1. 论文相关
ICLR 2018

2.摘要
2.1 摘要
我们提出在一个部分观测的图形模型(partially observed graphical model)上,用推理的棱镜(prism of inference)来研究由一组输入图像构成的小样本学习问题,这些图像的标签可以观测也可以不观测。通过将一般的消息传递推理算法与相应的神经网络算法相结合,我们定义了一种图神经网络结构,它概括了最近提出的几种小样本学习模型。除了提供改进的数值性能外,我们的框架很容易扩展到小样本学习的变体,例如半监督学习或主动学习(semi-supervised or active learning),证明了基于图的模型在“关系”任务上的良好操作能力。
2.2 主要贡献
总的来说,我们的贡献如下:
(1)我们将小样本学习作为一个有监督的消息传递任务,使用图神经网络进行端到端的训练。
(2)我们使用较少的参数匹配Omniglot和Mini Imagenet任务的最新性能。
(3)我们在半监督和主动学习机制中扩展了该模型。
2.3 相关工作
(1)
3.问题设置
我们首先描述了一般的设置和符号,然后将其具体化为小样本学习、半监督学习和主动学习。
我们考虑从部分标记的图像集合的分布中得到的独立同分布(independent and identically distributed,iid)输入输出对:
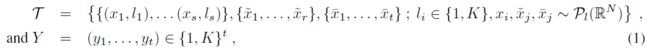
对于s,r,t和K的任意值。其中s是标记样本数,r是未标记样本数(在半监督和主动学习场景,r>0),t是要分类的样本数。K是类的数目。我们将专注于t=1的情况,即我们只对每个任务T的一个样本进行分类。表示R上的类特定图像分布(class-specific image distribution)。在我们的上下文中,目标与指定图像的图像类别相关联,没有观察到的标签。给定一个训练集,我们考虑标准的监督学习目标:
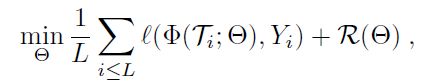
使用第4节规定的模型,R中是标准正则化目标(standard regularization
objective)。
小样本学习(Few-Shot Learning)
当r=0和t=1,s=qK时,集合中有一个标签未知的图像。此外,如果每个标签出现正好q次,则此设置称为q-shot, K-way learning。
半监督学习(Semi-Supervised Learning)
当r>0和t=1时,输入集合包含辅助图像,该模型可以用来提高预测精度,通过利用这些样本是从共同分布中抽取的事实作为确定输出的事实。
主动学习(Active Learning)
在主动学习环境中,学习器能够从子集合获取标签。我们感兴趣的是研究这种主动学习在多大程度上可以改善相对于先前半监督设置的性能,并将单样本学习设置的性能与已知标签的相匹配()。
4. 模型(MODEL)
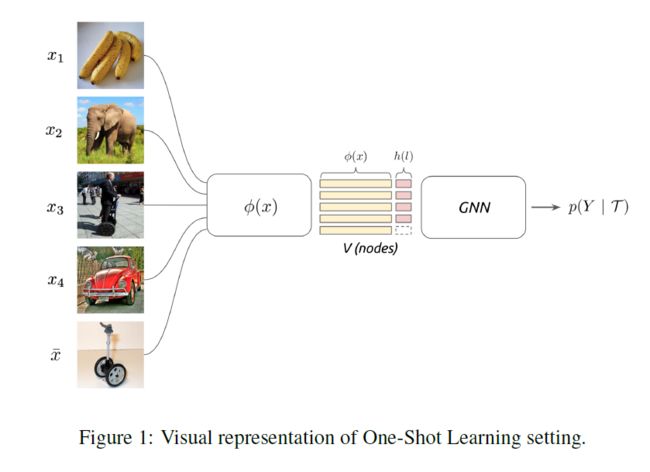
本节介绍了我们的方法,基于一个简单的端到端图神经网络架构。我们首先解释如何将输入上下文(input context)映射到图形表示(graphical representation)中,然后详细说明该体系结构,然后展示该模型如何泛化先前发布的一些小样本学习体系结构。
4.1 集合与图形输入表示(SET AND GRAPH INPUT REPRESENTATIONS)
输入T包含一组有标签和无标签的图像。小样本学习的目的是将标签信息从标签样本传播到未标签查询图像。这种信息传播可以形式化为对由输入图像和标签确定的图形模型的后验推理(posterior inference)。
在最近的几项工作中,通过在Scarselli(2009)Duvenaud(2015)Gilmer(2017年)等人的图上定义的神经网络传递信息来进行后验推理。我们将T与全连通图相关联,其中节点对应于T中存在的图像(标记的和未标记的)。在这种情况下,设置并没有指定图像和之间的固定相似性,这表明了一种方法,这种相似性度量是以判别的方式学习的,其参数模型与Gilmer等人的方法类似,比如孪生神经结构。这个框架与Vinyals等人(2016)的集合表示密切相关,但使用我们接下来详述的图神经网络形式主义扩展了推理机制。
4.2 图神经网络(GRAPH NEURAL NETWORKS)
图神经网络,在Gori等人中介绍(2005);斯卡塞利等人(2009)并在Li等人(2015)中进一步简化。;Duvenaud等人(2015);Sukhbaatar等人(2016)基于图的局部算子的神经网络,在表现性和样本复杂度之间提供了强大的平衡;参见Bronstein等人(2017)关于深度学习在图上的模型和应用的最新调查。
在其最简单的体现形式中,给定一个输入信号为一个加权图G的顶点,我们考虑一个图的内在算子族(graph intrinsic linear operators)A,它对该信号起局部作用。最简单的是邻接算子,

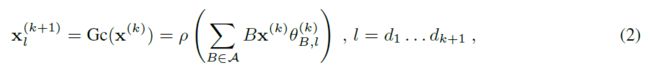
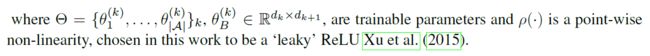
作者从这一基本公式中探索了几种建模变体,用门操作替换了点态非线性(pointwise nonlinearity with gating operations),或者将生成器族推广到拉普拉斯多项式,或包括对A的2J次方,来编码每个节点的跳邻居(encode -hop neighborhoods)。形式(2)中的级联操作能够近似范围广泛的图推断任务。特别是,受到消息传递算法的启发,推广GNN,从当前节点隐藏表示中学习边缘特征:

其中φ是用神经网络等参数化的对称函数。在这项工作中,我们考虑一个多层感知器堆叠在两个向量节点之间的绝对差之后。见公式4:
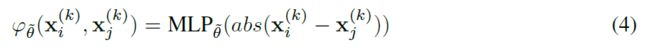
然后φ是一个度量,它是通过对两个节点的各个特征之间的绝对差进行非线性组合来学习的。使用这种结构,距离特性对称性通过构造实现,距离特性恒等式很容易学习。
然后,通过沿每一行使用softmax将可训练邻域规范化为随机核。通过将边特征内核添加到生成器族中并应用(2),获得节点特征的更新规则。邻接学习在输入集被认为具有某种几何结构的应用中尤其重要,但是度量是先验的,例如我们的例子。
在一般的图中,网络深度被选择为图直径的阶数(the order of the graph diameter),以便所有节点从整个图中获取信息。然而,在我们的上下文中,由于图是紧密连接的,因此深度被简单地解释为赋予模型更大的表达能力。
初始节点特征的构造(Construction of Initial Node Features)
输入集合T映射为节点特征,如下所示。对于标签已知的图像,在GNN的输入端,将标签的独热编码与图像的嵌入特征连接起来。

是一种卷积神经网络,是一种独热编码的标签。的架构细节详见第6.1.1节和第6.1.2节。对于带有未知标签的图像,,我们修改了先前的结构,通过用单纯形上的均匀分布K-simplex: 替换和类似的来考虑标签变量的完全不确定性。

4.3 与现有模型的关系(RELATIONSHIP WITH EXISTING MODELS)
小样本学习的图神经网络公式推广了文献中最近提出的一些模型。
暹罗网络(Siamese Networks)
暹罗网络可以理解为我们模型的单层消息传递迭代(single layer message-passing iteration),并使用相同的初始节点嵌入,使用不可训练的边特征

以及由此产生的标签估计

从x中选择标签字段u。在该模型中,学习减少到学习图像嵌入,其欧几里得度量与标签相似性是一致的。
原型网络(Prototypical Networks)
原型网络通过在每个集群内聚合由具有相同标签的节点确定的信息来进化暹罗网络。这个操作也可以用gnn完成,如下所示。我们考虑
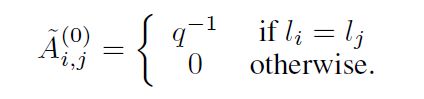
其中q是每个类的示例数,以及:
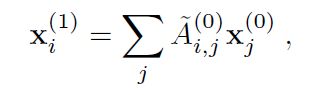
其中和暹罗网络的定义一样。我们最后将先前的kernel 应用于产生类原型:

匹配网络
匹配网络Vinyals等人对T中的图像集合使用集合表示,类似于我们提出的图神经网络模型,但有两个重要区别。首先,该集合表示中考虑的注意机制类似于边缘特征学习,不同之处在于该机制总是关注相同的节点嵌入,而我们的叠层邻接学习更接近Vaswani等人。换句话说,匹配网络不考虑(3)中的注意力核心,而是考虑注意力(T)形式的机制,其中是用双向LSTMs获得的支持集元素的编码函数。在这种情况下,支持集编码因此独立于目标图像来计算。其次,标签和图像字段在整个模型中分别处理,最后一步是使用经过训练的内核线性聚合标签。这可能会阻止模型在中间阶段利用标签和图像之间的复杂依赖关系。
5 训练
接下来我们将描述如何在我们考虑的不同设置中训练GNN的参数:小样本学习、半监督学习和主动学习。
5.1 小样本和半监督学习
在这种设置中,模型只要求预测与图像对应的标签,以对与图中节点关联的图像进行分类。因此,GNN的最后一层是将节点特征映射到K-simplex的softmax。然后我们考虑在节点*处评估的交叉熵损失:

半监督设置的训练是相同的,唯一的区别是节点的初始标签字段将填充对应于的节点上的均匀分布。
5.2 主动学习
在主动学习设置中,该模型具有内在的能力,可以从{x●1,…,x●r}查询其中一个标签。网络将学会要求信息量最大的标签,以便对样本进行分类十. 查询是在GNN的第一层之后通过对图的未标记节点使用Softmax注意来完成的。为此,我们应用一个将每个未标记的向量节点映射到标量值的函数。功能克由两层神经网络参数化。Softmax应用于在应用以下命令后获得的{1,…,r}标量值:
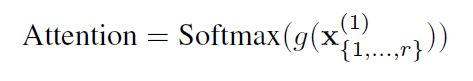
为了只查询一个样本,我们将∈Rvector中除一个外的所有元素设置为0。在测试时间,我们保持最大值,在训练时,我们根据它的多项式概率随机抽样一个值。然后我们将这个采样的注意力乘以标签向量:
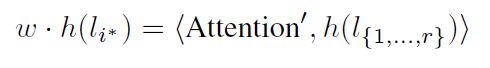
得到查询向量(li∗)的标签,按权重∈(0,1)缩放。然后将此值相加为当前表示形式小时西十[图片上传失败...(image-f21520-1573458140427)] ,因为我们在GNN模型中使用的是密集连接,所以我们可以将这个h(li∗)值直接求和到统一标签分布连接的位置西

将标签汇总到当前节点后,信息将向前传播。该注意部分通过反向传播GNN输出的损失,与网络的其他部分端到端地进行训练。
6. 实验
对于小样本、半监督和主动学习实验,我们使用了Lake等人提出的Omniglot数据集和Vinyals等人引入的Mini Imagenet数据集,Mini Imagenet是ILSVRC-12的小版本。所有的实验都是基于q-shot,K-way方式设置的。在所有的实验中,我们都使用相同的值q-shot,K-way进行训练和测试。
代码位于:https://github.com/vgsatorras/lew-shot-gnn
6.1 数据集和实现
6.1.1 OMNIGLOT
数据集:Omniglot是一个由50个不同字母表的1623个字符组成的数据集,每个字符/类由20个不同的人绘制。以下是Vinyals等人实施我们将数据集分成1200个培训类和423个测试类。根据Santoro等人的建议,我们将数据集增加了90度的倍数。
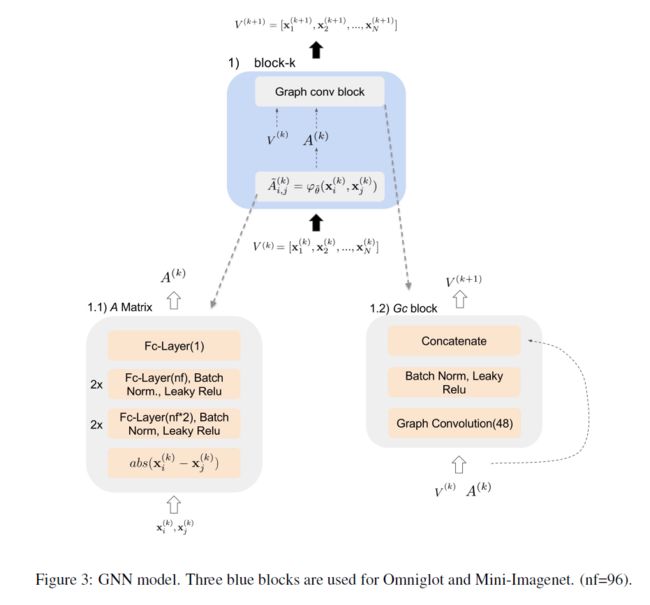
架构:灵感来源于Vinyals等人的嵌入式架构,根据Mishra等人使用CNN作为嵌入函数,由4个堆叠的{ 3×3-卷积层块(带64个滤波器)、批量规范化、2×2最大池、leaky-relu}组成。输出通过一个完全连接的层,从而实现64维嵌入。对于GNN,我们使用3个块,每个块由1)计算邻接矩阵的模块和2)图形卷积层组成。在图3中可以找到每个块的更详细描述。
6.1.2 MINI-IMAGENET
数据集:Mini-Imagenet是Vinyals等人提出的一种更具挑战性的一次性学习数据集,源于原始ILSVRC-12数据集。它包括来自100个不同类别的84×84 RGB图像,每个类别600个样本。它创建的目的是增加单样本识别任务的复杂性,同时保持轻量数据集的简单性,这使得它适合于快速原型。我们使用了Ravi&Larochelle(2016)提出的64个培训类、16个验证类和20个测试类。使用64个类进行训练,16个验证类仅用于早期停止和参数调整。
体系结构:用于Mini Imagenet的嵌入体系结构由4个卷积层和一个全连接层构成,形成128维的嵌入。这种轻型结构对于快速原型设计非常有用:

在Mini-Imagenet数据集中,这两个 dropout层有助于避免GNN过拟合。GNN体系结构与Omniglot上的类似,它由3个块组成,每个块如图3所示。
6.2 FEW-SHOT
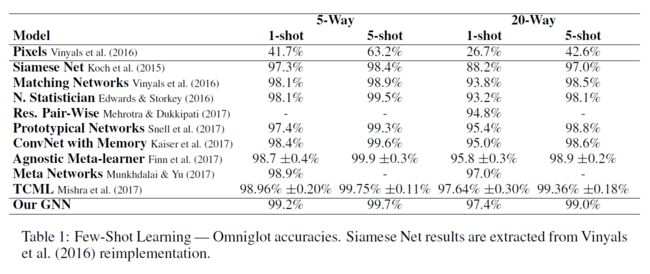
Omniglot和Mini Imagenet的小样本学习实验分别见表1和表2。
我们通过对两个数据集进行不同的q-shot, K-way实验来评估我们的模型。对于每个小样本任务T,我们从数据集中抽取K个随机类,从每个类中抽取q个随机样本。从K个类中选择一个额外的样本进行分类。
Omniglot:GNN方法在提供竞争性结果的同时仍然比其他方法简单。在5-Way and 20-way 1-shot实验中取得了最先进的结果。与Munkhdalai&Yu(2017年)相比,在20-Way 1-shot设置中,GNN提供了稍好的效果,同时仍然是一种更简单的方法。Mishra等人的TCML方法对于4个实验中的3个,处于相同的置信区间,但对于20-Way 5-shot则稍好,尽管参数的数量从∼5M(TCML)减少到∼300K(3层GNN)。
在Mini Imagenet表中,我们还提供了一个基线“我们的度量学习+KNN”,其中节点之间没有聚合任何信息,它是应用于成对可学习度量和端到端训练之上的K近邻,与其他最新方法相比,此可学习度量本身具有竞争力。即使如此,当使用完整的GNN架构在节点之间聚合信息时,5-shot 5-Way Mini-Imagenet设置仍有显著的改进(从64.02%到66.41%)。各种嵌入函数φ在我们的例子中,我们使用了一个简单的网络,由4个卷积层和一个全连接层组成(第6.1.2节),这有助于我们比较GNN和metric learning+KNN,这对于快速成型很有用。在Mishra等人的研究中,更复杂的嵌入已经证明能产生更好的效果。采用深度残差网络作为嵌入网络,大大提高了精度。对于Mini-Imagenet中的TCML架构,参数的数目从∼11M(TCML)减少到∼400K(3层GNN)。

6.3 半监督
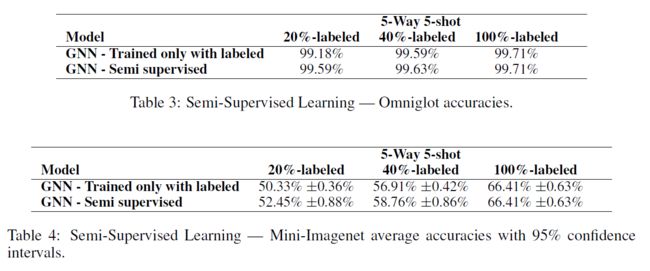
半监督实验是在5路5炮设置。当20%和40%的样品被标记时,会出现不同的结果。在所有的实验中,标记样本在类之间是平衡的,也就是说,所有的类都有相同数量的标记样本和未标记样本。
在表3和表4中可以看到两种策略。“GNN-只训练带标签”相当于有监督的少镜头设置,例如,在5路5拍20%标签设置中,由于忽略了未标记的样本,该方法相当于5路1拍学习设置。“GNN-半监督”是实际的半监督方法,例如,在5路5拍20%标记设置中,GNN接收每个类1个标记样本和每个类4个未标记样本作为输入。
Omniglot的结果如表3所示,对于这种情况,我们观察到添加图像时的精度提高与添加标签时的精度提高相似。GNN能够从未标记样本的输入分布中提取信息,因此在5次半监督环境中仅使用20%的标签,我们就可以得到与40%监督环境中相同的结果。
在Mini Imagenet实验中,表4中,我们还注意到使用半监督数据时的改进,尽管它不如Omniglot中的显著。与Omniglot相比,Mini-Imagenet图像的分布更为复杂。尽管如此,在20%和40%的设置下,GNN还是设法提高了2%。
6.4 主动学习
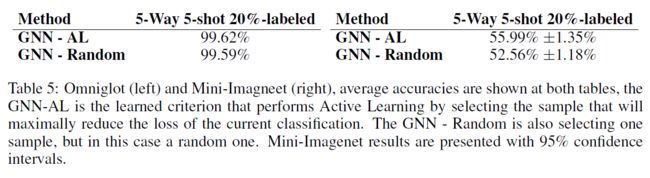
当20%的样本被标记时,我们在5路5投装置上进行了主动学习实验。在这种情况下,我们的网络将从未标记的样本中查询一个样本的标签。将结果与随机选择的基线进行比较,其中网络选择要标记的随机样本,而不是最大限度地减少分类任务T的丢失的随机样本。
结果见表5。GNN随机准则的结果与表3和表4中20%标记样本的半监督结果接近。这意味着选择一个随机标签实际上根本不能提高准确性。当使用GNN-AL学习准则时,我们注意到Mini-Imagenet的∼3.4%的改进,这意味着GNN能够正确地选择比随机样本信息量更多的样本。在Omniglot中,由于精度几乎饱和,提高的幅度较小,因此改进的幅度较小。
7 结论
本文探讨了用于小样本、半监督和主动学习的图神经表示方法。从元学习的角度来看,这些任务成为有监督的学习问题,其中输入由一组或一组元素给出,这些元素的关系结构可用于神经信息传递模型。特别是,堆叠的节点和边特征概括了背景相似性学习的基础上先前的小样本学习模型。
图公式有助于在同一框架下统一多个训练设置(小样本、主动、半监督),这是朝着让一个学习器能够在不同的区域(每个类只有几个例子的标签流,或只有几个标签的示例流)同时操作的目标迈出的必要一步。这个总体目标需要将图模型扩展到数百万个节点,激发图层次化和粗化方法。
另一个未来的方向是泛化主动学习的范围,包括提问的能力,或者在强化学习设置中,小样本学习对适应非平稳环境至关重要。
参考资料
[1] [2018][ICLR]FEW-SHOT LEARNING WITH GRAPH NEURAL NETWORKS 论文笔记 特别好,配合代码,便能明白论文的思路
[2] Few-Shot Learning with Graph Neural Networks
[3] FEW-SHOT LEARNING WITH GRAPH NEURAL NETWORKS 论文笔记
论文下载
[1] Few-Shot Learning with Graph Neural Networks
代码
[1] vgsatorras/few-shot-gnn