YARN产生背景
MRv1的局限
YARN是在MRv1基础上演化而来的,它克服了MRv1中的各种局限性。在正式介绍YARN之前,先了解下MRv1的一些局限性,主要有以下几个方面:
- 扩展性差。在MRv1中,JobTracker同时兼备了资源管理和作业控制两个功能,这成为系统的一个最大瓶颈,严重制约了Hadoop集群扩展性。
- 可靠性差。MRv1采用了master/slave结构,其中,master存在单点故障问题,一旦它出现故障将导致整个集群不可用。
- 资源利用率低。MRv1采用了基于槽位的资源分配模型,槽位是一种粗粒度的资源划分单位,通常一个任务不会用完槽位对应的资源,且其他任务也无法使用这些空闲资源。此外,Hadoop将槽位分为Map Slot和Reduce Slot两种,且不允许它们之间共享,常常会导致一种槽位资源紧张而另外一种闲置(比如一个作业刚刚提交时,只会运行Map Task,此时Reduce Slot闲置)。
- 无法支持多种计算框架。随着互联网高速发展,MapReduce这种基于磁盘的离线计算框架已经不能满足应用要求,从而出现了一些新的计算框架,包括内存计算框架、流式计算框架和迭代式计算框架等,而MRv1不能支持多种计算框架并存。
为了克服以上几个缺点,Apache开始尝试对Hadoop进行升级改造,进而诞生了更加先进的下一代MapReduce计算框架MRv2。正是由于MRv2将资源管理功能抽象成了一个独立的通用系统YARN,直接导致下一代MapReduce的核心从单一的计算框架MapReduce转移为通用的资源管理系统YARN。
集群资源统一管理
随着互联网的高速发展,新的计算框架不断出现,从支持离线处理的MapReduce,到支持在线处理的Storm,从迭代式计算框架Spark到流式处理框架S4,各种框架各有所长,各自解决了某一类应用问题。这时候就需要一个组件对同一个集群上的不同计算框架进行资源的统一管理。
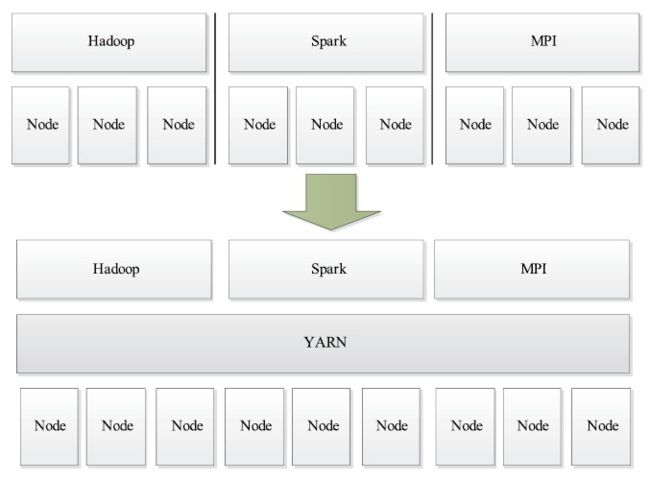
相比于“一种计算框架一个集群”的模式,共享集群的模式存在多种好处:
- 资源利用率高。如果每个框架一个集群,可能在某段时间内,有些计算框架的集群资源紧张,而另外一些集群资源空闲。共享集群模式则通过多种框架共享资源,使得集群中的资源得到更加充分的利用。
- 运维成本低。如果采用“一个框架一个集群”的模式,则可能需要多个管理员管理这些集群,进而增加运维成本,而共享模式通常需要少数管理员即可完成多个框架的统一管理。
- 数据共享。随着数据量的暴增,跨集群间的数据移动不仅需花费更长的时间,且硬件成本也会大大增加,而共享集群模式可让多种框架共享数据和硬件资源,将大大减小数据移动带来的成本。
YARN基本设计思想
MRv1主要由编程模型、数据处理引擎(由Map Task和Reduce Task组成)和运行时环境三部分组成。为了保证编程模型的向后兼容性,MRv2重用了MRv1中的编程模型和数据处理引擎,但运行时环境被完全重写。
MRv1的运行时环境主要由两类服务组成,分别是JobTracker和TaskTracker。其中,JobTracker负责资源管理和作业控制。TaskTracker负责单个节点的资源管理和任务执行。
MRv1将资源管理和应用程序管理两部分混杂在一起,使得它在扩展性、容错性和多框架支持等方面存在明显缺陷。
而MRv2则通过将资源管理和应用程序管理两部分剥离开,分别由ResourceManager和ApplicationMaster负责,其中ResourceManager专管资源管理和调度,而ApplicationMaster则负责与具体应用程序相关的任务切分、任务调度和容错等,具体如下图所示。

YARN基本架构
YARN是Hadoop 2.0中的资源管理系统,它的基本设计思想是将MRv1中的JobTracker拆分成了两个独立的服务:一个全局的资源管理器ResourceManager和每个应用程序特有的ApplicationMaster。其中ResourceManager负责整个系统的资源管理和分配,而ApplicationMaster负责单个应用程序的管理。
YARN总体上仍然是Master/Slave结构,在整个资源管理框架中,ResourceManager为Master,NodeManager为Slave,ResourceManager负责对各个NodeManager上的资源进行统一管理和调度。当用户提交一个应用程序时,需要提供一个用以跟踪和管理这个程序的ApplicationMaster,它负责向ResourceManager申请资源,并要求NodeManger启动可以占用一定资源的任务。由于不同的ApplicationMaster被分布到不同的节点上,因此它们之间不会相互影响。
下图描述了YARN的基本组成结构,YARN主要由ResourceManager、NodeManager、ApplicationMaster(图中给出了MapReduce和MPI两种计算框架的ApplicationMaster,分别为MR AppMstr和MPI AppMstr)和Container等几个组件构成。

接下来对YARN里几个重要的组件一一介绍。
1. ResourceManager(RM)
RM是一个全局的资源管理器,负责整个系统的资源管理和分配。它主要由两个组件构成:调度器(Scheduler)和应用程序管理器(Applications Manager,ASM)。
(1)调度器(分配Container)
调度器根据容量、队列等限制条件(如每个队列分配一定的资源,最多执行一定数量的作业等),将系统中的资源分配给各个正在运行的应用程序。需要注意的是,该调度器是一个“纯调度器”,它不再从事任何与具体应用程序相关的工作,比如不负责监控或者跟踪应用的执行状态等,也不负责重新启动因应用执行失败或者硬件故障而产生的失败任务,这些均交由应用程序相关的ApplicationMaster完成。调度器仅根据各个应用程序的资源需求进行资源分配,而资源分配单位用一个抽象概念“资源容器”(Resource Container,简称Container)表示,Container是一个动态资源分配单位,它将内存、CPU、磁盘、网络等资源封装在一起,从而限定每个任务使用的资源量。此外,该调度器是一个可插拔的组件,用户可根据自己的需要设计新的调度器,YARN提供了多种直接可用的调度器,比如Fair Scheduler和Capacity Scheduler等。
(2)应用程序管理器
应用程序管理器负责管理整个系统中所有应用程序,包括应用程序提交、与调度器协商资源以启动ApplicationMaster、监控ApplicationMaster运行状态并在失败时重新启动它等。
2. ApplicationMaster(AM)
用户提交的每个应用程序均包含一个AM,主要功能包括:
- 与RM调度器协商以获取资源(以Container表示)
- 将得到的任务进一步分配给内部的任务
- 与NM通信以启动/停止任务
- 监控所有任务运行状态,并在任务失败时重新为任务申请资源以重启任务
3. NodeManager(NM)
NM是每个节点上的资源和任务管理器。一方面,它定时地向RM汇报本节点的资源使用情况和Container运行状态;另一方面,它接受并处理来自AM的Container启动/停止等各种请求。
4. Container
Container是YARN中的资源抽象,它封装了某个节点上的多维资源,如CPU、内存、磁盘、网络等。当AM向RM申请资源时,RM向AM返回的资源便是用Container表示的。YARN会为每个任务分配一个Container,且该任务只能使用该Container中描述的资源。Container是一个动态资源划分单位,是根据应用程序的需求自动生成的。目前,YARN仅支持CPU和内存两种资源。
YARN工作流程
运行在YARN上的应用程序主要分为两类:短应用程序和长应用程序。其中,短应用程序是指一定时间内可运行完成并正常退出的应用程序,如MapReduce作业、Spark DAG作业等。长应用程序是指不出意外,永不终止运行的应用程序,通常是一些服务,比如Storm Service(包括Nimbus和Supervisor两类服务),HBase Service(包括HMaster和RegionServer两类服务)等,而它们本身作为一种框架提供编程接口供用户使用。尽管这两类应用程序作业不同,一类直接运行数据处理程序,一类用于部署服务(服务之上再运行数据处理程序),但运行在YARN上的流程是相同的。
当用户向YARN中提交一个应用程序后,YARN将分两个阶段运行该应用程序:第一阶段是启动ApplicationMaster。第二阶段是由ApplicationMaster创建应用程序,为它申请资源,并监控它的整个运行过程,直到运行完成。具体如下:
- 用户向YARN中提交应用程序,其中包括ApplicationMaster程序、启动ApplicationMaster的命令、用户程序等。
- ResourceManager为该应用程序分配第一个Container,并与对应的NodeManager通信,要求它在这个Container中启动应用程序的ApplicationMaster。
- ApplicationMaster首先向ResourceManager注册,这样用户就可以直接通过ResourceManager查看应用程序的运行状态,然后它将为各个任务申请资源,并监控它的运行状态,直到运行结束,即重复步骤4~7。
- ApplicationMaster采用轮询的方式通过RPC协议向ResourceManager申请和领取资源。
- 一旦ApplicationMaster申请到资源后,便与对应的NodeManager通信,要求它启动任务。
- NodeManager为任务设置好运行环境(包括环境变量、JAR包、二进制程序等)后,将任务启动命令写到一个脚本中,并通过运行该脚本启动任务。
- 各个任务通过某个RPC协议向ApplicationMaster汇报自己的状态和进度,以让ApplicationMaster随时掌握各个任务的运行状态,从而可以在任务失败时重新启动任务。
- 应用程序运行完成后,ApplicationMaster向ResourceManager注销并关闭自己。


欢迎关注公众号: FullStackPlan 获取更多干货哦~