- 时间序列预测综述
Super_Whw
时序预测
文章目录非周期时间序列预测1.转化为监督学习数据集,使用xgboot/LSTM模型/时间卷积网络/seq2seq(attention_based_model)2.Facebook-prophet,类似于STL分解思路3.深度学习网络,结合CNN+RNN+Attention,作用各不相同互相配合参考:非周期时间序列预测1.转化为监督学习数据集,使用xgboot/LSTM模型/时间卷积网络/seq2s
- 深入理解GPT底层原理--从n-gram到RNN到LSTM/GRU到Transformer/GPT的进化
网络安全研发随想
rnngptlstm
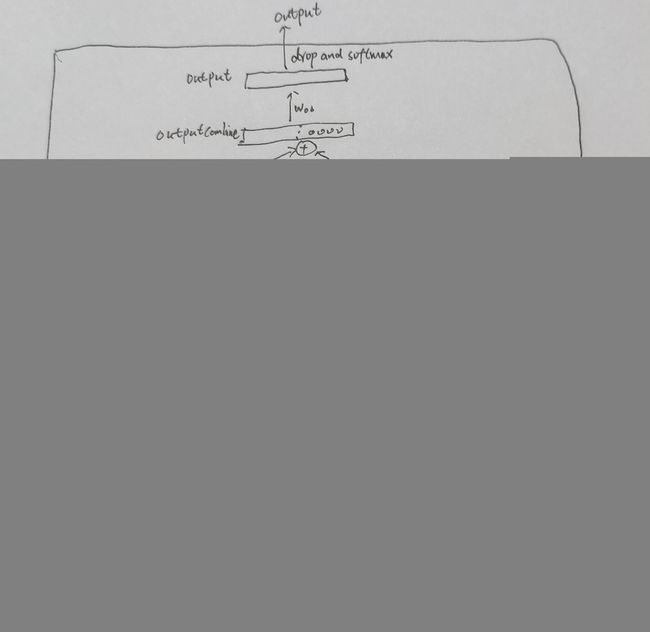
从简单的RNN到复杂的LSTM/GRU,再到引入注意力机制,研究者们一直在努力解决序列建模的核心问题。每一步的进展都为下一步的突破奠定了基础,最终孕育出了革命性的Transformer架构和GPT大模型。1.从n-gram到循环神经网络(RNN)的诞生1.1N-gram模型在深度学习兴起之前,处理序列数据主要依靠统计方法,如n-gram模型。N-gram是一种基于统计的语言模型,它的核心思想是:一
- 一篇文章搞懂Spring AOP的历程
2401_89285805
springsqljava
publicMethodMatchergetMethodMatcher(){returnnewMethodMatcher(){@Overridepublicbooleanmatches(Methodmethod,ClasstargetClass){return“echo”.equals(method.getName())&&method.getParameterTypes().length==1&
- C语言中求余的作用
Ethan@LM
c语言哈希算法开发语言
1.判断奇偶性求余运算常用于判断一个整数是否为偶数或奇数:偶数:n%2==0奇数:n%2!=0#includeintmain(){intnum=5;if(num%2==0){printf("%d是偶数\n",num);}else{printf("%d是奇数\n",num);}return0;}判断3的倍数:#includeintis_multiple_of_3(intn){returnn%3==0
- python多进程编程实例_Python多进程编程multiprocessing代码实例
weixin_39791386
python多进程编程实例
在多线程与多进程的比较这一篇中记录了多进程编程的一种方式.下面记录一下多进程编程的别一种方式,即使用multiprocessing编程importmultiprocessingimporttimedefget_html(n):time.sleep(n)print('subprocess%s'%n)returnnif__name__=='__main__':#多进程编程process=multipr
- 【Java数据结构】二叉树相关算法
回响N
算法数据结构java开发语言链表
第一题:获取二叉树中结点个数得到二叉树结点个数,如果结点为空则返回0,然后再用递归计算左树结点个数+根结点(1个)+右树结点个数。publicintnodeSize(Noderoot){if(root==null)return0;returnnodeSize1(root.left)+nodeSize1(root.right)+1;}第二题:获取叶子结点的个数得到叶子结点个数和结点总数的做法相同,也
- ChatGPT4.0最新功能和使用技巧,助力日常生活、学习与工作!
WangYan2022
教程人工智能chatgpt数据分析ai绘画AI写作
熟练掌握ChatGPT4.0在数据分析、自动生成代码等方面的强大功能,系统学习人工智能(包括传统机器学习、深度学习等)的基础理论知识,以及具体的代码实现方法,同时掌握ChatGPT4.0在科研工作中的各种使用方法与技巧,以及人工智能领域经典机器学习算法(BP神经网络、支持向量机、决策树、随机森林、变量降维与特征选择、群优化算法等)和热门深度学习方法(卷积神经网络、迁移学习、RNN与LSTM神经网络
- Pytorch详解-模型模块(RNN,CNN,FNN,LSTM,GRU,TCN,Transformer)
qq742234984
rnnpytorchcnn
Pytorch详解-模型模块Module¶meterModule初认识forward函数ParameterPytorch中的权重、参数和超参数Module容器-ContainersSequentialModuleListModuleDictParameterList&ParameterDict常用网络层LSTM输入和输出GRUConvolutionalLayers卷积层的基本概念常见的卷积
- 记录 io.springfox 3.0.0 整合 spring boot 2.6.x 由于 springfox bug 引发问题
树懒_Zz
Springspringbootbugwindows
首先第一个问题就是不兼容:解决方案:@BeanpublicstaticBeanPostProcessorspringfoxHandlerProviderBeanPostProcessor(){returnnewBeanPostProcessor(){@OverridepublicObjectpostProcessAfterInitialization(Objectbean,StringbeanNa
- 深度学习项目--基于LSTM的火灾预测研究(pytorch实现)
羊小猪~~
RNNLSTM神经网络案例机器学习/数据分析案例深度学习lstmpytorch人工智能机器学习rnngru
本文为365天深度学习训练营中的学习记录博客原作者:K同学啊前言LSTM模型一直是一个很经典的模型,这个模型当然也很复杂,一般需要先学习RNN、GRU模型之后再学,GRU、LSTM的模型讲解将在这两天发布更新,其中:深度学习基础–一文搞懂RNN深度学习基础–GRU学习笔记(李沐《动手学习深度学习》)这一篇:是基于LSTM模型火灾预测研究,讲述了如何构建时间数据、模型如何构建、pytorch中LST
- 从RNN到Transformer:生成式AI技术演变与未来展望
非著名架构师
人工智能rnntransformer
生成式人工智能(GenerativeAI)近年来取得了令人瞩目的进展,其背后的核心技术是自回归模型的不断演进。从传统的递归神经网络(RNN)到革命性的Transformer架构,本文将全面剖析这一技术发展历程。一、RNN:生成式模型的起点1.RNN的基本原理递归神经网络(RecurrentNeuralNetwork,RNN)是一种专为处理序列数据设计的神经网络架构。其核心思想是通过循环连接的隐藏状
- uniapp 获取各种小程序code
灵魂清零
uniapp小程序
各种小程序在进入小程序是都需要去获取code才能拿到基础信息,自己记录一下用uniapp开发小程序是获取微信小程序、百度小程序、头条小程序、支付宝小程序的codeVue.prototype.$global={appLogin(){returnnewPromise((resole,reject)=>{varthat=this;varwxLoginUrl=app.globalData.url+"/lo
- seq_len 不等于 hidden_size 难道不会报错吗,他们是一会事情吗
zhangfeng1133
python人工智能开发语言pytorch
seq_len与hidden_size在RNN中代表不同概念,不等不会报错。seq_len:序列长度,表示在处理数据时,每个批次(batch)中序列的长度。RNN网络会按照seq_len指定的长度进行循环计算1。hidden_size:隐藏层中隐藏神经元的个数,也是输出向量的长度。它决定了RNN网络中隐藏层的状态向量的维度12。在RNN的训练过程中,seq_len和hidden_si
- 【NLP5-RNN模型、LSTM模型和GRU模型】
一蓑烟雨紫洛
nlprnnlstmgrunlp
RNN模型、LSTM模型和GRU模型1、什么是RNN模型RNN(RecurrentNeuralNetwork)中文称为循环神经网络,它一般以序列数据为输入,通过网络内部的结构设计有效捕捉序列之间的关系特征,一般也是以序列形式进行输出RNN的循环机制使模型隐层上一时间步产生的结果,能够作为当下时间步输入的一部分(当下时间步的输入除了正常的输入外还包括上一步的隐层输出)对当下时间步的输出产生影响2、R
- ajax 获取一步数据,ajax异步获取数据
可可子姐姐教英语
ajax获取一步数据
functioncreateXHR(){if(typeofXMLHttpRequest!="undefined"){returnnewXMLHttpRequest();}elseif(typeofActiveXObject!="undefined"){varversion=["MSXML2.XMLHttp.6.0","MSXML2.XMLHttp.3.0","MSXML2.XMLHttp"];fo
- JS 获取时间
买买买买菜
/**针对Ext的工具类*/exportvarMrYangUtil=function(){/****获得当前时间*/this.getCurrentDate=function(){returnnewDate();};/****获得本周起止时间*/this.getCurrentWeek=function(){//起止日期数组varstartStop=newArray();//获取当前时间varcurr
- python数组的基本操作
迟遇3
python开发语言
一.创建数组arr:list[int]=[0]*8num1:list[int]=[1,5,9,8,6]二.访问元素1.指定访问(通过索引(下标))defrandom_a(nums:list[int])->int:returnnums[2]print(random_a(arr))2.随机访问(会访问不同的元素)defrandom_access(nums:list[int])->int:"""随机访问
- antd of vue treeSelect——异步加载
who_become_gods
onLoadData(treeNode){varthat=thisreturnnewPromise((resolve)=>{if(treeNode.
- 探索深度学习的奥秘:从理论到实践的奇幻之旅
小周不想卷
深度学习
目录引言:穿越智能的迷雾一、深度学习的奇幻起源:从感知机到神经网络1.1感知机的启蒙1.2神经网络的诞生与演进1.3深度学习的崛起二、深度学习的核心魔法:神经网络架构2.1前馈神经网络(FeedforwardNeuralNetwork,FNN)2.2卷积神经网络(CNN)2.3循环神经网络(RNN)及其变体(LSTM,GRU)2.4生成对抗网络(GAN)三、深度学习的魔法秘籍:算法与训练3.1损失
- python用递归方式实现最大公约数_Python - 最大公约数算法
weixin_39765325
#Python3.6#最大公约数,最大公因子#GreatestCommonDivisor#辗转相除法defgcd(num1:object,num2:object)->object:print('num1={},num2={},r={}'.format(num1,num2,num1%num2))ifnum1%num2==0:returnnum2returngcd(num2,num1%num2)#更相
- nodejs清空文件内容
不cong明的亚子
前端小技巧javascript前端node.js
话不多说,直接上代码constfs=require("fs");constpath=require("path");functionclearFile(filename){//写入文件是异步过程,需要使用promise保证文件操作完成returnnewPromise(resolve=>{letstr=path.join(__dirname,`./${filename}`);fs.writeFile
- 将input type=file 获取到的图片展示到页面上
不会做饭的程序员
JSjs
我们创建一个函数,用于接收拿到的files[0],并将生成的base64地址返回出去getBase64(file){returnnewPromise(function(resolve,reject){letreader=newFileReader();letimgResult="";reader.readAsDataURL(file);reader.onload=function(){imgRes
- 使用LSTM(长短期记忆网络)模型预测股票价格的实例分析
eeee~~
深度学习lstm人工智能rnn金融python神经网络
一:LSTM与RNN的区别LSTM(LongShort-TermMemory)是一种特殊的循环神经网络(RNN)架构。LSTM是为了解决传统RNN在处理长序列数据时遇到的梯度消失或梯度爆炸问题而设计的。在传统的RNN中,信息通过隐藏状态在时间步之间传递,但由于权重的重复应用,随着时间的推移,梯度可能会迅速减小或增大,导致网络难以学习长期依赖关系。LSTM通过引入了一种称为“门”(gates)的机制
- 《自然语言处理 Transformer 模型详解》
黑色叉腰丶大魔王
自然语言处理transformer人工智能
一、引言在自然语言处理领域,Transformer模型的出现是一个重大的突破。它摒弃了传统的循环神经网络(RNN)和卷积神经网络(CNN)架构,完全基于注意力机制,在机器翻译、文本生成、问答系统等众多任务中取得了卓越的性能。本文将深入讲解Transformer模型的原理、结构和应用。二、Transformer模型的背景在Transformer出现之前,RNN及其变体(如LSTM和GRU)是自然语言
- 【Python机器学习】循环神经网络(RNN)——传递数据并训练
zhangbin_237
Python机器学习机器学习pythonrnn人工智能开发语言深度学习神经网络
与其他Keras模型一样,我们需要向.fit()方法传递数据,并告诉它我们希望训练多少个训练周期(epoch):model.fit(X_train,y_train,batch_size=batch_size,epochs=epochs,validation_data=(X_test,y_test))因为个人小电脑内存不足,所以吧maxlen参数改成了100重新运行。保存模型:model_struc
- 李沐55_循环神经网络RNN简洁实现——自学笔记
Rrrrrr900
rnn深度学习神经网络pytorch循环神经网络python李沐
读取《时间机器》数据集!pipinstalld2l!pipinstall--upgraded2l==0.17.5#d2l需要更新importtorchfromtorchimportnnfromtorch.nnimportfunctionalasFfromd2limporttorchasd2lbatch_size,num_steps=32,35train_iter,vocab=d2l.load_da
- 【Python机器学习】循环神经网络(RNN)——对RNN进行预测
zhangbin_237
Python机器学习机器学习pythonrnn深度学习人工智能自然语言处理
目录有状态性双向RNN编码向量如果有一个经过训练的模型,接下来就可以对其进行预测:sample_1="""Ihatethatthedismalweatherhadmedownforsolong,whenwillitbreak!Ugh,whendoeshappinessreturn?Thesunisblindingandthepuffycloudsaretoothin.Ican'twaitforth
- hutool获取大数据量的excel内容及sheet名称问题
liu_qixiang
excel
读取大数据量的excel时代码如下privatestaticRowHandlercreateRowHandler(){returnnewRowHandler(){@Overridepublicvoidhandle(inti,longl,Listlist){System.out.println(i+""+l+""+list);}};}publicstaticvoidmain(String[]args
- 代码随想录算法训练营 Day5 | Hot100 | 53.最大子数组和 56.合并区间 189.轮转数组 238.除自身以外数组的乘积
火烧沙发土豆
代码随想录算法训练营算法leetcode数据结构
Day5休息,看看hot100类DP或者前缀和问题53.MaximumSubarrayclassSolution{public:intmaxSubArray(vector&nums){if(nums.size()==1)returnnums[0];intcurrSum=0;intans=nums[0];for(inti=0;i&v1,vector&v2){returnv1[0]>merged;ve
- 【关于如何调用java的private成员变量】
haozihua
java
packagepg2;classStudent{privateStringname;//设置私有成员变量,只能在本类使用privateintage;publicvoidSetname(Stringname){//set方法不需要返回值,只需要存在栈内存中this.name=name;}publicStringGetname(){//get方法需要返回值,用于其他类调用私有成员变量returnnam
- Java常用排序算法/程序员必须掌握的8大排序算法
cugfy
java
分类:
1)插入排序(直接插入排序、希尔排序)
2)交换排序(冒泡排序、快速排序)
3)选择排序(直接选择排序、堆排序)
4)归并排序
5)分配排序(基数排序)
所需辅助空间最多:归并排序
所需辅助空间最少:堆排序
平均速度最快:快速排序
不稳定:快速排序,希尔排序,堆排序。
先来看看8种排序之间的关系:
1.直接插入排序
(1
- 【Spark102】Spark存储模块BlockManager剖析
bit1129
manager
Spark围绕着BlockManager构建了存储模块,包括RDD,Shuffle,Broadcast的存储都使用了BlockManager。而BlockManager在实现上是一个针对每个应用的Master/Executor结构,即Driver上BlockManager充当了Master角色,而各个Slave上(具体到应用范围,就是Executor)的BlockManager充当了Slave角色
- linux 查看端口被占用情况详解
daizj
linux端口占用netstatlsof
经常在启动一个程序会碰到端口被占用,这里讲一下怎么查看端口是否被占用,及哪个程序占用,怎么Kill掉已占用端口的程序
1、lsof -i:port
port为端口号
[root@slave /data/spark-1.4.0-bin-cdh4]# lsof -i:8080
COMMAND PID USER FD TY
- Hosts文件使用
周凡杨
hostslocahost
一切都要从localhost说起,经常在tomcat容器起动后,访问页面时输入http://localhost:8088/index.jsp,大家都知道localhost代表本机地址,如果本机IP是10.10.134.21,那就相当于http://10.10.134.21:8088/index.jsp,有时候也会看到http: 127.0.0.1:
- java excel工具
g21121
Java excel
直接上代码,一看就懂,利用的是jxl:
import java.io.File;
import java.io.IOException;
import jxl.Cell;
import jxl.Sheet;
import jxl.Workbook;
import jxl.read.biff.BiffException;
import jxl.write.Label;
import
- web报表工具finereport常用函数的用法总结(数组函数)
老A不折腾
finereportweb报表函数总结
ADD2ARRAY
ADDARRAY(array,insertArray, start):在数组第start个位置插入insertArray中的所有元素,再返回该数组。
示例:
ADDARRAY([3,4, 1, 5, 7], [23, 43, 22], 3)返回[3, 4, 23, 43, 22, 1, 5, 7].
ADDARRAY([3,4, 1, 5, 7], "测试&q
- 游戏服务器网络带宽负载计算
墙头上一根草
服务器
家庭所安装的4M,8M宽带。其中M是指,Mbits/S
其中要提前说明的是:
8bits = 1Byte
即8位等于1字节。我们硬盘大小50G。意思是50*1024M字节,约为 50000多字节。但是网宽是以“位”为单位的,所以,8Mbits就是1M字节。是容积体积的单位。
8Mbits/s后面的S是秒。8Mbits/s意思是 每秒8M位,即每秒1M字节。
我是在计算我们网络流量时想到的
- 我的spring学习笔记2-IoC(反向控制 依赖注入)
aijuans
Spring 3 系列
IoC(反向控制 依赖注入)这是Spring提出来了,这也是Spring一大特色。这里我不用多说,我们看Spring教程就可以了解。当然我们不用Spring也可以用IoC,下面我将介绍不用Spring的IoC。
IoC不是框架,她是java的技术,如今大多数轻量级的容器都会用到IoC技术。这里我就用一个例子来说明:
如:程序中有 Mysql.calss 、Oracle.class 、SqlSe
- 高性能mysql 之 选择存储引擎(一)
annan211
mysqlInnoDBMySQL引擎存储引擎
1 没有特殊情况,应尽可能使用InnoDB存储引擎。 原因:InnoDB 和 MYIsAM 是mysql 最常用、使用最普遍的存储引擎。其中InnoDB是最重要、最广泛的存储引擎。她 被设计用来处理大量的短期事务。短期事务大部分情况下是正常提交的,很少有回滚的情况。InnoDB的性能和自动崩溃 恢复特性使得她在非事务型存储的需求中也非常流行,除非有非常
- UDP网络编程
百合不是茶
UDP编程局域网组播
UDP是基于无连接的,不可靠的传输 与TCP/IP相反
UDP实现私聊,发送方式客户端,接受方式服务器
package netUDP_sc;
import java.net.DatagramPacket;
import java.net.DatagramSocket;
import java.net.Ine
- JQuery对象的val()方法执行结果分析
bijian1013
JavaScriptjsjquery
JavaScript中,如果id对应的标签不存在(同理JAVA中,如果对象不存在),则调用它的方法会报错或抛异常。在实际开发中,发现JQuery在id对应的标签不存在时,调其val()方法不会报错,结果是undefined。
- http请求测试实例(采用json-lib解析)
bijian1013
jsonhttp
由于fastjson只支持JDK1.5版本,因些对于JDK1.4的项目,可以采用json-lib来解析JSON数据。如下是http请求的另外一种写法,仅供参考。
package com;
import java.util.HashMap;
import java.util.Map;
import
- 【RPC框架Hessian四】Hessian与Spring集成
bit1129
hessian
在【RPC框架Hessian二】Hessian 对象序列化和反序列化一文中介绍了基于Hessian的RPC服务的实现步骤,在那里使用Hessian提供的API完成基于Hessian的RPC服务开发和客户端调用,本文使用Spring对Hessian的集成来实现Hessian的RPC调用。
定义模型、接口和服务器端代码
|---Model
&nb
- 【Mahout三】基于Mahout CBayes算法的20newsgroup流程分析
bit1129
Mahout
1.Mahout环境搭建
1.下载Mahout
http://mirror.bit.edu.cn/apache/mahout/0.10.0/mahout-distribution-0.10.0.tar.gz
2.解压Mahout
3. 配置环境变量
vim /etc/profile
export HADOOP_HOME=/home
- nginx负载tomcat遇非80时的转发问题
ronin47
nginx负载后端容器是tomcat(其它容器如WAS,JBOSS暂没发现这个问题)非80端口,遇到跳转异常问题。解决的思路是:$host:port
详细如下:
该问题是最先发现的,由于之前对nginx不是特别的熟悉所以该问题是个入门级别的:
? 1 2 3 4 5
- java-17-在一个字符串中找到第一个只出现一次的字符
bylijinnan
java
public class FirstShowOnlyOnceElement {
/**Q17.在一个字符串中找到第一个只出现一次的字符。如输入abaccdeff,则输出b
* 1.int[] count:count[i]表示i对应字符出现的次数
* 2.将26个英文字母映射:a-z <--> 0-25
* 3.假设全部字母都是小写
*/
pu
- mongoDB 复制集
开窍的石头
mongodb
mongo的复制集就像mysql的主从数据库,当你往其中的主复制集(primary)写数据的时候,副复制集(secondary)会自动同步主复制集(Primary)的数据,当主复制集挂掉以后其中的一个副复制集会自动成为主复制集。提供服务器的可用性。和防止当机问题
mo
- [宇宙与天文]宇宙时代的经济学
comsci
经济
宇宙尺度的交通工具一般都体型巨大,造价高昂。。。。。
在宇宙中进行航行,近程采用反作用力类型的发动机,需要消耗少量矿石燃料,中远程航行要采用量子或者聚变反应堆发动机,进行超空间跳跃,要消耗大量高纯度水晶体能源
以目前地球上国家的经济发展水平来讲,
- Git忽略文件
Cwind
git
有很多文件不必使用git管理。例如Eclipse或其他IDE生成的项目文件,编译生成的各种目标或临时文件等。使用git status时,会在Untracked files里面看到这些文件列表,在一次需要添加的文件比较多时(使用git add . / git add -u),会把这些所有的未跟踪文件添加进索引。
==== ==== ==== 一些牢骚
- MySQL连接数据库的必须配置
dashuaifu
mysql连接数据库配置
MySQL连接数据库的必须配置
1.driverClass:com.mysql.jdbc.Driver
2.jdbcUrl:jdbc:mysql://localhost:3306/dbname
3.user:username
4.password:password
其中1是驱动名;2是url,这里的‘dbna
- 一生要养成的60个习惯
dcj3sjt126com
习惯
一生要养成的60个习惯
第1篇 让你更受大家欢迎的习惯
1 守时,不准时赴约,让别人等,会失去很多机会。
如何做到:
①该起床时就起床,
②养成任何事情都提前15分钟的习惯。
③带本可以随时阅读的书,如果早了就拿出来读读。
④有条理,生活没条理最容易耽误时间。
⑤提前计划:将重要和不重要的事情岔开。
⑥今天就准备好明天要穿的衣服。
⑦按时睡觉,这会让按时起床更容易。
2 注重
- [介绍]Yii 是什么
dcj3sjt126com
PHPyii2
Yii 是一个高性能,基于组件的 PHP 框架,用于快速开发现代 Web 应用程序。名字 Yii (读作 易)在中文里有“极致简单与不断演变”两重含义,也可看作 Yes It Is! 的缩写。
Yii 最适合做什么?
Yii 是一个通用的 Web 编程框架,即可以用于开发各种用 PHP 构建的 Web 应用。因为基于组件的框架结构和设计精巧的缓存支持,它特别适合开发大型应
- Linux SSH常用总结
eksliang
linux sshSSHD
转载请出自出处:http://eksliang.iteye.com/blog/2186931 一、连接到远程主机
格式:
ssh name@remoteserver
例如:
ssh
[email protected]
二、连接到远程主机指定的端口
格式:
ssh name@remoteserver -p 22
例如:
ssh i
- 快速上传头像到服务端工具类FaceUtil
gundumw100
android
快速迭代用
import java.io.DataOutputStream;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOExceptio
- jQuery入门之怎么使用
ini
JavaScripthtmljqueryWebcss
jQuery的强大我何问起(个人主页:hovertree.com)就不用多说了,那么怎么使用jQuery呢?
首先,下载jquery。下载地址:http://hovertree.com/hvtart/bjae/b8627323101a4994.htm,一个是压缩版本,一个是未压缩版本,如果在开发测试阶段,可以使用未压缩版本,实际应用一般使用压缩版本(min)。然后就在页面上引用。
- 带filter的hbase查询优化
kane_xie
查询优化hbaseRandomRowFilter
问题描述
hbase scan数据缓慢,server端出现LeaseException。hbase写入缓慢。
问题原因
直接原因是: hbase client端每次和regionserver交互的时候,都会在服务器端生成一个Lease,Lease的有效期由参数hbase.regionserver.lease.period确定。如果hbase scan需
- java设计模式-单例模式
men4661273
java单例枚举反射IOC
单例模式1,饿汉模式
//饿汉式单例类.在类初始化时,已经自行实例化
public class Singleton1 {
//私有的默认构造函数
private Singleton1() {}
//已经自行实例化
private static final Singleton1 singl
- mongodb 查询某一天所有信息的3种方法,根据日期查询
qiaolevip
每天进步一点点学习永无止境mongodb纵观千象
// mongodb的查询真让人难以琢磨,就查询单天信息,都需要花费一番功夫才行。
// 第一种方式:
coll.aggregate([
{$project:{sendDate: {$substr: ['$sendTime', 0, 10]}, sendTime: 1, content:1}},
{$match:{sendDate: '2015-
- 二维数组转换成JSON
tangqi609567707
java二维数组json
原文出处:http://blog.csdn.net/springsen/article/details/7833596
public class Demo {
public static void main(String[] args) { String[][] blogL
- erlang supervisor
wudixiaotie
erlang
定义supervisor时,如果是监控celuesimple_one_for_one则删除children的时候就用supervisor:terminate_child (SupModuleName, ChildPid),如果shutdown策略选择的是brutal_kill,那么supervisor会调用exit(ChildPid, kill),这样的话如果Child的behavior是gen_