C++ 11引入了大量非常有用的特性,使代码更直观、安全、简洁、方便。
此处列举的仅是一部分较常用的特性,完整的列表还需参考官方文档或者微软的文档:Support For C++11/14/17 Features (Modern C++)
初始化列表 Initializer List
所有STL容器都支持初始化列表,如下:
std::vector v = { 1, 2, 3 };
std::list l = { 1, 2, 3 };
std::set s = { 1, 2, 3 };
std::map m = { {1, "a"}, {2, "b"} };
在自定义class上支持初始化列表
#include
class A {
public:
B(const std::initializer_list& items)
: m_items(items)
{}
private:
std::vector m_items;
};
A a1 = { 1, 2, 3 };
// 或者
A a2{ 1, 2, 3 };
统一的初始化方法 Uniform Initialization
可以统一使用大括号{}进行初始化。对构造函数的选择的优先级如下:
class A {
public:
// first choice
A(const std::initializer_list& v) : age(*v.begin())
{}
// second choice
A(int age) : age(age)
{}
// third choice
int age;
};
A a{ 5 };
上面的调用会选择带初始化列表的构造函数。
class A {
public:
A() {}
int age;
};
A a{ 5 };
这个代码会编译出错。因为存在构造函数,但函数签名又不匹配。换言之,只要存在自定义的构造函数,就要求至少有一个构造函数的参数列表与大括号中的参数完全匹配,才能使用这种方式初始化。
类型推导 Auto Type
过去的这种冗长的类型声明
std::map::const_iterator itr = m.find(1);
现在可以写成这样了
auto itr = m.find(1);
编译器会自动推导出正确的类型。字面量也可以:
auto i = 1; // int
auto d = 1.1; // double
auto s = "hi"; // const char*
auto a = { 1, 2 }; // std:: initializer_list
如果是用Visual Studio,把鼠标悬停在变量名上方,可以看到推导后的类型名称。类型推导对于泛型编程非常方便,比如:
template
auto add(T a, K b) {
return a + b;
}
auto a = add(1, 2); // int add(int, int)
auto b = add(1, 2.2); // double add(int, double)
留意第二个调用,返回值被正确地推断为double类型。
遍历 foreach
以前遍历vector一般是这么写的
for (std::vector::const_iterator itr = v.begin(); itr != v.end(); ++itr) {
std::cout << *itr << std::endl;
}
这样写有两个缺点:
- 迭代器声明很冗长 (用
auto可以部分解决) - 循环内部必须对迭代器解引用(主要是难看)
可以使用的新的遍历方式:
for (int i : v) {
std::cout << i << std::endl;
}
代码立马简洁了许多。但是要注意,这里每次循环,会对i进行一次拷贝。此处i是一个int值,拷贝不会造成问题,但是如果是一个class,我们就更希望用引用的方式进行遍历,一般写成:
std::vector v = { "a", "b" };
for (auto& s : v) {
std::cout << s << std::endl;
}
用auto&即可以变成引用方式遍历,甚至还能在循环中改变它的值。也可以使用const auto&,只是一般没有必要。
空指针 nullptr
以往我们使用NULL表示空指针。它实际上是个为0的int值。下面的代码会产生岐义:
void f(int i) {} // chose this one
void f(const char* s) {}
f(NULL);
为此C++ 11新增类型nullptr_t,它只有一个值nullptr。上面的调用代码可以写成:
void f(int i) {}
void f(const char* s) {} // chose this one
f(nullptr);
强类型枚举 enum class
原来的enum有两个缺点:
- 容易命名冲突
- 类型不严格
如下代码:
enum Direction {
Left, Right
};
enum Answer {
Right, Wrong
};
此代码编译报错:Right重定义。这里使用了单个单词作为名称,很容易出现冲突。所以我们一般加个前缀,变成:
enum Direction {
Direction_Left, Direction_Right
};
enum Answer {
Answer_Right, Answer_Wrong
};
这样写很难看,而且如果这两个枚举是分别从两个第三方库引入的,那就无法自己改名字了。而且改成这样依然有个问题:
auto a = Direction_Left;
auto b = Answer_Right;
if (a == b)
std::cout << "a == b" << std::endl;
else
std::cout << "a != b" << std::endl;
这个代码将输出a == b,因为这两上值都为0。然而允许两个不同类型的值作比较,就是不合理的,容易隐藏一些bug。
C++ 11引入了enum class:
enum class Direction {
Left, Right
};
enum class Answer {
Right, Wrong
};
auto a = Direction::Left;
auto b = Answer::Right;
if (a == b)
std::cout << "a == b" << std::endl;
else
std::cout << "a != b" << std::endl;
- 引用时必须加上枚举名称(
Direction_Left变成Direction::Left),似乎写法上差不多,但是这样类型更加严格。下面的a == b编译将会报错,因为它们是不同的类型。 - 枚举值不再是全局的,而是限定在当前枚举类型的域内。所以使用单个单词作为值的名称也不会出现冲突。
静态断言 static assert
static_assert可在编译时作判断。
static_assert( size_of(int) == 4 );
构造函数的相互调用 delegating constructor
同一个class的多个构造函数的内部实现通常非常相似,比如:
class A {
public:
A(int x, int y, const std::string& name) : x(x), y(y), name(name) {
if (x < 0 || y < 0)
throw std::runtime_error("invalid coordination");
// other stuff
}
A(int x, int y) : x(x), y(y), name("A") {
if (x < 0 || y < 0)
throw std::runtime_error("invalid coordination");
// other stuff
}
A() : x(0), y(0), name("A") {
// other stuff
}
private:
int x;
int y;
std::string name;
};
为了避免重复代码,通常会把共同的代码挪到一个init成员函数里:
class A {
public:
A(int x, int y, const std::string& name) {
init(x, y, name);
}
A(int x, int y) {
init(x, y, "A");
}
A() {
init(0, 0, "A");
}
private:
void init(int x, int y, const std::string& name) {
if (x < 0 || y < 0)
throw std::runtime_error("invalid coordination");
this->x = x;
this->y = y;
if (name.empty())
throw std::runtime_error("empty name");
this->name = name;
// other stuff
}
private:
int x;
int y;
std::string name;
};
这样写有三个问题:
- 二次赋值。执行到
init函数时,数据成员实际已经初始化了。比如name成员,此时已经初始化为一个空字符串了。这里实际上是又调用了一次“=”操作符。对于初始化成本比较高的类型,这样做就有可能影响性能了。 - 只能调用成员的无参构造函数。只有构造函数的初始化列表才能调用成员的带参数构造函数。
- 无法保证
init只被调用一次。有些初始化步骤必须保证只被执行一次,这一点只有构造函数可以保证。
C++ 11允许构造函数之间相互调用了:
class A {
public:
A(int x, int y, const std::string& name) : x(x), y(y), name(name) {
if (x < 0 || y < 0)
throw std::runtime_error("invalid coordination");
if (name.empty())
throw std::runtime_error("empty name");
// other stuff
}
A(int x, int y) : A(x, y, "A")
{}
A() : A(0, 0)
{}
private:
int x;
int y;
std::string name;
};
除了优雅地解决了上述三个问题之外,代码也简洁了许多,连name成员的默认值"A"也只需要写一次。
禁止重写 final
- 禁止虚函数被重写
class A {
public:
virtual void f1() final {}
};
class B : public A {
virtual void f1() {}
};
此代码编译报错,提示不能重写f1。虽然f1是虚函数,但是因为有final关键字,保证它不会被重写。你可能会说,那不声明virtual不就完了。但是如果A本身也有基类,f1是继承下来的,那virtual就是隐含的了。
- 禁止类被继承
class A final {
};
class B : public A {
};
此代码编译报错,提示不能继承A。
显式声明重写 override
class A {
public:
virtual void f1() const {}
};
class B : public A {
virtual void f1() {}
};
上面的代码在重写函数f1时不小心漏了const,但是编译器不会报错。因为它不知道你是要重写f1,而认为你是定义了一个新的函数。这样的情况也发生在基类的函数签名变化时,子类如果没有全部统一改过来,编译器也不能发现问题。
C++ 11引入了override声明,使重写更安全。
class B : public A {
virtual void f1() override {}
};
此时编译报错,提示找不到重写的函数。
定义成员初始值
当我们为一个class增加成员变量时,要注意在所有构造函数中都对它进行初始化(除非这个成员的默认构造函数就满足我们的要求)。虽然C++ 11允许构造函数相互调用,但至少该成员变量的声明和初始化是分开写的,导致后者经常被遗忘。现在C++ 11可以在声明成员变量的时直接赋初始值。
class A {
public:
int m = 1;
};
这个初始化的动作会在所有构造函数之前执行,可以理解为这些初始值会被自动放到初始化列表。如果初始化列表也有个初始化,则选用初始化列表的值。
class A {
public:
A() : m(2)
{}
int m = 1; // 这个1被忽略
};
那实际上m会不会是先被初始化为1,再被改为2呢(二次赋值)?我们用一个自定义的类作为成员变量:
class M {
public:
M(int i) : i(i) {
std::cout << "M(" << i << ")" << std::endl;
}
M(const M& other) : i(other.i) {
std::cout << "copy M(" << i << ")" << std::endl;
}
M& operator = (const M& other) {
i = other.i;
std::cout << "= M(" << i << ")" << std::endl;
return *this;
}
private:
int i;
};
class A {
public:
A() : m(1)
{}
private:
M m = M(2);
};
A a;
我们为M实现了三件套(构造函数,复制构造函数,赋值操作符),并打印出信息,这样我们可以知道具体发生了什么。运行结果:
M(1)
说明下面的M(2)直接被忽略了。
默认构造函数 default
当一个class有自定义构造函数时,编译器就不会自动生成一个无参构造函数。现在可以通过default关键字强制要求生成这个构造函数。
class A {
public:
A(int i) {}
A() = default;
};
当然,你也可以直接写成
A() {}
但用default意图更加明确,编译器也可以相应地做优化。
删除构造函数 delete
以往,当我们需要隐藏构造函数时,可以把它声明为private成员
class A {
private:
A();
};
现在可以使用delete关键字
class A {
public:
A() = delete;
};
常量表达式 constexpr
int size() { return 3; }
int a[size()];
上面的代码编译失败,因为静态数组的大小必须在编译期确定。改成:
constexpr int size() { return 3; }
int a[size()];
加上了constexpr,函数size变成在编译期计算,返回值被看成一个常量。
字符串字面量
const char* a = "string a";
const char* b = u8"string b"; // UTF-8
const char16_t* c = u"string c"; // UTF-16
const char32_t* d = U"string d"; // UTF-32
const char* e = R"(string e1 "\\
stirng e2)"; // raw string
std::cout << a << std::endl;
std::cout << b << std::endl;
std::cout << c << std::endl;
std::cout << d << std::endl;
std::cout << e << std::endl;
输出结果:
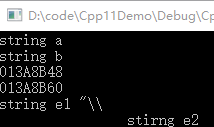
第1、2行没问题;第3、4行实际是打印出了内存地址,因为
std::cout不支持这两种类型。
第5种比较有意思,它是忽略了转义符的字符串。从这个例子可以看到:
- 它的格式是
R"(...)",中间的...是内容。 - 内容可以出现
"符号而不会截断字符串。 - 转义符
\被当成一个字符 - 换行也被当成字符串的内容(如果要忽略换行符,则在换行前使用
\连接符)。 - 缩进也被当成内容。
利用这个特性,这样的代码:
auto xml = "\n"
"\t- \n"
"\t
- \n"
"
";
就可以直接写成:
auto xml = R"(
-
-
)";
不足之处就是会破坏代码的缩进,因为缩进也被看成是字符串的内容。
Lambda函数
这是个非常强大的重量级功能。简单地讲,就是可以用它定义一个临时的函数对象,它像其它对象一样可以传递和保存。更为强大的是,它甚至可以访问当前函数的上下文。
特性
- 调用
auto add = [](int a, int b) { return a + b; };
std::cout << add(1, 2) << std::endl;
-
=后面的部分就是Lambda函数。先忽略前面的[]。()里面的是参数列表,{}里面的是实现。跟普通的函数基本一样。 - 这里没有声明返回值类型,编译器会根据
return语句推导。如果有多个return语句,而且类型不一样,则会报错。 - 使用方式与普通函数一样。
- 传递
template
void print(const std::vector& v, filter_func filter) {
for (auto i : v) {
if (filter(i))
std::cout << i << std::endl;
}
}
bool isGreaterThanTen(int i) {
return i > 10;
}
class GreaterThanTenFilter {
public:
bool operator()(int i) {
return i > 10;
}
};
std::vector v = { 5, 10, 15, 20 };
print(v, isGreaterThanTen); // 输出 15 20
print(v, GreaterThanTenFilter()); // 输出 15 20
以上代码分别使用了函数指针和函数对象来指定过滤条件。这两种方式存在以下缺点:
- 代码冗余。需要单独定义一个函数或
class才能实现。 -
filter_func的类型不明确。此处filter_func是一个参数为一个int,返回值为bool型的函数。但是这一点无法从函数声明看出来。并且函数对象使用()操作符语义也不明确。 -
print函数必须使用模板。虽然print内部并没有使用泛型的必要,但是考虑到兼容函数指针和函数对象的用法,也只能使用模板实现。 - 不灵活。如果这个
10是一个运行时才确定的数字n,就需要修改函数对象才能实现。(函数指针无法实现)
使用Lambda:
#include
void print(const std::vector& data, std::function filter) {
for (auto i : data) {
if (filter(i))
std::cout << i << std::endl;
}
}
std::vector v = { 5, 10, 15, 20 };
print(v, [](int i) { return i > 10; }); // 输出 15 20
解决了上面提到的几个问题:
- 代码简洁。无需另外定义函数或
class即可实现。整体代码缩小了不少。 - 类型明确。新增的
std::function是一个通用的函数对象,可以使用Lambda初始化。最大的优点是参数和返回值都是明确的,可以从声明看出来。 - 无须使用模板。
- 更灵活。这一点接下来讲。
- 可以访问当前函数的上下文
上面的例子如果把硬编码的10改成变量n,只需要改调用的地方:
int n = 10;
print(v, [=](int i) { return i > n; });
可以看到前面的[]改成了[=],这表示Lambda使用值传递的方式捕获外部变量。
[]表示捕获列表,用来描述Lambda访问外部变量的方式。如下:
| 捕获列表 | 作用 |
|---|---|
[a] |
a为值传递 |
[a, &b] |
a为值传递,b为引用传递 |
[&] |
所有变量都用引用传递。当前对象(即this指针)也用引用传递。 |
[=] |
所有变量都用值传递。当前对象用引用传递。 |
注意事项
- 捕获时机
int i = 1;
auto f = [=]() { std::cout << i << std::endl; };
i = 2;
f(); // 输出 1
可以看出,在定义Lambda的地方就已经捕获到i的值。后面修改i也不影响f的输出。
如果把[=]改成[&],则会输出2。因为Lambda实际上只捕获到i的引用。
- 局部变量的生命周期
std::function GetLambda() {
int i = 1;
return [&]() { std::cout << i << std::endl; };
}
auto f = GetLambda();
f(); // 输出 -858993460 之类的乱码
使用引用的方式访问局部变量时,要注意Lambda的生命周期不能超过该局部变量的生命周期。
内部实现
(待续……)
参考资料:
Learn C++ 11 in 20 Minutes - Part I
Learn C++ 11 in 20 Minutes - Part II
Support For C++11/14/17 Features (Modern C++)
Lambda 表达式