = 'httpbin' allowed_domains = ['httpbin.org'] start_urls = ['http://httpbin.org/get'] def parse(self, response): self.logger.debug(response.text)
接下来运行此Spider。
scrapy crawl httpbin
Scrapy运行结果包含Scrapy发送的Request信息,内容如下:
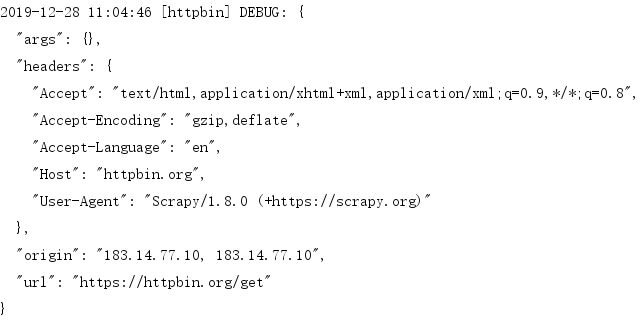
我们观察一下Headers,Scrapy发送的Request使用的User-Agent是Scrapy/1.8.0(+http: //scrapy.org),这其实是由Scrapy内置的UserAgentMiddleware设置的,UserAgentMiddleware的源码如下:
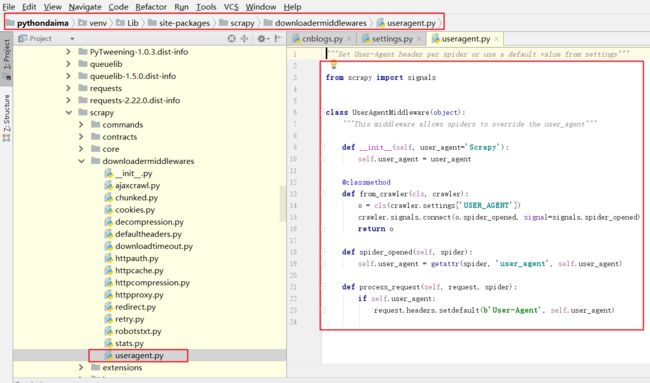
在from_crawler()方法中,首先尝试获取settings里面USER_AGENT,然后把USER_AGENT传递给__init__()方法进行初始化,其参数就是user_agent。如果没有传递USER_AGENT参数就是默认设置为Scrapy字符串。我们新建的项目没有设置USER_AGENT,所以这里的user_agent变量就是Scrapy。接下来,在process_request()方法中,将user-agent变量设置为headers变量的一个属性,这样就成功设置了User-Agent。因此,User-Agent就是通过此Downloader Middleware的process_request()方法设置的。
修改请求时的User-Agent可以有两种方式:一是修改settings里面的USER_AGENT变量;二是通过Downloader Middleware的process_request()方法来修改。
第一种方法非常简单,我们只需要在setting.py里面加一行USER_AGENT的定义即可:
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'
一般推荐使用这种方法来设置。但是如果想设置得更加灵活,比如设置随机的User-Agent的设置。
第二种方法,在middlewares.py里添加一个RandomUserAgentMiddleware的类。
import random class RandomUserAgentMiddlerware(): def __init__(self): self.user_agents = [ #放几个User-Agent在里面 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36', 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36', 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3100.0 Safari/537.36' ] def process_request(self,request,spider): request.headers['User-Agent'] = random.choice(self.user_agents)
我们首先在类的__init__()方法中定义几个不同的User-Agent,并用一个列表来表示。接下来实现了process_request()方法,它有一个参数request,我们直接修改request的属性即可。在这里我们直接设置了request变量的headers属性的User-Agent,设置内容是随机选择的User-Agent,这样一个Downloader Middleware就写好了。
不过,要使之生效我们还需要再去调用这个Downloader Middleware。在settings.py中,将DOWNLOADER_MIDDLEWARES取消注释,并设置成如下内容:
DOWNLOADER_MIDDLEWARES = { 'scrapydownloadertest.middlewares.RandomUserAgentMiddleware':543 }
然后重新运行Spider,就可以看到User-Agent被成功修改为列表中所定义的随机的一个User-Agent了。
我们就通过实现Downloader Middleware并利用process_request()方法成功设置了随机的User-Agent。
另外,Downloader Middleware还有process_response()方法。Downloader对Request执行下载之后会得到Response,随后Scrapy引擎会将Response发送回Spider进行处理。但是在Response被发送给Spider之前,我们同样可以使用process_response()方法对Response进行处理。比如这里修改一下Response的状态码,在RandomUserAgentMiddleware添加如下代码:
def process_response(self,request,response,spider): response.status = 201 return response
我们将response变量的status属性修改为201,随后将response返回,这个被修改后的Response就会被发送到Spider。
我们再在Spider里面输出修改后的状态码,在parse()方法中添加如下的输出语句:
self.logger.debug('Status Code :' + str(response.status))
重新运行之后,控制台输出了如下内容:
[httpbin] DEBUG: Status Code: 201
可以发现,Response的状态码成功修改了。
因此要想对Response进行后处理,就可以借助于process_response()方法。
另外还有一个process_exception()方法,它是用来处理异常的方法。如果需要异常处理的话,我们可以调用此方法。不过这个方法的使用频率相对低一些,这里就不谈了。