谷歌分布式三宝
BigTable、GFS、MapReduce这传说中的谷歌分布式三驾马车,虽然谷歌没有公开具体实现代码,但却公布了相应论文,对分布式文件系统、大数据挖掘和NoSQL流行起了重大促进作用,开源界相对应产品是Hbase、HDFS、Hadoop;距谷歌这三篇论文发表已近10年,谷歌内部这三驾马车也在更新换代:
BigTable--MegaStore--Spanner、F1
GFS--Colossus
MapReduce--MapReduce、Percolator、Dremel
MegaStore构建在BigTable之上,是个支持同步复制的半关系型数据库,试图融合NoSQL和SQL,但写吞吐量比较差,所以后续又有了Spanner、F1;Colossus就是GFS2代了;而MapReduce却没有被替代,只是多了Percolator和Dremel这样的提供批处理和实时处理的额外补充方案。
我粗糙解读下谷歌Spanner、F1两篇论文,希望能窥一窥NewSQL的大概原理,当然Spanner、F1只是NewSQL一种实现方式,另一种实现方式是in-memory方式(如H-Store),这里不作讨论;对分布式文件系统Colossus和数据挖掘框架MapReduce等本文也不做讨论。
** Spanner和F1是什么?**
Spanner:高可扩展、多版本、全球分布式外加同步复制特性的谷歌内部数据库,支持外部一致性的分布式事务;设计目标是横跨全球上百个数据中心,覆盖百万台服务器,包含万亿条行记录!(Google就是这么霸气-)
F1: 构建于Spanner之上,在利用Spanner的丰富特性基础之上,还提供分布式SQL、事务一致性的二级索引等功能,在AdWords广告业务上成功代替了之前老旧的手工MySQL Shard方案。
** Spanner特性概览**
1.跨数据中心级的高可用
2.临时多版本的数据库,每个数据的版本由commit时间戳来区分
3.支持常见事务
4.支持基于SQL的查询语言
5.数据中心级的资源透明分配,譬如:a.某个数据中心放什么数据,这样可以将用户数据放在离得近的数据中心(有助降低读延迟);b.各个复制集之间相距距离,这样话可以将各个数据集尽量靠在一起(有助于降低写延迟);c.数据中心间可以动态传输分配资源,以达负载均衡目的
6.外部一致性的读写和全局一致性的读;这样可以避免跨数据中心的备份和MapReduce操作出现数据的不一致性
7.原子级全局schema变更(即使当前变更的schema正有事务在执行)
** Spanner的总体架构**

简单点:Universe > Zone > Spanserver
Universe:Spanner最大的划分单位,目前全球三个:一个用作测试、一个生产环境、一个开发/生产混合型。它包含很多zone,这些zone由univer master来显示各自运行状态,当这些zone之间数据传输交流时,是由叫placement driver的东东来负责控制的。
Zone:Zone是Spanner数据复制的最小区间单位,一个数据中心一般包含一个或多个zone;当一个数据需要复制时,可不是说把这个数据复制到第M数据中心的第N台server,而是发出类似复制到zone X这样的指令;所以zone具有物理隔离性。一般一个zone含有几百台spanserver,有一个zone master来分配哪些数据到哪个
spanserver;同时还有location proxies--一个代理中间件,负责分配哪个spanserver处理对应客户端请求。
spanserver: 就是一台物理服务器,没什么可说的.
spanserver的物理结构

Tablet:最小物理存储单位。每个spanserver有100~1000个tablet,tablet存储的是一些映射,如这种表示:
(key:字符串, timestamp:64位的整数)--对应的字符串
你一定说这不就是KV存储嘛,但请看多了timestamp这个时间戳,因此谷歌说它更像多版本数据库而不是KV数据库(个人感觉强词夺理,哈哈)。Tablet的底层文件存储方式是B-Tree结构的,此外还有预写日志文件。
Paxos Group:spanserver之间是通过Paxos协议来复制的,在每个tablet上有个Paxos状态机,记录相关tablet的meta信息。Paxos里的leader能一直当下去,只要一直lease下去,每次lease时间默认10s。Paxos里的写操作要记录到日志里,而且要记录两次,一次写在tablet里,一次记录在Paxos本身日志里。写操作必须要Paxos leader先初始化下,而读操作可以从其他有数据的replica直接读,一些这样的读写replica组成了一个Paxos Group。
Directory
前面说了一些tablet+Paxos状态机可以结合成一个Paxos Group,group之间也有数据交互传输,谷歌定义了最小传输复制单元directory--是一些有共同前缀的key记录,这些key也有相同的replica配置属性。这样就能很方便的以directory为单位从一个Paxos group移到另一个group里了,速度嘛--一个50M的directory移动需要几秒。此外当一个Directory过大时Spanner会对它进行分片。

Spanner的数据模型
对开发人员来说,他可不管数据库的体系结构或物理格式,他需要的就是一个SQL接口抽象,所以数据模型很重要。
Spanner的数据模型由三部分组成:具备同步复制功能的半关系型表、类SQL语言支持、跨行事务支持。有了这层抽象,开发人员就能很容易在schema里建传统关系型表、使用类SQL查询,使用事务了。
但严格说Spanner的表不是关系型的,倒像KV存储,因为每张表都需要一个主键。1列或几列组成的主键当做key,其他列当做value。你可能会说InnoDB每张表不也需要主键,但InnoDB就不是kV存储呀;不同于InnoDB,InnoDB是非聚簇索引参考聚簇索引(主键)形成表内的层次关系,Spanner里是各个表之间都有层次关系,一个表主键需引用另个表主键组成父子关系.譬如下面例子,虽然语句创建了了user和album两个表,但实际存储不是两个表,而是album参考user主键一个KV大表:

Spanner的大杀器--TrueTime API
其实分布式关系型数据库学术界都提了好多年了,但一直鲜有听说 ,也是直到近几年才有MySQL Cluster、NuoDB、VoltDB、OceanBase等产品问世,why?原因在于关系型分布式数据库实现ACID、分布式事务和分布式join确实有工程上的极大困难,那谷歌又是如何克服的呢其实? 其实Spanner运用的大部分理论也就是常见的2PL、2PC、Paxos等,独到的地方是就是TrueTime API--我认为本篇论文最有价值的部分。
TrueTime API是什么?是基于GPS和原子钟的实现,能将各节点的时间不一致缩小控制在10ms以内!因为分布式数据库对时间要求很高,假如不同地区的数据库节点出现时间不一致,对一致性复制、恢复都是大麻烦;传统NTP时间同步由于不太可靠一般不在分布式环境中使用,逻辑时钟(如lamport时钟、向量时钟)又有因果顺序、通信开销等问题,所以谷歌采用了基于GPS和原子钟的True Time(意味着准确真实的时间!),解决了跨地区分布式节点时间同步问题。
虽然可能实现较复杂,但True Time调用起来却很简单,它包含三个方法:
TT.now():当前时间,返回值是一个时间间隔--[起始时间,结束时间];因为误差总是客观存在,谷歌没表达成通常的T+误差这种形式,而是给了个时间范围间隔;
TT.after(t):返回True,如果t已经发生过了
TT.before(t):返回True,如果t尚未发生
每个数据中心都有一系列True Time masters,这些master代表着绝对正确的时间,然后每台机器上的Time slave来从Time master同步。因为单独GPS或原子钟都有可能失效(引起失效原因各自不同),为以防万一所以有这两种时间确定方式;大部分Time master使用GPS天线接受信号确定时间,另一部Time Master分参考原子钟的时间。GPS和原子钟这两种方式哪个准确率高或者说更值得参考呢?答案是GPS方式,因为随着时间推移,总归会有不准确情况,当出现不准确就需要及时从正确源同步以调整,原子钟广播的时间时会有一小段1~7ms的不确定的时间漂移误差,而GPS却几乎没这种情况。
事务并发控制
Spanner支持两种事务和一种操作:
1.读写事务(只写事务也算此类)
对于最典型的读写事务,Spanner使用常见的两步锁策略(2PL)来控制并发,并实现了一个所谓的外部一致性:假如事务2在事务1提交后才开始,则事务2提交时间需大于事务1提交时间。
对于写操作,写操作都先缓存在客户端这边,所以不到此次事务提交,其他读操作是看不到写结果的;对于读操作,Spanner会加读锁,并使用wound-wait算法避免死锁;当读写都完毕后,使用两步提交协议(2PC)进行组提交到其他节点.但2PC协议最怕的就是协调者或参与者宕机导致其他节点漫长的等,Spanner很巧妙的利用Paxos复制协调者和参与者生成的日志到其他副本集,这样就算协调者或参与者挂掉也有副本上日志可代替读取.
读写事务中比较特别的是更改schema了,在关系型数据库中这种DDL操作一般会加锁阻塞读写,Spanner能神奇的做到不加锁无阻塞,其独到之处是预分配:1.分配一个未来的时间戳t,这样每个节点都知道在t时刻schema会变,正在访问这个schema的读写操作就会自动同步改变;但如果读写操作过了时间戳t,则仍然会阻塞。
2.只读事务
类似于Innodb的MVCC,Spanner基于True Time实现了多版本的快照隔离级别,可以无锁读,也即一个只读事务不影响其他事务的写。只要这事务的time确定,哪怕当前正在读的spanserver坏了,也可以基于True Time从其他replica继续读。但也不是任何replica都能提供某个事务的读的,必须这个replica的"本机时间"大于事务开始的时间,这个“本机时间”是由Paxos状态机和事务管理器一起决定的。
3.快照读
只要提供一个已经过去的时间戳,就能在任何replica上读取这个时间点(段)的数据。
Spanner的性能
spanserver配置: AMD Barcelona 4核CPU(2200MHz)+4G内存
客户端与测试机网络延迟: <1ms(因为在同一个数据中心里)
测试数据集: 是由50个Paxos Group、2500个directories组成的
测试方法: 4K读写
结果:
1.单台机器事务commit等待时间5ms,Paxos复制延迟大概9ms;而随着replica的增多,这两项数值变化却不大,当复制规模达到一定程度时,延迟也趋于一稳定值.
2.而对于分布式事务2PC的延迟,则相对较大,谷歌给出了如下测试结果表:
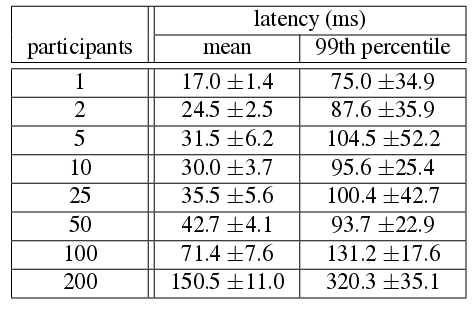
总结:
由于论文的晦涩和本人阅读的不详细,很多细节都没描述出来,但可看出Spanner是一个提供半关系型结构、常见事务支持、类SQL接口且具有高可扩展性、自动分片、同步复制、外部一致性的全球分布式系统;但我感觉这样还不能算彻底的NewSQL,得再加上基于Spanner的F1才能算作NewSQL,下一篇Google NewSQL之F1会介绍F1的相关内容。
参考资料
[Spanner: Google’s Globally-Distributed Database](http:// research.google.com/archive/spanner-osdi2012.pdf )
Google Spanner原理- 全球级的分布式数据库
从Google Spanner漫谈分布式存储与数据库技术
MIT DB Course