Hadoop集群+Zookeeper实现高可用集群
设备的列表信息
| 节点类型 | IP | hosts(主机名) |
|---|---|---|
| NameNode | 192.168.56.106 | master |
| NameNode | 192.168.56.107 | standby-master |
| DataNode,JournalNode | 192.168.56.108 | slave1 |
| DataNode,JournalNode | 192.168.56.109 | slave2 |
| DataNode,JournalNode | 192.168.56.110 | slave3 |
一共配备的5台的设备,master充当(active)角色,standby-master充当(standby)角色,当master出现单点故障的时候,standby-master就会顶上去充当(active)角色来维持整个集群的运作。
搭建Ha集群依赖环境
| 环境名称 | 版本号 |
|---|---|
| CentOS | 7 |
| Jdk | jdk-8u131 |
| Hadoop | 2.6.5 |
| zookeeper | 3.4.10 |
把jdk、Hadoop、zookeeper解压到/use/local/目录下
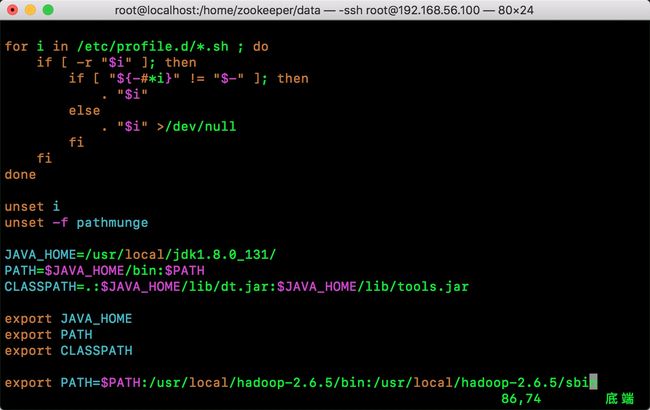
编辑 /etc/profile文件分别加入jdk、Hadoop的环境变量
vim /etc/profile
加入以下环境变量:
JAVA_HOME=/usr/local/jdk1.8.0_131/
PATH=$JAVA_HOME/bin:$PATH
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export JAVA_HOME
export PATH
export CLASSPATH
export PATH=$PATH:/usr/local/hadoop-2.6.5/bin:/usr/local/hadoop-2.6.5/sbin
编辑hadoop-2.6.5/etc/hadoop/hadoop-env.sh文件加入Java环境变量

这是我本次搭建用到的系统版本。
配备zookeeper集群
我会在slave1、slave2、slave3这三台机器上添zookeeper集群,把JournalNode节点交给zookeeper做调度。
解压后进入/zookeeper-3.4.10/conf/目录
拷贝 cp zoo_sample.cfg 改名成 zoo.cfg
拷贝 cp zoo_sample.cfg zoo.cfg
在zoo.cfg文件添加以下配置:
dataDir=/home/zookeeper/data
dataLogDir=/home/zookeeper/logs
clientPort=2181
server.1=slave1:2888:3888
server.2=slave2:2888:3888
server.3=slave3:2888:3888
配置myid:
我这里有3台zk集群机器,每台机器都需要在/home/zookeeper/data 目录下创建一个myid的文件、并且要写上自己对应的服务id号,比如我在slave1这台机器对应的service.id是1 那么我在myid就会写上1,slave2的service.id是2 就会写上2.. 以此类推。
cd /home/zookeeper/data/
vim myid (写上服务的id号保存退出)
编写开机启动脚本(为了方便启动,不用每次手动启动zk集群,如果觉得麻烦可以忽略该步骤)
写了一个脚本设置zookepper开机启动
在/etc/rc.d/init.d/目录下添加一个文件叫zookeeper
命令:touch zookeeper
写入以下配置,JAVA_HOME是你jdk的安装位置,ZOO_LOG_DIR是zookeeper存放日志的位置,ZOOKEEPER_HOME是zookeeper的安装位置。
#!/bin/bash
#chkconfig: 2345 10 90
#description: service zookeeper
export JAVA_HOME=/usr/local/jdk1.8.0_131
export ZOO_LOG_DIR=/home/zookeeper/datalog
ZOOKEEPER_HOME=/usr/local/zookeeper-3.4.10
su root ${ZOOKEEPER_HOME}/bin/zkServer.sh "$1"
为新建的zookeeper文件添加可执行权限
命令:chmod +x /etc/rc.d/init.d/zookeeper
添加zookeeper到开机启动
命令:chkconfig --add zookeeper
重启你的的zk集群
检查你的zookeeper集群确保没问题
命令:/usr/local/zookeeper-3.4.10/bin/zkServer.sh status
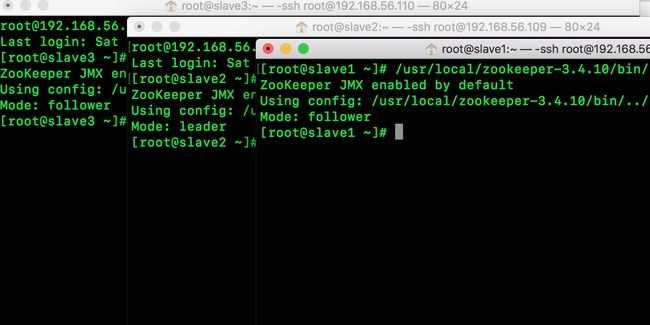
以上已经配置好zookeeper集群
设置SSH免密登陆
两台NameNode之间的协调需要SSH登陆来实现,所以两台NameNode必须要配置好
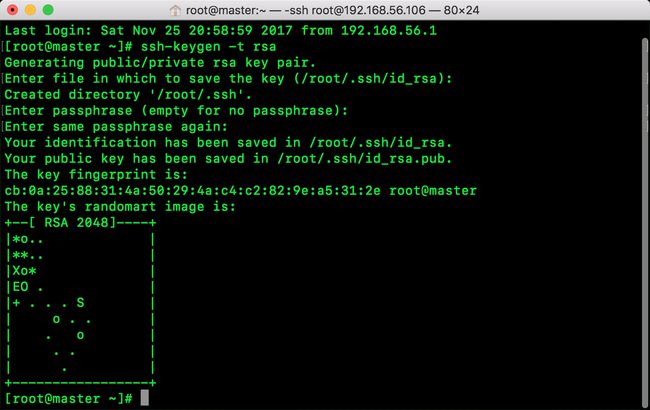
进入master这台机器的的根目录
输入命令:ssh-keygen -t rsa
出现提示可以不理会 直接按几次回车键就行了,出现以下界面说明生成私钥id_rsa和公钥id_rsa.pub
把生成的公钥id发送到 slave1、slave2、slave3、机器上
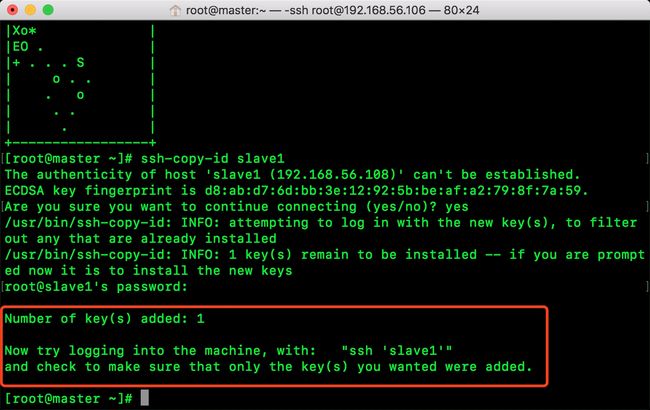
输入命令: ssh-copy-id slave1
slave1会要求你输入slave1这台机器上的密码

密码输入正确后你会看到以下界面,它说已经添加了密钥,它叫你尝试登陆一下
添加其他的slave2、slave3、slave4、standby-master、master也是同样的操作。(一共5台机器,包括目前本机)
在master完成以上操作之后,再到standby-master 重复以上的操作。(记得两个NameNode都要进行操作,重要的事再说一遍)。
配置Hadoop集群
配置core-site.xml
在core-site.xml加入以下配置
master是整个服务的标识、以及配备了zookeeper的配置信息
fs.defaultFS
hdfs://master
hadoop.tmp.dir
/home/hadoopData/hdfs/temp
io.file.buffer.size
4096
ha.zookeeper.quorum
slave1:2181,slave2:2181,slave3:2181
配置hdfs-site.xml
dfs.namenode.name.dir
/home/hadoopData/dfs/name
dfs.datanode.data.dir
/home/hadoopData/dfs/data
dfs.replication
3
dfs.webhdfs.enabled
true
dfs.permissions.superusergroup
staff
dfs.permissions.enabled
false
dfs.nameservices
master
dfs.ha.namenodes.master
nn1,nn2
dfs.namenode.rpc-address.master.nn1
master:9000
dfs.namenode.http-address.master.nn1
master:50070
dfs.namenode.rpc-address.master.nn2
standby-master:9000
dfs.namenode.http-address.master.nn2
standby-master:50070
dfs.namenode.shared.edits.dir
qjournal://slave1:8485;slave2:8485;slave3:8485/master
dfs.journalnode.edits.dir
/home/hadoopData/journal
dfs.ha.automatic-failover.enabled
true
dfs.client.failover.proxy.provider.master
org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
dfs.ha.fencing.methods
sshfence
dfs.ha.fencing.ssh.private-key-files
/root/.ssh/id_rsa
dfs.replication
2
dfs.webhdfs.enabled
true
注意事项:
我这里一共拆分了3部分来说明、以上的配置的文件分别有备注说明
在dfs.nameservices标签中的value 和core-site.xml配置中的服务名要一致,因为我起名叫master,所以我这里也叫master。
dfs.namenode.shared.edits.dir标签中存放的是你的zk集群的journalnode,后面记得加上你的服务名。
把这2份配置文件分别拷贝到5台机器上。
安装fuser
在你的两台NameNode都需要安装fuser
进入你的 .ssh目录(我的目录是/root/.ssh)
安装命令: yum provides "*/fuser"
安装命令:yum -y install psmisc
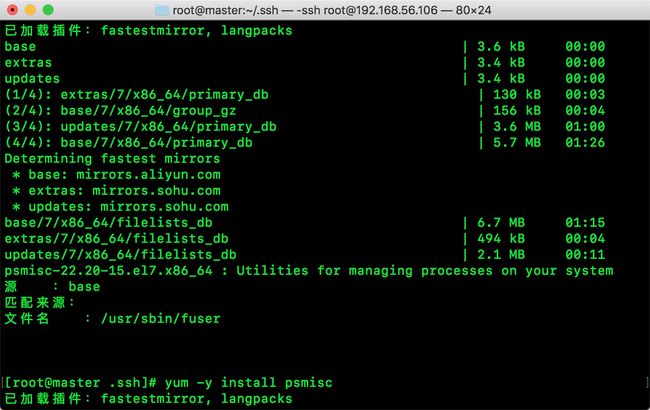
同样另外一台standby-master同样的操作。
启动Hadoop集群
在master上的操作
1.启动journalnode
命令:hadoop-daemon.sh start journalnode
因为我在master中配了slaves这个文件,把slave1、slave2、slave3都加了进来所以可以启动它们,查看DataNode节点上的journalnode是否启动成功
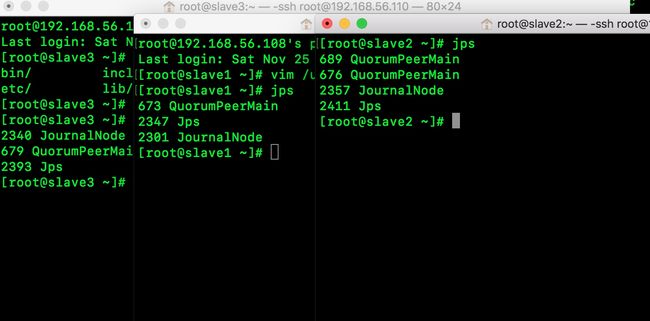
出现journalnode说明启动成功了。
2.格式化zookepper
命令: hdfs zkfc -formatZK
操作完毕出现以下内容:
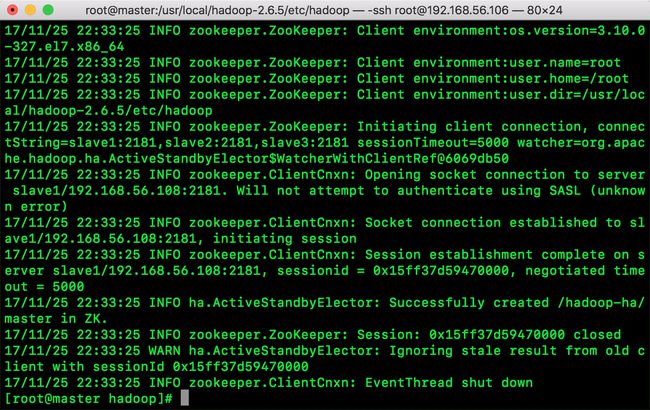
3.格式化hdfs
命令: hadoop namenode -format
操作完毕出现以下内容:
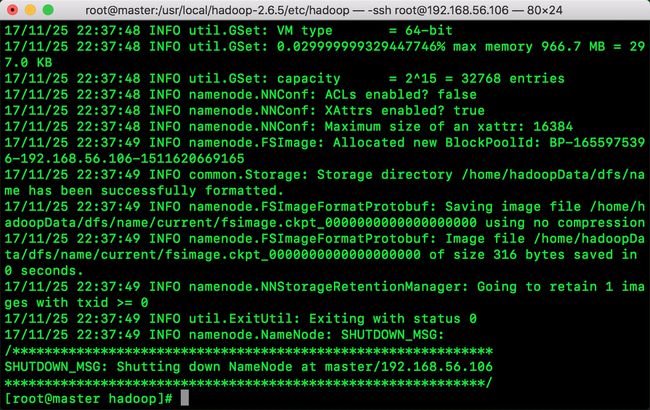
4.启动master的NameNode
命令: hadoop-daemon.sh start namenode
启动完毕后切换到standby-master操作
在standby-master操作
在master的NameNode启动之后,我们进行对NameNode的数据同步
在standby-master输入以下命令
命令:hdfs namenode -bootstrapStandby
出现以下信息:
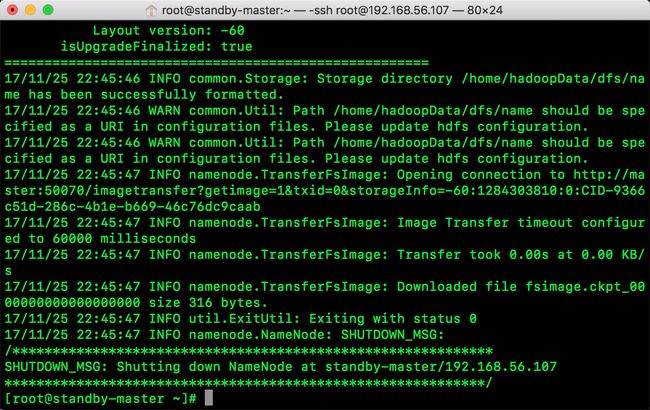
启动Hadoop集群
回到master启动集群输入以下命令
命令: start-dfs.sh
在游览器输入 http://192.168.56.106:50070/ 和 http://192.168.56.107:50070/
出现以下情况说明已经成功了。
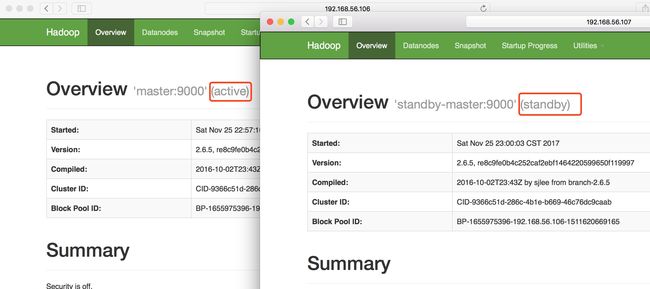
测试HA集群可用性
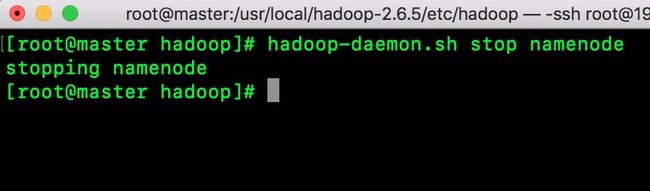
以上是master是active状态,我现在把它关闭,看看standby-master是否会自动升级为active状态。
关闭master:
观察standby-master:
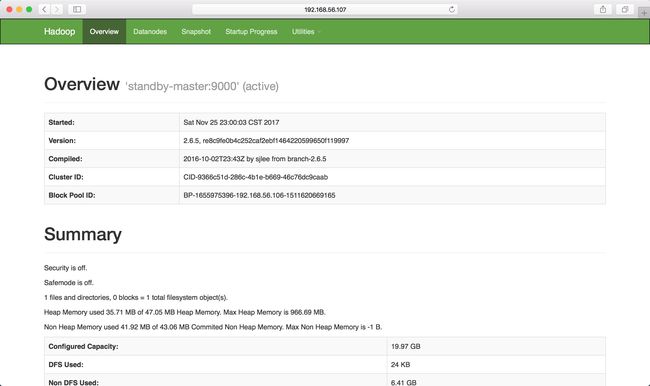
可以看到standby-master已经自动升级为active状态说明整个HA集群搭建完成了。