
在机器学习建模时,除了准备数据,最耗时耗力的就是尝试各种超参组合,找到模型最佳效果的过程了。即使是对于有经验的算法工程师和数据科学家,有时候也很难把握其中的规律,只能多次尝试,找到较好的超参组合。而对于初学者来说,要花更多的时间和精力。
自动机器学习这两年成为了热门领域,着力解决超参调试过程的挑战,通过超参选择算法和强大的算力来加速超参搜索的过程。
NNI (Neural Network Intelligence) 是微软亚洲研究院开源的自动机器学习工具。与当前的各种自动机器学习服务或工具相比,有非常独特的价值。在这篇文章中,你将看到:
- 什么是自动机器学习
- 目前的一些自动机器学习工具
- 关于NNI
- NNI的安装及使用过程初体验
- 总结NNI可以改进的方面
一、关于AutoML
1.AutoML出现原因
机器学习的应用需要大量的人工干预,这些人工干预表现在:特征提取、模型选择、参数调节等机器学习的各个方面。AutoML视图将这些与特征、模型、优化、评价有关的重要步骤进行自动化地学习,使得机器学习模型无需人工干预即可被应用。
2.AutoML问题定义
- 从机器学习角度讲,AutoML可以看作是一个在给定数据和任务上学习和泛化能力非常强大的系统。但是它强调必须非常容易使用。
- 从自动化角度讲,AutoML则可以看作是设计一系列高级的控制系统去操作机器学习模型,使得模型可以自动化地学习到合适的参数和配置而无需人工干预。
一个通用的AutoML定义如下:

AutoML的核心任务:
- 更好的训练效果
- 没有人为干预
- 更低的计算力需求
3.AutoML问题构成
AutoML的主要问题可以由三部分构成:特征工程、模型选择、算法选择。
特征工程
特征工程在机器学习中有着举足轻重的作用。在AutoML中,自动特征工程的目的是自动地发掘并构造相关的特征,使得模型可以有最优的表现。除此之外,还包含一些特定的特征增强方法,例如特征选择、特征降维、特征生成、以及特征编码等。这些步骤目前来说都没有达到自动化的阶段。
上述这些步骤也伴随着一定的参数搜索空间。第一种搜索空间是方法自带的,例如PCA自带降维参数需要调整。第二种是特征生成时会将搜索空间扩大。
模型选择
模型选择包括两个步骤:选择一个模型,设定它的参数。相应地,AutoML的目的就是自动选择出一个最合适的模型,并且能够设定好它的最优参数。
算法选择
对于算法选择,AutoML的目的是自动地选择出一个优化算法,以便能够达到效率和精度的平衡。常用的优化方法有SGD、L-BFGS、GD等。使用哪个优化算法、对应优化算法的配置,也需要一组搜索空间。
从全局看
将以上三个关键步骤整合起来看,一个完整的AutoML过程可以分成这么两类:一类是将以上的三个步骤整合成一个完整的pipeline;另一类则是network architecture search,能够自动地学习到最优的网络结构。在学习的过程中,对以上三个问题都进行一些优化。
4.基本的优化策略
一旦搜索空间确定,我们便可以实用优化器(optimizer)进行优化。这里,AutoML主要回答三个问题:
- 选择的优化器可以作用在哪个搜索空间上?
- 它需要什么样的反馈?
- 为了取得一个好的效果,它需要怎样的配置?
简单的优化搜索方式包括grid search和random search。其中grid search被广泛使用。
从样本中进行优化的方法主要包括启发式搜索、derivative-free优化、以及强化学习方法。梯度下降法是一种重要的优化策略。
5.评价策略
基本评价策略
在设计评价策略时,AutoML主要回答三个问题: - 这种策略能能够快速进行评价吗? - 这种策略能够提供准确的评价吗? - 这种策略需要怎样的反馈?
基本的评价策略包括: - 直接评价。直接在目标数据上进行评价。这是被使用最多的策略。 - 采样。当数据样本量非常大时,采样一些样本进行评价。 - Early stop。当遇到一些极端情况使得网络表现效果不好时,可以考虑进行early stop。 - 参数重用。将之前学习过的参数重复利用在新任务上。这在两种任务配置差不多时可用。 - 共轭评价。对于一些可量化的配置,可以用共轭评价法进行。
高级评价策略
高级评价策略主要包括两种:meta-learning和transfer learning。
- Meta-learning法。从先前的学习经验中提炼出基本的参数和结构配置。
- Transfer learning法。从先前的学习经验中提炼出可以重用的一些知识。
6.应用
- 使用Auto-sklearn进行模型选择。
- 使用强化学习进行neural architecture search。
- 使用ExploreKit进行自动特征构建。
7.展望
未来可能的研究方向:
- 提高AutoML的效率。
- 更明确的问题定义。
- 发展基本和高级的搜索策略。
- 找到更适合的应用。
二、目前的AutoML工具比较
1.TPOT
简介:

TPOT是一个使用genetic programming算法优化机器学习piplines的Python自动机器学习工具。
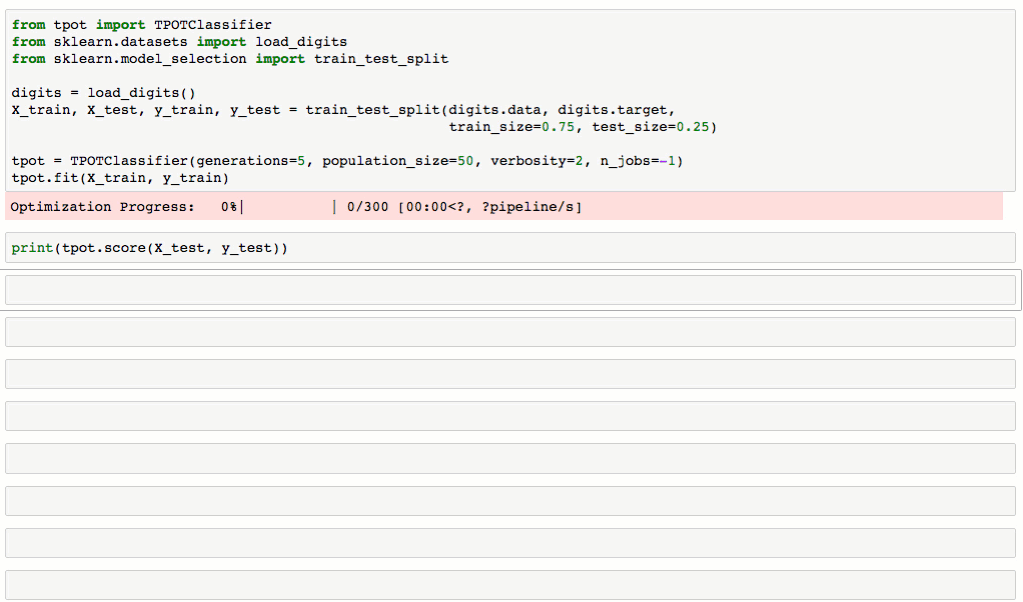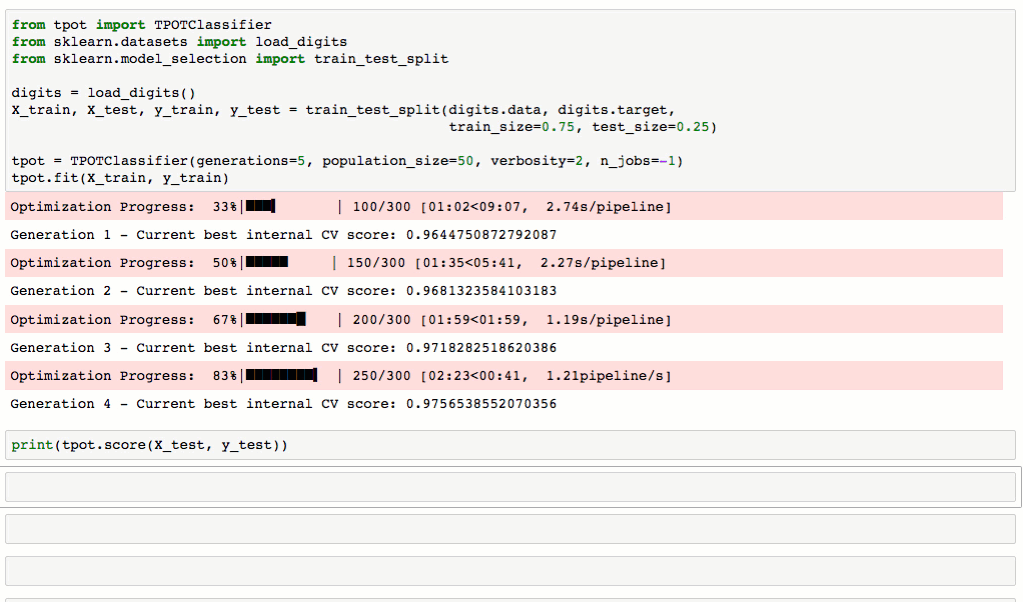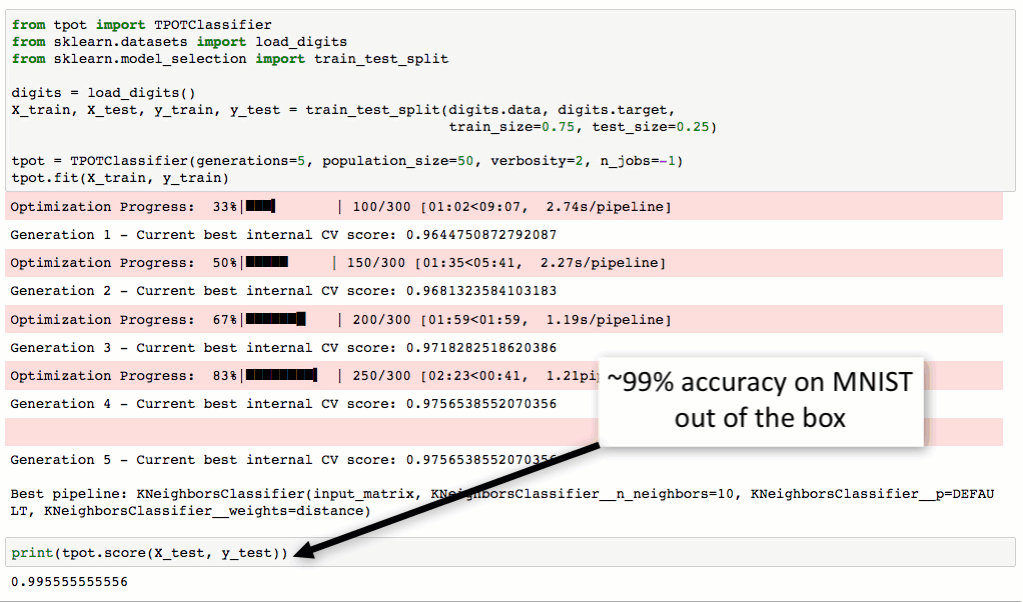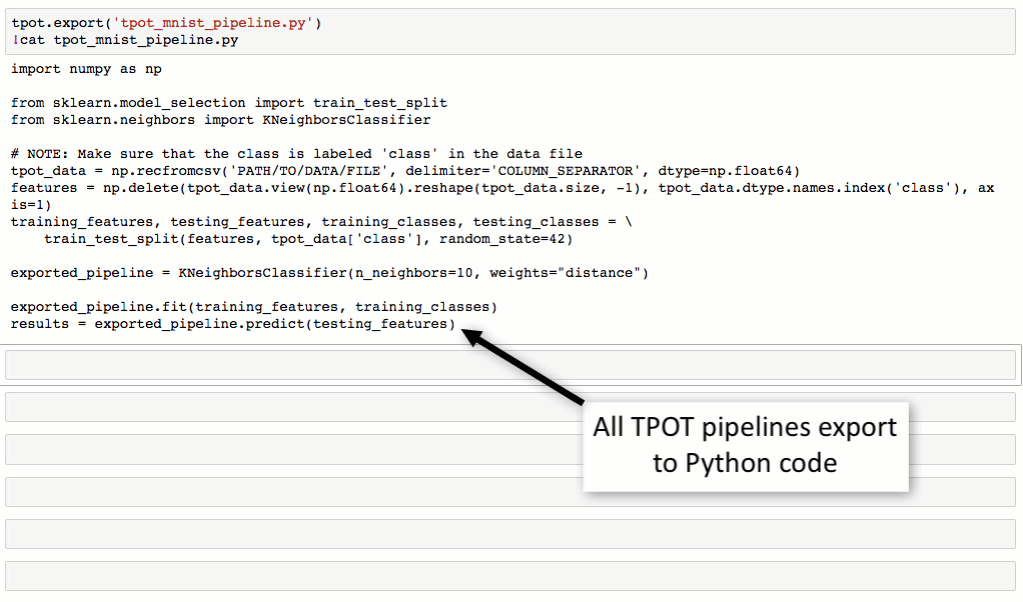
TPOT将通过智能地探索数千种可能的piplines来为数据找到最好的一个,从而自动化机器学习中最乏味的部分。
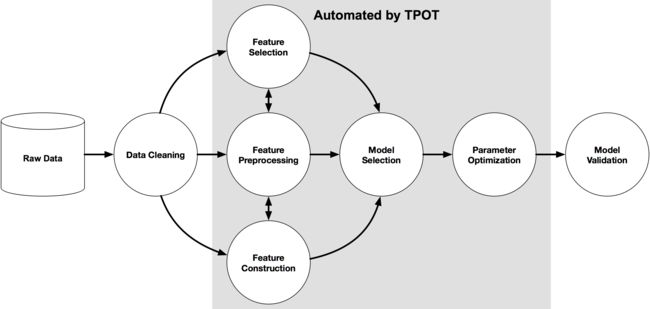
一旦TPOT完成了搜索,它就会为用户提供Python代码,以便找到最佳的管道,这样用户就可以从那里修补管道。

输出结果:
最佳模型组合及其参数(python文件)和最佳得分。
优劣:
tpot在数据治理阶段采用了PCA主成份分析,在模型选择过程中可以使用组合方法,分析的过程比起其他工具更科学,并能直接生成一个写好参数的python文件,但输出可参考的结果较少,不利于进一步分析。
2.Auto_Sklearn
简介:
auto-sklearn将机器学习用户从算法选择和超参数调整中解放出来。它利用了最近在贝叶斯优化、元学习和集成构建方面的优势。

主要使用穷举法在有限的时间内逐个尝试最优模型,上图是它的架构体系,看的出来他的工作逻辑是目前的开源框架中最复杂的一款,步骤就不细说了,大体过程应该是与Tpot相似的。
输出结果:
计算过程以及最终模型的准确率。
优劣:
穷举法简单粗暴,但也是最靠谱的,如果时间充裕的情况下可以加大预算周期不断让机器尝试最优解,但输出结果太少,基本上对进一步数据分析的帮助不大。
3.Advisor

简介:
Advisor是用于黑盒优化的调参系统。它是Google Vizier的开源实现,编程接口与Google Vizier相同。
输出结果:
推荐参数与训练模型。
优劣:
方便与API、SDK、WEB和CLI一起使用,支持研究和试验抽象化,包括搜索和early stop算法,像Microsoft NNI一样的命令行工具。
介绍完以上这些开源的自动机器学习工具,下面一节就要隆重介绍NNI了,NNI对比以上的工具有很多吸引人的优势,同时作为一个刚刚开源的项目,不可避免也存在一些可以改进的方面,让我们开始吧!
三、关于NNI
1.什么是NNI
NNI (Neural Network Intelligence) 是自动机器学习(AutoML)的工具包。 它通过多种调优的算法来搜索最好的神经网络结构和(或)超参,并支持单机、本地多机、云等不同的运行环境。
2.我们能用NNI做什么?
- 在本地 Trial 不同的自动机器学习算法来训练模型。
- 在分布式环境中加速自动机器学习(如:远程 GPU 工作站和云服务器)。
- 定制自动机器学习算法,或比较不同的自动机器学习算法。
- 在自己的机器学习平台中支持自动机器学习。
3.NNI安装和使用过程体会
安装
NNI的安装过程非常方便,基本没遇到什么障碍,但需要注意的是,NNI目前只支持Linux和Mac(据说兼容win10版本正在开发中),不过在win10上有一个解决方案是可以去应用商店下载一个Ubuntu虚拟机,也能很方便的开发。

NNI的官方文档上介绍了三种安装方式,整个过程非常简单,和大部分的开源框架一样,我使用的是第一种:
-
通过 pip 命令安装 NNI
先决条件:
python >= 3.5python3 -m pip install --upgrade nni
使用体验
将NNI从GitHub上clone到本地后,进入路径~/nni/examples/trials/mnist-annotation$,这里是官方提供的mnist-annotation例子,能够带你迅速的了解NNI的使用。
将NNI的使用总结一下大体是如下的流程:
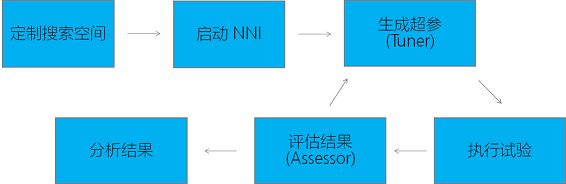
首先定制搜索空间(即你提供给NNI一个参数选择范围)
-
命令行启动NNI:
nnictl create --config ./config.yml
 启动nni.PNG
启动nni.PNG
- 在浏览器中打开
Web UI url,可以看到NNI的可视化界面: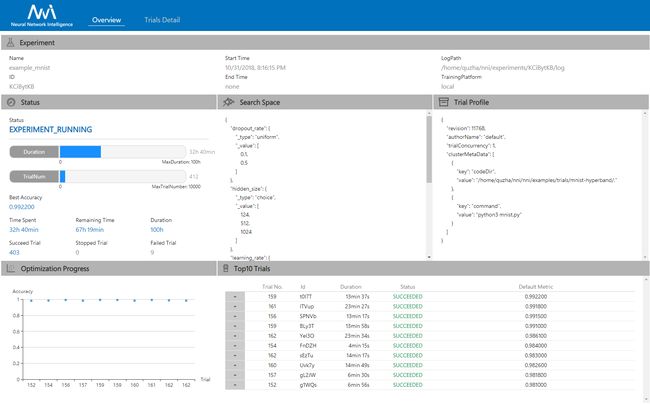

NNI的可视化界面也是相较其他工具最讨喜的方面之一,能够让用户在整个实验过程中获得对训练结果的直观理解,方便分析。
- 首页,点击
overview,可以看到当前试验的进展情况,搜索参数和效果最好的一些超参组合。支持下载 Experiment 结果.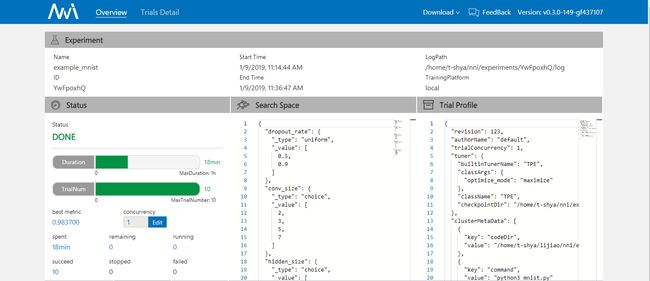 over1.png
over1.png
- 查看最好结果的 Trial。
 over2.png
over2.png
-
通过超参的分布图来直观地看到哪些超参值会明显比较好,或者看出它们之间的关联。通过下面的颜色图就能直观地看到红色(即精度较高的超参组合)线条所表达的丰富信息。如:
卷积核大一些会表现较好。
全连接层大了不一定太好。也许是所需要的训练时间增加了,训练速度太慢造成的。
而学习率小一些(小于0.005),表现基本都不错。
ReLU 比 tanh 等其它激活函数也好不少。
- ...
 Hyper Parameter
Hyper Parameter
- 通过试验状态页面,能看到每个试验的时间长度以及具体的超参组合。

-
点击 "Trials Detail" 标签查看所有 Trial 的状态。 特别是:
- Trial 详情:Trial 的 id,持续时间,开始时间,结束时间,状态,精度和搜索空间。
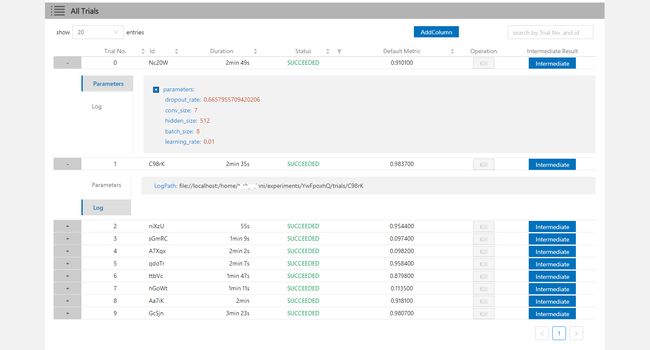
- Trial 详情:Trial 的 id,持续时间,开始时间,结束时间,状态,精度和搜索空间。
- 如果在 OpenPAI 或 Kubeflow 平台上运行,还可以看到 hdfsLog。

Kill: 可终止正在运行的任务。
支持搜索某个特定的 Trial。
- 中间结果图。
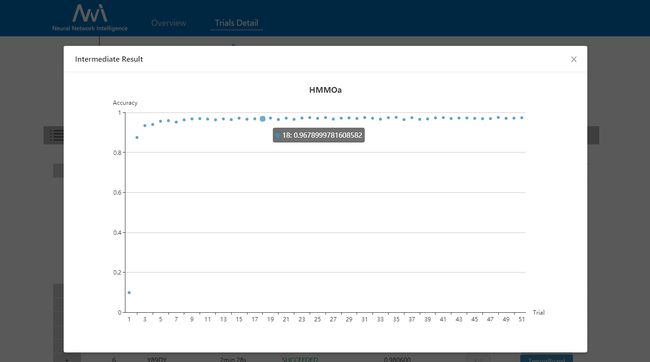
4.NNI的优势
-
支持私有部署。云服务中的自动机器学习直接提供了自动机器学习的服务,不仅包含了自动机器学习的功能,也包含了算力。如果团队或个人已经有了很强的算力资源,就需要支持私有部署的自动学习工具了。
NNI 支持私有部署。整个部署也很简单,使用 pip 即可完成安装。
-
分布式调度。NNI 可以在单机上完成试验,也支持以下两种分布式调度方案:
- GPU 远程服务器。通过 SSH 控制多台 GPU 服务器协同完成试验,并能够计划每个试验所需要的 GPU 的数量。
- OpenPAI。通过 OpenPAI,NNI 的试验可以在独立的 Docker 中运行,支持多样的实验环境。在计算资源规划上,不仅能指定 GPU 资源,还能制定 CPU,内存资源。
-
超参搜索的直接支持。当前,大部分自动机器学习服务与工具都是在某个任务上使用,比如图片分类。这样的好处是,普通用户只要有标记数据,就能训练出一个高质量的平台,不需要任何模型训练方面的知识。但这需要对每个训练任务进行定制,将模型训练的复杂性包装起来。
与大部分现有的自动机器学习服务与工具不同,NNI 需要用户提供训练代码,并指定超参的搜索范围。这样的好处在于,NNI 几乎是通用的工具,任何训练任务都可以使用 NNI 来进行超参搜索。但另一方面,NNI 的通用性,也带来了一定的使用门槛。使用 NNI 需要有基本的模型训练的经验。
 步骤
步骤 兼容已有代码。NNI 使用时,可以通过注释的方法来进行无侵入式的改动。不会影响代码原先的用途。通过注释方式支持 NNI 后,代码还可以单独运行。
-
易于扩展。NNI 的设计上有很强的可扩展性。通过下面这些扩展性,能将系统与算法相隔离,把系统复杂性都包装起来。
- Tuner 接口,可以轻松实现新的超参调试算法。研究人员可以使用 NNI 来试验新的超参搜索方法,比如在强化学习时,在 Tuner 中支持 off-policy 来探索比较好的超参组合,在 Trial 里进行 on-policy 的实际验证。也可以使用 Tuner 和训练代码相配合,支持复杂的超参搜索方法。如,实现 ENAS ,将 Tuner 作为 Control,在多个 Trial 中并行试验。
- Accessor 接口,可以加速参数搜索,将表现不好的超参组合提前结束。
- NNI 还提供了可扩展的集群接口,可以定制对接的计算集群。方便连接已经部署的计算集群。
可视化界面。在启动一次超参搜索试验后,就可以通过可视化界面来查看试验进展,并帮助超参结果,洞察更多信息。
四、对NNI的建议
1.拓展web UI的功能:
通过控制页面还可以实时的增加试验的超参组合,或者调整超参的范围。
能够在界面中读取之前的log文件
2.中文文档:
便于学生使用与查阅,拓展使用群体,降低上手门槛(已解决)
3.加入新算法:
就在发稿前些天,NNI 支持了较新的 ENAS 算法。看来 DARTS 指日可待。这些 Tuner 算法会在后续的文章中依次介绍的。
五、参考资料
Taking Human out of Learning Applications: A Survey on Automated Machine Learning
一篇比较全面的AutoML综述
重磅!微软开源自动机器学习工具 - NNI
开源自动机器学习(AutoML)框架盘点