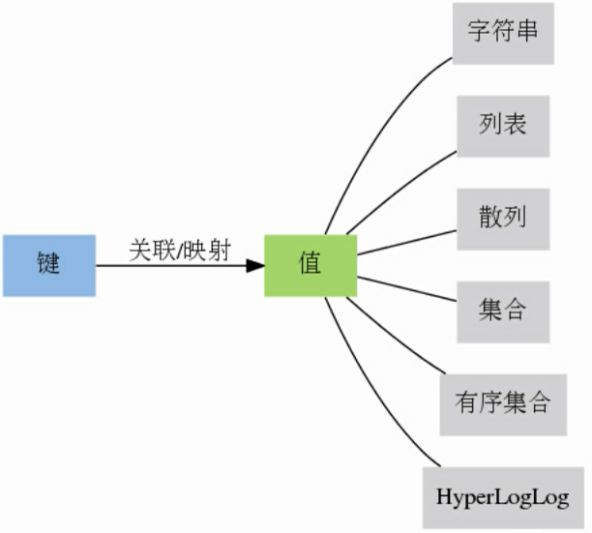
Redis key 值是二进制安全的,这意味着可以用任何二进制序列作为key值,从形如”foo”的简单字符串到一个JPEG文件的内容都可以。空字符串也是有效key值。
Key取值原则:
1、键值不需要太长,消耗内存,且在数据中查找这类键值的计算成本较高
2、键值不宜过短,可读性较差
字符串
字符串是一种最基本的Redis值类型。Redis字符串是二进制安全的,这意味着一个Redis字符串能包含任意类型的数据。
例如: 一张JPEG格式的图片或者一个序列化的java对象
一个字符串类型的值最多能存储512M字节的内容
String命令
设置字符串值 set get
SET key value [EX seconds] [PX milliseconds] [NX|XX]
EX 设置过期时间,秒,等同于SETEX key seconds value
PX 设置过期时间,毫秒,等同于PSETEX key milliseconds value
NX 键不存在,才能设置,等同于SETNX key value
XX 键存在时,才能设置设置多个键的字符串值
MSET key value [key value ...]键不存在时,设置字符串值
MSETNX key value [key value ...]
注意:这是原子操作
set s1 abc
set s2 12
set se abc ex 15
mset s3 3 s4 4 s5 5
msetnx s5 A5 s6 6
过期
Redis中可以给Key设置一个生存时间(秒或毫秒),当达到这个时长后,这些键值将会被自动删除设置多少秒或者毫秒后过期
EXPIRE key seconds
get key
set key val ex 10
PEXPIRE key milliseconds设置在指定Unix时间戳过期
EXPIREAT key timestamp
PEXPIREAT key milliseconds-timestamp删除过期
PERSIST key生存时间
Time To Live,Key的剩余生存时间查看剩余生存时间
TTL key
PTTL key
key存在但没有设置TTL,返回-1
key存在,但还在生存期内,返回剩余的秒或者毫秒
key曾经存在,但已经消亡,返回-2(2.8版本之前返回-1)
set se abc ex 15
ttl s6
expire s6 60
pttl s6
persist s6
pttl s6
EXPIREAT cache 1355292000
PEXPIREAT mykey 1555555555005
获取值
GET key获取多个给定的键的值
MGET key [key ...]返回旧值并设置新值
GETSET key value
如果键不存在,就创建并赋值字符串长度
STRLEN key查找键
KEYS patternpattern取值
* 任意长度字符
? 任意一个字符
[] 字符集合,表示可以是集合中的任意一个
keys s*
keys s?
keys s[13]
keys *
keys ??
- 键类型
TYPE key
object encoding key
key:- v:(K1)
- type:string
- enco..(raw/int)
- strlen:2
- 指针 value地址
encoding,strlen:增删改:更新 查询长度,还是数值计算,成本很高
键是否存在
EXISTS key键重命名
RENAME key newkey
RENAMENX key newkey键删除
DEL key [key ...]追加字符串
APPEND key value
如果键存在就追加;如果不存在就等同于SET key value获取子字符串 索引
GETRANGE key start end
索引值从0开始,负数表示从字符串右边向左数起,-1表示最有一个字符

- 覆盖字符串
SETRANGE key offset value
APPEND s6 123
getrange s1 1 2
getrange s1 0 -1
getrange s1 -2 -1
getrange s1 0 10000
SETRANGE s6 3 e
SETRANGE s6 3 efghijk
SETRANGE newkey 5 hello
SETRANGE s6 3 efghijk
步长1的增减
INCR key
DECR key
字符串值会被解释成64位有符号的十进制整数来操作,结果依然转成字符串步长增减 float
INCRBY key decrement
DECRBY key decrement
字符串值会被解释成64位有符号的十进制整数来操作,结果依然转成字符串
位图bitmap 【字节数组】

位图不是真正的数据类型,它是定义在字符串类型中
一个字符串类型的值最多能存储512M字节的内容
位上限:2^(9+10+10+3) = 2^32b
获取数据出现乱码时,转换乱码命令:
redis-cli --raw 退出客户端,重新登录。
设置某一位上的值
SETBIT key offset value (0/1)
offset偏移量,从0开始获取某一位上的值
GETBIT key offset返回指定值0或者1在指定区间上第一次出现的位置偏移量
BITPOS key bit [start] [end]
bitpos k1 1 1 1
k2: 0 1 0 0 0 0 1 0 0 1 0 0 0 0 0 0
k3: 0 1 0 0 0 0 1 0
0 1 0 1 0 0 0 1 0 1 0 0 0 0 1 0
setbit k1 1 1
set str1 ab
setbit str1 6 1
setbit str1 7 0
get str1
这个结果是什么?
- 统计指定位区间上值为1的个数 字节
BITCOUNT key [start] [end]> start end Byte的索引 正负方向
set k ab
bitcount k 1 1
从左向右从0开始,从右向左从-1开始,注意官方start、end是位,测试后是字节
BITCOUNT testkey 0 0表示从索引为0个字节到索引为0个字节,就是第一个字节的统计
BITCOUNT testkey 0 -1等同于BITCOUNT testkey
最常用的就是 BITCOUNT testkey
- 位操作
0 1 0 0 0 0 0 1
1 1 1 0 0 0 0 1
0 1 0 0 0 0 0 1
对一个或多个保存二进制位的字符串 key 进行位元操作,并将结果保存到 destkey 上,operation 可以是 AND 、 OR 、 NOT 、 XOR 这四种操作中的任意一种:
BITOP AND destkey key [key ...] ,对一个或多个 key 求逻辑并,并将结果保存到 destkey;
BITOP OR destkey key [key ...] ,对一个或多个 key 求逻辑或,并将结果保存到 destkey;
BITOP XOR destkey key [key ...] ,对一个或多个 key 求逻辑异或,并将结果保存到 destkey;
BITOP NOT destkey key ,对给定 key 求逻辑非,并将结果保存到 destkey。
除了 NOT 操作之外,其他操作都可以接受一个或多个 key 作为输入
当 BITOP 处理不同长度的字符串时,较短的那个字符串所缺少的部分会被看作 0
空的 key 也被看作是包含 0 的字符串序列
思考:a位或b是什么?
- Redis的二进制位
set s1 ab
bitcount s1
bitcount s1 0 0
bitcount s1 1 1
set ch 中
bitcount ch
bitcount ch 2 2



网站用户的上线次数统计(活跃用户)
用户ID为key,天作为offset,上线置为1 366> 000000000000000
366 /8 50Byte 16 50
key: sean value: 11 1 000000000000000001010000000000000000
ID为500的用户,今年的第1天上线、第30天上线
SETBIT u500 1 1 1 0 0 000 0 …….1 0 00 0 > 365 /8 46 Byte
SETBIT u500 30 1
BITCOUNT sean 0 -1
KYES u*按天统计网站活跃用户
天作为key,用户ID为offset,上线置为1
求一段时间内活跃用户数 500 / 8 366 * 63Byte
SETBIT 20160601 15 1 1 1 0 1 00 00 00 0 00 00 0
SETBIT 20160603 123 1 0 1 0 0 00 00 01 0 00 00 0
SETBIT 20160606 123 1 0 1 0 0 00 00 01 0 00 00 0
求6月1日到6月10日的活跃用户
BITOP OR aaa 20160601 20160602 20160603 20160610
BITCOUNT aaa 0 -1
结果为2
登录不同的库
redis-cli --help
redis-cli -n 2
清除当前库数据
FLUSHDB
清除所有库中的数据
FLUSHALL
列表 (List列表 数组)
基于Linked List实现;
元素是字符串类型;
列表头尾增删快,中间增删慢,增删元素是常态;
元素可以重复出现;
最多包含2^32-1元素.
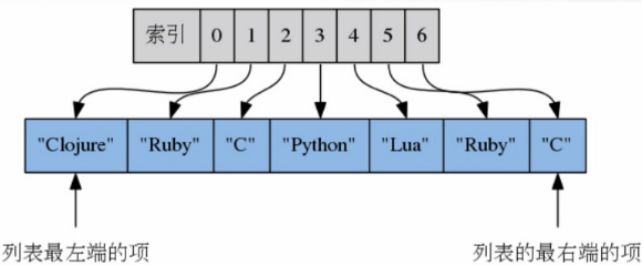
列表的索引
从左至右,从0开始
从右至左,从-1开始

list
队列:L/R R/L
栈: L/L R/R
数组:LINDEX LSET
阻塞:BL BR命令说明
B block 块,阻塞
L left 左
R right 右
X exist 存在左右或者头尾压入元素 string set key “abc”
LPUSH key value [value ...]
LPUSHX key value
RPUSH key value [value ...]
RPUSHX key value左右或者头尾弹出元素
LPOP key
RPOP key从一个列表尾部弹出元素压入到另一个列表的头部 string getset
RPOPLPUSH source destination返回列表中指定范围元素
LRANGE key start stop
LRANGE key 0 -1 表示返回所有元素获取指定位置的元素
LINDEX key index设置指定位置元素的值
LSET key index value列表长度,元素个数 string strlen
LLEN key LRANGE KEY 0 -1从列表头部开始删除值等于value的元素count次,LIST 可以重复出现
LREM key count value
count > 0 : 从表头开始向表尾搜索,移除与 value 相等的元素,数量为 count
count < 0 : 从表尾开始向表头搜索,移除与 value 相等的元素,数量为 count 的绝对值
count = 0 : 移除表中所有与 value 相等的值
举例
RPUSH listkey c abc c ab 123 ab bj ab redis list
LREM listkey 2 ab
LRANGE listkey 0 -1

- 去除指定范围 外 元素
LTRIM key start stop
举例
RPUSH listkey c abc c ab 123 ab bj ab redis list
LTRIM listkey 0 -1
LTRIM listkey 1 -1
LTRIM listkey 1 10000
微博的评论最后500条
LTRIM u1234:forumid:comments 0 499
- 在列表中某个存在的值(pivot)前或后插入元素
LINSERT key BEFORE|AFTER pivot value
key和pivot不存在,不进行任何操作
举例
RPUSH lst Clojure C Lua
LINSERT lst AFTER C Python
LINSERT lst BEFORE C Ruby
阻塞
如果弹出的列表不存在或者为空,就会阻塞
超时时间设置为0,就是永久阻塞,直到有数据可以弹出
如果多个客户端阻塞在同一个列表上,使用First In First Service原则,先到先服务左右或者头尾阻塞弹出元素
BLPOP key [key ...] timeout
BRPOP key [key ...] timeout从一个列表尾部阻塞弹出元素压入到另一个列表的头部
BRPOPLPUSH source destination timeout
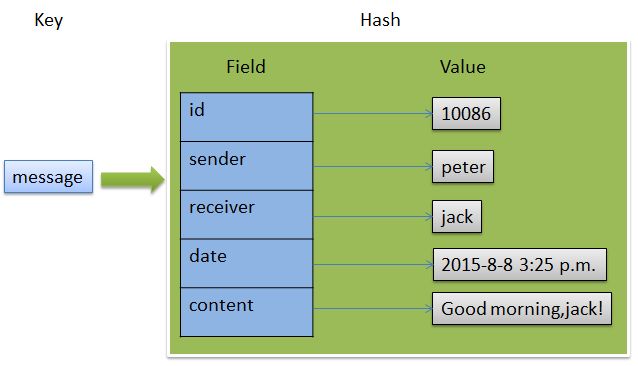
Hash散列
由field和关联的value组成的map键值对;
field和value是字符串类型;
一个hash中最多包含2^32-1键值对。
Hash命令
设置单个字段
HSET key field value
HSETNX key field value (key的filed不存在的情况下执行,key不存在直接创建)设置多个字段
HMSET key field value [field value ...]返回字段个数
HLEN key判断字段是否存在
HEXISTS key field
key或者field不存在,返回0返回字段值
HGET key field返回多个字段值
HMGET key field [field ...]返回所有的键值对
HGETALL key返回所有字段名
HKEYS key返回所有值
HVALS key在字段对应的值上进行整数的增量计算
HINCRBY key field increment在字段对应的值上进行浮点数的增量计算
HINCRBYFLOAT key field increment删除指定的字段
HDEL key field [field ...]
举例
HINCRBY numbers x 100
HINCRBY numbers x -50
HINCRBYFLOAT numbers x 3.14
HDEL numbers x
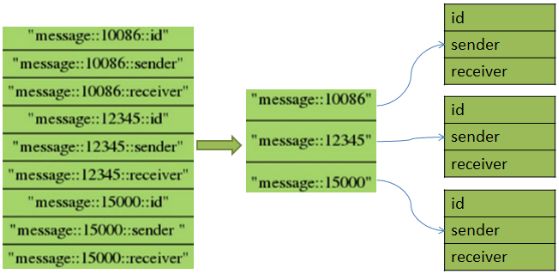
Hash用途
1.节约内存空间;
2.每创建一个键,它都会为这个键储存一些附加的管理信息(比如这个键的类型,这个键最后一次被访问的时间等等);
3.所以数据库里面的键越多,redis数据库服务器在储存附加管理信息方面耗费的内存就越多,花在管理数据库键上的CPU也会越多在字段对应的值上进行浮点数的增量计算。
-
不适合hash的情况
- 使用二进制位操作命令:因为Redis目前支持对字符串键进行SETBIT、GETBIT、BITOP等操作,如果你想使用这些操作,那么只能使用字符串键,虽然散列也能保存二进制数据
- 使用过期键功能:Redis的键过期功能目前只能对键进行过期操作,而不能对散列的字段进行过期操作,因此如果你要对键值对数据使用过期功能的话,那么只能把键值对储存在字符串里面
微博的好友关注
用户ID为key,Field为好友ID,Value为关注时间
user:1000 user:606 20150808
xz pl 2011 zs 1949用户维度统计
统计数包括:关注数、粉丝数、喜欢商品数、发帖数
用户为Key,不同维度为Field,Value为统计数
比如关注了5人
HSET user:100000 follow 5
HINCRBY user:100000 follow 1
Set集合
无序的、去重的;
元素是字符串类型;
最多包含2^32-1元素。
Set命令
- 增加一个或多个元素
SADD key member [member ...]
如果元素已经存在,则自动忽略
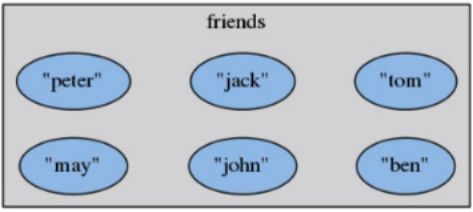
举例
SADD friends peter
SADD friends jack tom john
SADD friends may tom
- 移除一个或者多个元素
SREM key member [member ...]
元素不存在,自动忽略
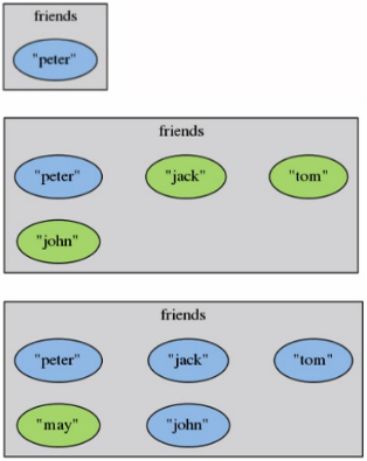
举例
SREM friends peter
SREM friends tom john

返回集合包含的所有元素
SMEMBERS key
如果集合元素过多,例如百万个,需要遍历,可能会造成服务器阻塞,生产环境应避免使用检查给定元素是否存在于集合中
SISMEMBER key member集合的无序性
SADD friendsnew "peter" "jack" "tom" "john" "may" "ben"
SADD anotherfriends "peter" "jack" "tom" "john" "may" "ben"
SMEMBERS friends
SMEMBERS anotherfriends
注意, SMEMBERS 有可能返回不同的结果,所以,如果需要存储有序且不重复的数据使用有序集合,存储有序可重复的使用列表随机返回集合中指定个数的
SRANDMEMBER key [count]
如果 count 为正数,且小于集合基数,那么命令返回一个包含 count 个元素的数组,数组中的元素各不相同。如果 count 大于等于集合基数,那么返回整个集合 最多返回整个集合 conut>=0
如果 count 为负数,那么命令返回一个数组,数组中的元素可能会重复出现多次,而数组的长度为 count 的绝对值 count < 0 长度为count绝对值,元素可能重复
如果 count 为 0,返回空
如果 count 不指定,随机返回一个元素
举例
SADD friend "peter" "jack" "tom" "john" "may" "ben"
SRANDMEMBER friends 3
SRANDMEMBER friends -5
返回集合中元素的个数
SCARD key
键的结果会保存信息,集合长度就记录在里面,所以不需要遍历随机从集合中移除并返回这个被移除的元素
SPOP key把元素从源集合移动到目标集合
SMOVE source destination member差集
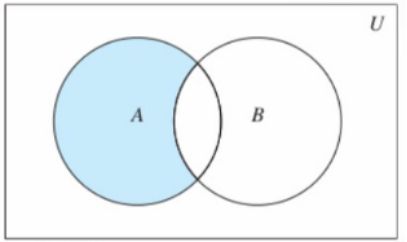
SDIFF key [key ...],从第一个key的集合中去除其他集合和自己的交集部分
SDIFFSTORE destination key [key ...],将差集结果存储在目标key中
举例
SADD number1 123 456 789
SADD number2 123 456 999
SDIFF number1 number2
- 交集
SINTER key [key ...],取所有集合交集部分
SINTERSTORE destination key [key ...],将交集结果存储在目标key中
举例
SADD number1 123 456 789
SADD number2 123 456 999
SINTER number1 number2
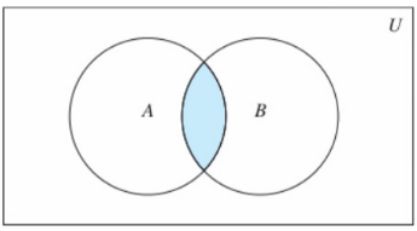
- 并集
SUNION key [key ...],取所有集合并集
SUNIONSTORE destination key [key ...],将并集结果存储在目标key中
举例
SADD number1 123 456 789
SADD number2 123 456 999
SUNION number1 number2
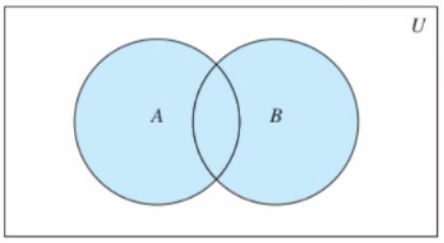
新浪微博的共同关注
需求:当用户访问另一个用户的时候,会显示出两个用户共同关注哪些相同的用户
设计:将每个用户关注的用户放在集合中,求交集即可
实现如下:
peter={'john','jack','may'}
ben={'john','jack','tom'}
那么peter和ben的共同关注为:
SINTER peter ben 结果为 {'john','jack'}
SortedSet有序集合
类似Set集合;
有序的、去重的;
元素是字符串类型;
每一个元素都关联着一个浮点数分值(Score),并按照分值从小到大的顺序排列集合中的元素。分值可以相同;
最多包含2^32-1元素。



SortedSet命令
- 增加一个或多个元素
ZADD key score member [score member ...]
如果元素已经存在,则使用新的score
举例
ZADD fruits 3.2 香蕉
ZADD fruits 2.0 西瓜
ZADD fruits 4.0 番石榴 7.0 梨 6.8 芒果

- 移除一个或者多个元素
ZREM key member [member ...]
元素不存在,自动忽略
举例
ZREM fruits 番石榴 梨 芒果
ZREM fruits 西瓜
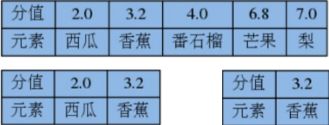
- 显示分值
ZSCORE key member
举例
ZSCORE fruits 芒果
ZSCORE fruits 西瓜
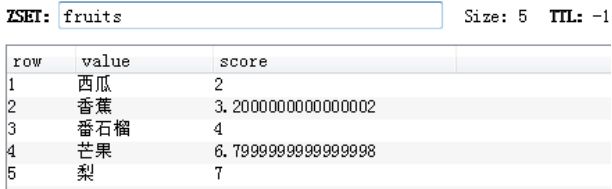
计算机并不能精确表达每一个浮点数,都是一种近似表达
- 增加或者减少分值
ZINCRBY key increment member
increment为负数就是减少
举例
ZINCRBY fruits 1.5 西瓜
ZINCRBY fruits -0.8 香蕉
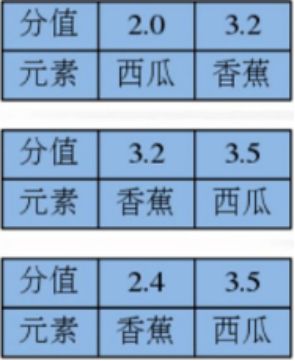
- 返回元素的排名(索引)
ZRANK key member
元素 分值 索引
举例
ZRANK fruits 西瓜
ZRANK fruits 番石榴
ZRANK fruits 芒果

- 返回元素的逆序排名
ZREVRANK key member
举例
ZREVRANK fruits 西瓜
ZREVRANK fruits 番石榴
ZREVRANK fruits 芒果
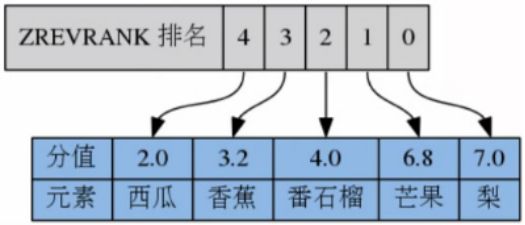
- 返回指定索引区间元素
ZRANGE key start stop [WITHSCORES]
如果score相同,则按照字典序lexicographical order 排列
默认按照score从小到大,如果需要score从大到小排列,使用ZREVRANGE
正负方向 0 -1
举例
ZRANGE fruits 0 2
ZRANGE fruits -5 -4
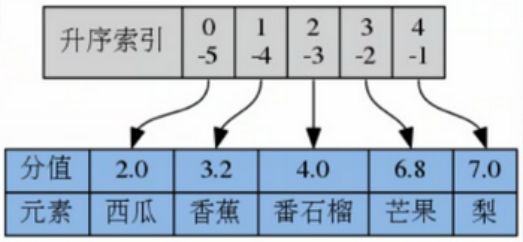
- 返回指定索引区间元素
ZREVRANGE key start stop [WITHSCORES]
如果score相同,则按照字典序lexicographical order 的 逆序 排列
默认按照score从大到小,如果需要score从小到大排列,使用ZRANGE
举例
ZREVRANGE fruits 0 2
ZREVRANGE fruits -5 -4

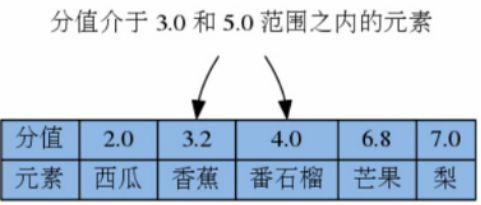
- 返回指定分值区间元素
ZRANGEBYSCORE key min max [WITHSCORES] [LIMIT offset count]
返回score默认属于[min,max]之间,元素按照score升序排列,score相同字典序
LIMIT中offset代表跳过多少个元素,count是返回几个。类似于Mysql
使用小括号,修改区间为开区间,例如(5、(10、5)
-inf和+inf表示负无穷和正无穷
举例
ZRANGEBYSCORE fruits 4.0 7.0
ZRANGEBYSCORE fruits (4 7
ZRANGEBYSCORE fruits -inf +inf

- 返回指定分值区间元素
ZREVRANGEBYSCORE key min max [WITHSCORES] [LIMIT offset count]
返回score默认属于[min,max]之间,元素按照score降序排列,score相同字典降序
LIMIT中offset代表跳过多少个元素,count是返回几个。类似于Mysql
使用小括号,修改区间为开区间,例如(5、(10、5)
-inf和+inf表示负无穷和正无穷
举例
ZREVRANGEBYSCORE fruits 7.0 4.0
ZRANGEBYSCORE fruits 7 (4
ZRANGEBYSCORE fruits +inf -inf

- 移除指定排名范围的元素
ZREMRANGEBYRANK key start stop
举例
ZREMRANGEBYRANK fruits 0 2
ZRANGE fruits 0 -1

- 移除指定分值范围的元素
ZREMRANGEBYSCORE key min max
举例
ZREMRANGEBYSCORE fruits 3.0 5.0
ZRANGE fruits 0 -1
- 返回集合中元素个数
ZCARD key
返回指定范围中元素的个数
ZCOUNT key min max
ZCOUNT fruits 4 7
ZCOUNT fruits (4 7

- 并集
ZUNIONSTORE destination numkeys key [key ...] [WEIGHTS weight] [AGGREGATE SUM|MIN|MAX]
numkeys指定key的数量,必须
WEIGHTS选项,与前面设定的key对应,对应key中每一个score都要乘以这个权重
AGGREGATE选项,指定并集结果的聚合方式
SUM:将所有集合中某一个元素的score值之和作为结果集中该成员的score值
MIN:将所有集合中某一个元素的score值中最小值作为结果集中该成员的score值
MAX:将所有集合中某一个元素的score值中最大值作为结果集中该成员的score值
举例
ZADD scores1 70 tom 80 peter 60 john
ZADD scores2 90 peter 60 ben
ZUNIONSTORE scores-all 2 scores1 scores2
ZUNIONSTORE scores-all1 2 scores1 scores2 AGGREGATE SUM
ZUNIONSTORE scores-all2 2 scores1 scores2 WEIGHTS 1 0.5 AGGREGATE SUM
- 交集
ZINTERSTORE destination numkeys key [key ...] [WEIGHTS weight] [AGGREGATE SUM|MIN|MAX]
numkeys指定key的数量,必须
WEIGHTS选项,与前面设定的key对应,对应key中每一个score都要乘以这个权重
AGGREGATE选项,指定并集结果的聚合方式
SUM:将所有集合中某一个元素的score值之和作为结果集中该成员的score值
MIN:将所有集合中某一个元素的score值中最小值作为结果集中该成员的score值
MAX:将所有集合中某一个元素的score值中最大值作为结果集中该成员的score值
网易音乐排行榜怎么做?

分析
每首歌的歌名作为元素(先不考虑重复)
每首歌的播放次数作为分值
ZREVRANGE来获取播放次数最多的歌曲(就是最多播放榜了,云音乐热歌榜,没有竞价,没有权重)
新浪微博翻页
新闻网站、博客、论坛、搜索引擎,页面列表条目多,都需要分页
blog这个key中使用时间戳作为score
ZADD blog 1407000000 '今天天气不错'
ZADD blog 1450000000 '今天我们学习Redis'
ZADD blog 1560000000 '几个Redis使用示例'
ZREVRANGE blog 0 10
ZREVRANGE blog 11 20
京东图书畅销榜怎么做?
单日榜,计算出周榜单、月榜单、年榜单
京东图书畅销榜
ZADD bookboard-001 1000 'java' 1500 'Redis' 2000 'haoop'
ZADD bookboard-002 1020 'java' 1500 'Redis' 2100 'haoop'
ZADD bookboard-003 1620 'java' 1510 'Redis' 3000 'haoop'
ZUNIONSTORE bookboard-001:003 3 bookboard-001 bookboard-002 bookboard-003,行吗?
京东图书畅销榜
ZADD bookboard-001 1000 'java' 1500 'Redis' 2000 'haoop'
ZADD bookboard-002 1020 'java' 1500 'Redis' 2100 'haoop'
ZADD bookboard-003 1620 'java' 1510 'Redis' 3000 'haoop'
ZUNIONSTORE bookboard-001:003 3 bookboard-001 bookboard-002 bookboard-003 AGGREGATE MAX
并集,使用max
注意:参与并集运算的集合较多,会造成Redis服务器阻塞,因此最好放在空闲时间或者备用服务器上进行计算。