//------暂时还没没看完,边看边写,最后再重新整理格式------
前言
虽然是一本考试用书,但是知识点的归纳总结挺全面,用来知识点的查漏补缺还是不错的。相较于Effective Java和Thinking in java,这本书我应该还是能看完的。
基本大纲如下
1.声明和访问控制
2.流控制和异常处理
3.垃圾收集
4.语言基础
5.运算符和赋值
6.重载、覆盖运行时间类型和面向对象
7.线程
8.java.awt包-布局
9.java.lang包
10.java.util包
11.java.io包
8-11条
熟悉java包,以及掌握基本的包的使用。
需掌握编码的转换?编码是什么?
参考链接:
Unicode、UTF-8 和 ISO8859-1和乱码问题
https://jingyan.baidu.com/article/020278118741e91bcd9ce566.html
1.6.5题目

结果输出ClassA ClassB。
方法依赖于变量引用的实际对象类型,而不是声明的变量类型。
https://zhidao.baidu.com/question/177406692303857484.html
2.1 java编程概念
java是一个面向对象的编程语言,应该解释和描述其核心概念。
对象
类
包
封装
继承
访问控制
java编程最基本的单元是对象(Object)。
java的特性
为分布式网络而设计
为多线程而设计(多线程的关键在于线程优先级的设置)
第三章 java关键字
50个关键字
java关键字的完整列表

synchronized
表示一次只能有一个线程访问synchronized方法。
instanceof 会检验一个实例是否继承自一个特定的类或接口。
第四章 java构成块
关键字是java编程语言的一个基本构成块,其他构成块包括标识符、运算符、分隔符以及注释。这些构成块被称作标记(token)。
关键在于如何操作这些基本的构成块。
java编译器在编译时,首先检查源码,抽取标记,包括关键字、标识符、分隔符和注释。
4.2 字面值
java中,数据被称为字面值(文字)。
java使用Unicode字符集。
Unicode(统一码、万国码、单一码)。
字面值的种类
布尔(true ,false)
字符(‘a’ ,对于语言中做保留字的字符或者不能直接输入的字符必须加上转义符-反斜杠‘\'’,'\\','\u0061')
字符串("wddq")
整形(常用进制:八进制(以0开头)、十进制(不能以0开头)、十六进制(以0x或0X开头))
浮点
字符转义序列

4.3分隔符
编译器用分隔符把代码分隔成不同的段。

4.4 运算符
算数
逻辑
4.7复习题
3是OSI-Latin-1(ASCII)字符的第51个字符。如何用八进制、十进制和十六进制表示值为3的字符字面值?
'\063' (八进制) '3' (十进制) '\u0033'(十六进制)
ascii字符。
字符是如何编码的?类似于字典?
以ASCII字符值为标准?
51(十进制)转换63(八进制)。
字符3在ascii表中对应---51(十进制)63(八进制),33(十六进制)。
对于十进制,0到9之间的任何可见的ascii字符可以直接输入(字符跟字符串的区别在于字符是单个而字符串是多个数据)。
ASCII表。
https://baike.baidu.com/item/ASCII/309296?fr=aladdin
第五章 内存和垃圾收集
本章重点:
局部变量引用的对象何时适合于被收集为无用信息。
描述最终化的工作机制,以及和最终化有关的java行为。
区别修改包含简单数据类型与对象引用的变量和修改对象本身。
在传递参数给方法时识别java“传值”方法的结果
java可以管理程序的内存。目的是消除各种程序的错误。
在定义一个新的数据类型时,你可以定义一个新类。通过使用new关键字分配类的实例,这会返回一个对象引用。这个对象引用本质上是内存中该对象的一个指针,只是java中不能像操作数字一样操作这个对象引用。不能执行指针运算(java中没有指针)。
对象是从一个垃圾收集堆中分配的?。
java自动管理内存自动地解决了两个问题:
给对象分配内存
回收给对象分配的内存
这两个问题中的内存区域是指java内存模型中的堆区(JVM管理的内存包括堆内存和非堆内存)。
什么是java内存模型?
Java内存模型即Java Memory Model,简称JMM。JMM定义了Java 虚拟机(JVM)在计算机内存(RAM)中的工作方式。JVM是整个计算机虚拟模型,所以JMM是隶属于JVM的。
————JVM相关————
要理解垃圾回收首先要了解JVM内存模型。
参考资料:
全面理解Java内存模型
http://blog.csdn.net/suifeng3051/article/details/52611310
JVM 内存模型概述
java程序在执行前首先会被编译成字节码文件,然后由java虚拟机(JVM)执行这些字节码文件,从而使java程序得以执行。程序执行过程中,内存的使用和管理是重要问题。java虚拟机(jvm)在执行程序的过程中会把所管理的内存划分为若干个不同的数据区域,这些数据区域都有各自的用途和各自创建和销毁的时间(思考:数据区域的用途是什么?什么时候创建或销毁?)。
数据区域可以分成2种类型
线程共享的方法区和堆
线程私有的虚拟机栈、本地方法栈和程序计数器。
这张图是jvm的关键。

以上5个具体表示什么?
方法区
1、方法区是被所以线程共享的一块内存区域。用于存储已被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据。
2、java虚拟机规范对方法区限制非常宽松。
3、当方法区无法满足内存分配的需求时,将抛出OutOfMemoryError异常。
4、运行时常量池是方法区的一部分。
常量池是为了避免频繁的创建和销毁对象而影响系统性能,其实现了对象的共享。
堆
1、虚拟机启动时创建java堆,java堆被所以线程共享。java堆唯一的目的是存放对象实例,几乎所以对象实例都在这里分配内存。
所谓对象实例、对象、实例、对象引用概念到底是什么意思。
参考资料:
第 3 单元:面向对象编程的概念和原理
https://www.ibm.com/developerworks/cn/java/j-perry-object-oriented-programming-concepts-and-principles/index.html
其实ibm的文档还是很值得一看的。
如何用一句话说明什么是面向对象思想?
https://www.zhihu.com/question/19854505
这张图很形象。

2、java堆是垃圾回收器管理的主要区域,因此也被称为“GC堆”。
3、java虚拟机规定,java堆可以处于物理上不连续的内存空间中,只要逻辑上是连续的即可。
4、java虚拟机规范规定,如果在堆上没有内存完成实例分配,并堆上也无法再扩展,将会抛出OutOfMemoryError 异常。
5、内存泄漏和内存溢出(重点关注处)
java堆内存的OOM异常是非常常见的异常,重点是根据内存中的对象是否是必要的(这句话是什么意思?)来弄清楚到底是出现了内存泄漏(Memory Leak)还是内存溢出(Memory Overflow)(思考:内存泄漏和内存溢出差别在哪里?都是什么原因引起的?基本意思是什么?)。
内存泄露:指程序中一些对象不会被GC所回收,它始终占用内存,即被分配的对象引用链可达但已无用(可用内存减少)。
内存溢出:程序运行过程中无法申请到足够的内存而导致的一种错误。内存溢出通常发生于OLD段或Perm段垃圾回收后,仍然无内存空间容纳新的Java对象的情况。内存泄露是内存溢出的一种诱因,不是唯一因素(内存泄漏发生次数过多之后,会导致jvm内存不够用,程序运行过程中无法申请到足够的内存,这就称之为溢出?)。
虚拟机栈
虚拟机栈描述的是java方法执行的内存模型,是线程私有的。
每个方法(method?)在执行的时候都会创建一个栈帧。栈帧是一种数据结构,用于保存上下文数据(这句话来自ibm论坛的参考资料https://www.ibm.com/developerworks/cn/java/j-lo-JVM-Optimize/index.html),栈帧中存放了方法的局部变量表、操作数栈、动态连接方法和返回地址等信息(这些是什么?)。
局部变量表
操作数栈
动态连接方法
返回地址
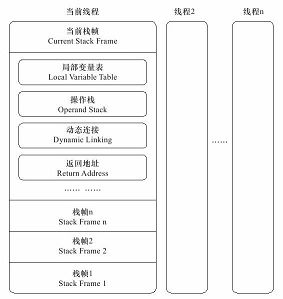
问题:栈帧在其中的作用?
数据结构,保存上下文?
每个方法从调用直至执行完成的过程,就对应着一个栈帧在虚拟机栈中从入栈到出栈的过程。
例如函数
public void test(){
int a = 1;
//局部变量,存于栈帧中的局部变量表
}
函数被调用时,一个栈帧在虚拟机栈中入栈。
函数调用完成,栈帧出栈。
虚拟机栈是线程私有的,生命周期与线程相同。
虚拟机栈中程序员主要关注:栈区(stack)内存,即局部变量表部分(因为这个占内存最大)。
什么是局部变量表?
局部变量表存放了编译时期可知的各种基本数据类型和对象引用。
关于对象引用跟对象实例的思考。
java虚拟机堆中存放对象实例,虚拟机栈中存放对象引用。为什么要这样?
参考链接:
java中为什么分栈内存和堆内存?
https://www.zhihu.com/question/24807877
在Java中,栈stack内存是用来存储函数的主体和变量名的。Java中的代码是在函数体中执行的,每个函数主体都会被放在栈内存中,比如main函数。加入main函数里调用了其他的函数,比如add(),那么在栈里面的的存储就是最底层是main,mian上面是add。栈的运行时后入先出的,所以会执行时会先销毁add,再销毁main。
在Java中,堆内存是用来存储实例的。比如main函数里面声明了一个people的类per,people per;这个per是存储在栈stack内存中的,实例化后(per = new people());实例后的对象实体是存在堆heap内存中的。栈stack内存中存储的per存储着指向堆heap内存的地址指向。堆heap内存的存在是为了更好的管理内存,实现garbage collection。当per不再指向堆heap内存中的实例的时候,garbage collection机制就会把这个堆heap内存中的new people()实例删除,释放内存。
作者:Chloe
链接:https://www.zhihu.com/question/24807877/answer/139282174
另外,这个回答也有一定的启发。
栈和堆不是Java特有的概念,几乎所有的可执行程序,不论操作系统,都会有这两个内存区域的定义。
————————————————
局部变量表所需的内存空间在编译时期完成分配,当进入一个方法时,栈帧中的局部变量空间是已经确定了的,方法运行期间不会改变(是否可用看做栈帧是方法运行的环境?方法的执行需要环境?)。
本地方法栈
本地方法栈与虚拟机的作用相似。
区别在于虚拟机栈为执行java方法服务(即字节码),而本地方法栈为虚拟机使用到的native方法服务。
程序计数器
线程是cpu的基本调度单位,多线程的情况下,当线程数超过cpu数量或者cpu内核数量时(比如当cpu为4核,运行的程序线程最多为5个的时候),线程之间就要根据时间片轮询抢夺CPU时间资源。因为在任意一个时间点一个处理器只会执行一条线程中的指令(4核cpu只有4个处理器,程序中线程有5个因此需要处理器切换线程执行程序的线程)。
因此,为了线程切换后能恢复到正确的执行位置,每条线程都需要一个独立的程序计数器去记录正在执行的字节码指令地址(例如cpu处理器ABCD四个,线程12345。处理器A执行线程1中的程序,执行到某一处的时候,切换到线程2中的程序,当ABCD处理器中的一个再次执行线程1的时候,这个时候为了回到线程1中原来的执行程序位置,就需要程序计数器了,计数器记录了这个位置,程序编译后是生成字节码文件,java虚拟机执行的就是字节码文件,.class文件,这个位置即字节码地址)。
计数器是线程私有的内存区域。
新建对象,jvm如何工作?流程,对象的生命周期间的一些问题。
参考资料:
JVM 数据存储介绍及性能优化
https://www.ibm.com/developerworks/cn/java/j-lo-JVM-Optimize/index.html
JVM内存分配
图解Java 垃圾回收机制
http://blog.csdn.net/justloveyou_/article/details/71216049
深入理解JVM(1) : Java内存区域划分
https://www.jianshu.com/p/7ebbe102c1ae
———JVM相关———
5.3给方法传递参数
本节重点,识别在传递参数给方法时java的“传值”方法的结果(即方法传递结束后是否会改变代码中的原始值)。
java的值传递(结合JVM相关概念思考)。
传递的参数有2中情况:
1.简单的数据类型(int、float、boolean、char),传值之后在方法内部发生的任何事情都不会改变调用的代码中的原始值。


2.对象引用(通过覆盖toString,print语句中可以直接使用对象引用输出toString方法)


最后程序输出结果

为什么传递过程中,pi的值发生了改变?
从main函数入口开始分析。当程序调用main函数,虚拟机栈中的栈帧1(main函数)入栈(栈是先进后出),栈帧中的局部变量表中的位置存放对象引用pi(pi这样的对象引用是一个指针),pi的对象实例(Pi类的实例,pi.value,pi.toString等)存在于虚拟机堆中,3.1415(常量)应该存放在方法区中(线程共享),pi.value指向常量。
当pi传递到函数zero中的时候,变量arg(对象引用)存放在虚拟机栈中(调用函数的时候就有了一个栈帧,栈帧中存放函数中的基本数据和对象引用)。
pi与arg是完全独立的(所有参数是根据值传递的,这里传递了什么?传递了对象引用pi所指向的PI对象实例的地址的值,应该是类似0x01之类的值),但是指向了同一个对象实例。

因此,当使用变量arg来改变对象,就直接地改变了对象。例如代码中arg.value= 0,就是将Pi的实例对象(存放在虚拟机堆中)中的value值变成0。当再次调用Pi的实例对象中的value的时候,值就是0了。
pi.toString发生改变的原因在于对象实例的value的改变。
第六章 数据类型和值
本章目标:
说明强类型的含义
为所以的简单数据类型定义值的范围
描述整形和浮点值的增强
用提供的格式和Unicode转义序列构造char值
标识实例和static变量的默认值
定义一维和多维数组
确定数组元素的默认值
使用花括号{}作为数组声明的一部分来初始化数组
与大多数编程语言一样,java支持多种数据类型。在本章中,我们会讨论如何使用这些数据类型,他们默认值是什么,以及如何声明它们。我们还会讨论声明、构造和初始化数组。
6.1数据类型
java是一种强类型语言。
强类型语言也称为强类型定义语言。是一种总是强制类型定义的语言,要求变量的使用要严格符合定义,所有变量都必须先定义后使用。
这意味着每个变量和表达式都有一个类型,并且每个类型都被严格定义。
6.1.1 变量和数据类型
在java中,变量存储数据。变量中所存储的数据类型是由所分配的数据类型定义的。数据类型也会设置数据的大小限制。
java定义了8种基本数据类型。基本数据类型表示单个值。
byte、 short、 int 、long 、float、double、char、boolean
8 、16 、21、 64位整数、 32、 64位浮点数、16位Unicode字符、真或假
对于考试而言,应该了解所以基本数据类型的取值范围(为什么要了解这个?)。

变量的标准默认值(当不为成员变量提供默认值时,会使用标准默认值,当不为本地变量定义默认值时会引起编译错误)。

java中的变量:
1、成员变量(实例变量,属性)2、本地变量(局部变量)3、类变量(静态属性)
要想理解数据的取值范围,需要理解进制以及内存地址和空间等相关概念。
首先,进制是什么?进制不是孤立存在的,了解进制之前需要先了解数制。
wiki上相关概念很详细。
https://zh.wikipedia.org/wiki/%E8%AE%B0%E6%95%B0%E7%B3%BB%E7%BB%9F
记数系统,或称记数法或数制。是使用一组数字符号来表示数的体系。
一个理想的记数系统能够:
1.有效地描述一组数(例如,整数、实数)
2.所有的数对应唯一的表示(至少有一个标准表示法)
3.反映数的代数和算术结构
记数系统可以按照以下方式分类:
按照进位制,可分为十进制、二进制、八进制等。
按照写法,可分为中文数字、阿拉伯数字、罗马数字等。
如何记数?这就是靠进位制了。
进位制是一种记数方式,亦称进位计数法或位值计数法。利用这种记数法,可以使用有限种数字符号来表示所有的数值(例如使用这种记数方式可以用01这两个数字来表示很大的数值,比如300,500)。
一种进位制中可以使用的数字符号的数目称为这种进位制的基数或底数(比如2进制可以使用的数字符号数目为2,基数为2)。若一个进位制的基数为n,即可称之为n进位制,简称n进制。现在最常用的进位制是十进制,这种进位制通常使用10个阿拉伯数字(即0-9)进行记数。
我们可以用不同的进位制来表示同一个数。比如:十进数57(10),可以用二进制表示为111001(2),也可以用五进制表示为212(5),同时也可以用八进制表示为71(8),可用十二进制表示为49(12),亦可用十六进制表示为39(16),它们所代表的数值都是一样的(这里进制之间是如何转换的?参考链接 :二、八、十、十六进制转换(图解篇))。
以下两个示例都是转到10进制。任意进制转10进制都是这样。十进制是今天最为常用的系统。
在10进制中有10个数字(0 - 9),比如
.在16进制中有16个数字(0–9 和 A–F),比如
一般来讲,b进制系统中的数有如下形式:

二进制广泛用于计算机
三进制用于军队编制
八进制广泛用于计算机
十进制最为常用
十二进制用于计算时辰、月份、一打物品
十六进制广泛用于计算机
二十进制曾被玛雅文明使用
六十进制用于计算秒、分
B(Binary)表示二进制,O(Octal)表示八进制,D(Decimal)或不加表示十进制,H(Hexadecimal)表示十六进制。例如:(101011)B=(53)O=(43)D=(2B)H
首先看N进制转换成十进制与十进制转换成N进制。
八、十六进制转十进制
低位到高位(即从右往左)计算,按权相加。
将二进制的(101011)B转换为十进制的步骤如下:
1. 第0位 1 x 2^0 = 1;
2. 第1位 1 x 2^1 = 2;
3. 第2位 0 x 2^2 = 0;
4. 第3位 1 x 2^3 = 8;
5. 第4位 0 x 2^4 = 0;
6. 第5位 1 x 2^5 = 32;
7. 读数,把结果值相加,1+2+0+8+0+32=43,即(101011)B=(43)D。
将八进制的(53)O转换为十进制的步骤如下:
1. 第0位 3 x 8^0 = 3;
2. 第1位 5 x 8^1 = 40;
3. 读数,把结果值相加,3+40=43,即(53)O=(43)D。
将十六进制的(2B)H转换为十进制的步骤如下:
1. 第0位 B x 16^0 = 11;
2. 第1位 2 x 16^1 = 32;
3. 读数,把结果值相加,11+32=43,即(2B)H=(43)D。
十进制转二、八、十六进制
十进制转二进制
除2取余法,即每次将整数部分除以2,余数为该位权上的数,而商继续除以2,余数又为上一个位权上的数,这个步骤一直持续下去,直到商为0为止,最后读数时候,从最后一个余数读起,一直到最前面的一个余数。
101011,即(43)D=(101011)B。

十进制 转八进制
除8取余法,即每次将整数部分除以8,余数为该位权上的数,而商继续除以8,余数又为上一个位权上的数,这个步骤一直持续下去,直到商为0为止,最后读数时候,从最后一个余数起,一直到最前面的一个余数。
1434,即(796)D=(1434)O。

十进制转十六进制
除16取余法,即每次将整数部分除以16,余数为该位权上的数,而商继续除以16,余数又为上一个位权上的数,这个步骤一直持续下去,直到商为0为止,最后读数时候,从最后一个余数起,一直到最前面的一个余数。(796)D=(31C)H。

以上是N进制转十进制与十进制转N进制的情况,其他的进制之间如何转换?下面是N进制转二进制与二进制转N进制。
二进制转八、十六进制
二进制转八进制
方法:取三合一法,即从二进制的小数点为分界点,向左(向右)每三位取成一位,接着将这三位二进制按权相加,然后,按顺序进行排列,小数点的位置不变,得到的数字就是我们所求的八进制数。如果向左(向右)取三位后,取到最高(最低)位时候,如果无法凑足三位,可以在小数点最左边(最右边),即整数的最高位(最低位)添0,凑足三位。
(11010111.0100111)B=(327.234)O

二进制转十六进制
方法:取四合一法,即从二进制的小数点为分界点,向左(向右)每四位取成一位,接着将这四位二进制按权相加,然后,按顺序进行排列,小数点的位置不变,得到的数字就是我们所求的十六进制数。如果向左(向右)取四位后,取到最高(最低)位时候,如果无法凑足四位,可以在小数点最左边(最右边),即整数的最高位(最低位)添0,凑足四位。
例:将二进制的(11010111)B转换为十六进制的步骤如下:
1. 0111 = 7;
2. 1101 = D;
3. 读数,读数从高位到低位,即(11010111)B=(D7)H。

八、十六进制转二进制
八进制转二进制
方法:取一分三法,即将一位八进制数分解成三位二进制数,用三位二进制按权相加去凑这位八进制数,小数点位置照旧。
将八进制的(327)O转换为二进制的步骤如下:
1. 3 = 011;
2. 2 = 010;
3. 7 = 111;
4. 读数,读数从高位到低位,011010111,即(327)O=(11010111)B。

八进制转二进制的时候需要记住对应的八进制与二进制对应的表。如果记不住的话,除2取余也可以。八进制的3用除2取余法可得二进制的011。

十六进制转二进制
方法:取一分四法,即将一位十六进制数分解成四位二进制数,用四位二进制按权相加去凑这位十六进制数,小数点位置照旧。
例:将十六进制的(D7)H转换为二进制的步骤如下:
1. D = 1101;
2. 7 = 0111;
3. 读数,读数从高位到低位,即(D7)H=(11010111)B。

上面说完十进制与N进制的相互转换、二进制与N进制的相互转换之后,就剩下八进制与十六进制的相互转换了。
八进制转十六进制
方法:将八进制转换为二进制,然后再将二进制转换为十六进制,小数点位置不变。 例:将八进制的(327)O转换为十六进制的步骤如下:1. 3 = 011;2. 2 = 010;3. 7 = 111;4. 0111 = 7;5. 1101 = D;6. 读数,读数从高位到低位,D7,即(327)O=(D7)H。

十六进制转八进制
方法:将十六进制转换为二进制,然后再将二进制转换为八进制,小数点位置不变。 例:将十六进制的(D7)H转换为八进制的步骤如下:1. 7 = 0111;2. D = 1101;3. 0111 = 7;4. 010 = 2;5. 011 = 3;6. 读数,读数从高位到低位,327,即(D7)H=(327)O。

参考链接:
http://www.cnblogs.com/gaizai/p/4233780.html (进制转换方面主要是这个)
https://www.zhihu.com/question/23131605
了解完进制之后,如何根据此判断基本数据类型的取值范围呢?这就需要理解程序是如何存储在硬盘上的了。综合这些知识点,才能理解数据类型的取值范围的由来。
数据在空间中是如何存储的呢?
首先,什么是内存?
程序和数据平常存储在硬盘等存储器上,无论开机还是关机,它们都是存在的,不会丢失。硬盘可以存储很多东西,但传输速度慢。因此,需要运行程序或打开数据时,这些数据必须从硬盘等存储器上先传到另一种容量小但速度快得多的存储器(相关名词:存储器、寄存器。),之后才送入CPU进行执行处理,这中间的存储器就是内存。
这里对于电脑而言,硬盘(固态硬盘或者机械硬盘)就是存储器,内存条(ddr内存条)就是就是内存(内存某种程度上来说也是存储器)。
对于存储器而言,首先必须要有地址。类似多个房子存储不同的东西,为了更加方便地记录每个房子存储了什么东西,首先需要给房子编门牌号,然后对应门牌号记录房子的东西,以便查找,有了门牌号,才能找到存储的东西。
举例,如何在存储器里存储“丁小明”这个名字。
内存是按字节编址,每个地址的存储单元可以存放8bit的数据。
参考链接:
计算机原理学习(3)-- 内存工作原理
http://blog.csdn.net/cc_net/article/details/11097267
在计算机中存储如下

第一行是存储的数据,第二行是内存地址。
汉字在一个地址(位置)里呆不下,必须放在连续的两个地址空间内。
假设有一字符串“ABC”,被记在内存里,可示意为(这次我们假设从内存地址2000H处记起):

下图有3行:
第一行是给人看的(房子里面的东西)。
第二行是每次中实际存储的数据(二进制的数据,东西放到房子里要转换成二进制才能被存储,可以想象这样一种场景:存储的东西是衣服,但是要贴条形码才能存储到房子里面,条形码跟衣服之间存在关联)。
第三行才是内存地址,并不是每个0和1所占的位置都被编上地址。而是每8个才拥有一个地址。


字符A 在ASCII 表中对应的二进制是 0100 0001 (注意这里是字符,不是数字,字符保存到计算机中需要通过ASCII 表转换才行)。
https://zh.wikipedia.org/wiki/ASCII
只有第二行的数据,才是存在计算机中的数据。那么内存地址存在哪里?
存放在寄存器的存储空间中。内存地址实际上是一种偏移量,存储于段寄存器中。内存地址只是一种抽象,不是真正的物理内存地址,而是逻辑地址。关于这些,需要了解操作系统如何进行内存映射(暂时跳过)。
参考链接:
C语言中内存地址是否占用存储空间呢?
https://www.zhihu.com/question/53895024
总结:内存地址是内存当中存储数据的一个标识,并不是数据本身,通过内存地址可以找到内存当中存储的数据。
计算机只能识别二进制的数据。
内存地址是以十六进制存储的(任何进制最后到计算机内部都会转换成二进制,这样计算机才能识别)。
因为数字电路中只有高低电平之分。也就相当与一个开关。如开为1,关为0。所以计算机中采用二进制。十六进制只是计算机常用的一种编码。
平时十六进制的使用是为了便于书写;而计算机内部,一切信息的存取、传输都是以二进制形式进行的。
https://zhidao.baidu.com/question/210971875.html
参考链接:
关于内存地址和内存空间的理解。
深入浅出: 大小端模式
https://www.bysocket.com/?p=615
大端和小端存储相关。
大小端名词的由来。
关于大端小端名词的由来,有一个有趣的故事,来自于Jonathan Swift的《格利佛游记》:Lilliput和Blefuscu这两个强国在过去的36个月中一直在苦战。战争的原因:大家都知道,吃鸡蛋的时候,原始的方法是打破鸡蛋较大的一端,可以那时的皇帝的祖父由于小时侯吃鸡蛋,按这种方法把手指弄破了,因此他的父亲,就下令,命令所有的子民吃鸡蛋的时候,必须先打破鸡蛋较小的一端,违令者重罚。然后老百姓对此法令极为反感,期间发生了多次叛乱,其中一个皇帝因此送命,另一个丢了王位,产生叛乱的原因就是另一个国家Blefuscu的国王大臣煽动起来的,叛乱平息后,就逃到这个帝国避难。据估计,先后几次有11000余人情愿死也不肯去打破鸡蛋较小的端吃鸡蛋。这个其实讽刺当时英国和法国之间持续的冲突。Danny Cohen一位网络协议的开创者,第一次使用这两个术语指代字节顺序,后来就被大家广泛接受。
这故事太扯了,真实度不可考。
大小端在计算机业界,Endian表示数据在存储器中的存放顺序。
大端模式:是指数据的高字节保存在内存的低地址中,而数据的低字节保存在内存的高地址中,这样的存储模式有点儿类似于把数据当作字符串顺序处理:地址由小向大增加,而数据从高位往低位放
小端模式:是指数据的高字节保存在内存的高地址中,而数据的低字节保存在内存的低地址中,这种存储模式将地址的高低和数据位权有效地结合起来,高地址部分权值高,低地址部分权值低,和我们的逻辑方法一致。
计算机采用大端还是小端存储是CPU来决定的。我们常用的X86体系的CPU采用小端,一下ARM体系的CPU也是用小端,但有一些CPU却采用大端比如PowerPC、Sun。
下面以内存(存储器)中数据的存储为例,说明大小端存在的意义。
内存是按字节编址,每个地址的存储单元可以存放8bit的数据。我们也知道CPU通过内存地址获取一条指令和数据,而他们存在存储单元中。现在就有一个问题。我们的数据和指令不可能刚好是8bit,如果小于8位,没什么问题,顶多是浪费几位(或许按字节编址是为了节省内存空间考虑)。但是当数据或指令的长度大于8bit呢?因为这种情况是很容易出现的,比如一个16bit的Int数据在内存是如何存储的呢?
其实一个简单的办法就是使用多个存储单元来存放数据或指令。比如Int16使用2个内存单元,而Int32使用4个内存单元。当读取数据时,一次读取多个内存单元。于是这里又出现2个问题:
多个存储单元存储的顺序?如何确定要读几个内存单元?
此时就大小端的作用就体现出来了。大小端定义了如何读取内存单元。
整形0x12345678在内存中存储如下:

1)大端模式:
低地址 -----------------> 高地址
0x12 | 0x34 | 0x56 | 0x78
2)小端模式:
低地址 ------------------> 高地址
0x78 | 0x56 | 0x34 | 0x12
下面是两个具体例子:
16bit宽的数0x1234在Little-endian模式(以及Big-endian模式)CPU内存中的存放方式(假设从地址0x4000开始存放)为:
0x1234转换成2进制是1001000110100,需要占用2个8位(十六转二进制用取一分四法,因此可以看出是占16位)。

32bit宽的数0x12345678在Little-endian模式以及Big-endian模式)CPU内存中的存放方式(假设从地址0x4000开始存放)为:

了解了大小端之后,还需要掌握如何对数据进行大小端转换。
//将整数按照小端存放,低字节出访低位
public static byte[] toLH(int n) {
byte[] b = new byte[4];
b[0] = (byte) (n & 0xff);
b[1] = (byte) (n >> 8 & 0xff);
b[2] = (byte) (n >> 16 & 0xff);
b[3] = (byte) (n >> 24 & 0xff);
return b;
}
/*** 将int转为大端,低字节存储高位* * @paramn* int* @returnbyte[]*/
public static byte[] toHH(int n) {
byte[] b = new byte[4];
b[3] = (byte) (n & 0xff);
b[2] = (byte) (n >> 8 & 0xff);
b[1] = (byte) (n >> 16 & 0xff);
b[0] = (byte) (n >> 24 & 0xff);
return b;
}
参考链接:
计算机原理学习(3)-- 内存工作原理 (这篇挺详细的)
http://blog.csdn.net/cc_net/article/details/11097267
详解大端模式和小端模式
http://blog.csdn.net/ce123_zhouwei/article/details/6971544
Java中大小端的处理
http://blog.csdn.net/wangxiaotongfan/article/details/51212534
了解了上面相关的概念之后,再来看数据类型的取值范围的由来。
这里还有一个补码、原码、反码的相关概念。
数制和码制是两个不同概念。
码制,指编码的规则。
计算机中处理的数据有两类:数值数据和非数值数据。
数值数据指表示数量的数据,有正负和大小之分,在计算机中以二进制的形式存储和进行运算。
非数值数据包括字符、汉字、声音和图像等,在计算机中处理前必须以某种编码形式转换成二进制数表示(例如ASCII表)。
出处:程序员考试辅导
https://books.google.com/books?id=z5wHFhgKnAUC&pg=PA4&lpg=PA4&dq=%E7%A0%81%E5%88%B6%E6%98%AF%E4%BB%80%E4%B9%88&source=bl&ots=z4uTklbcn3&sig=Jzt1zA3TW0HkldW6FKj4SiLaJdM&hl=zh-CN&sa=X&ved=0ahUKEwiLg5jipevZAhVF8GMKHYiIBHMQ6AEIQzAG#v=onepage&q&f=false
机器数
各种数据在计算机中表示的形式称为机器数。
机器数有两种:无符号和带符号数。
无符号数表示正数,没有负数,机器数中无符号位。
无符号整数的小数点,固定在该数最低位之后,是纯整数。
无符号整数的小数点,固定在最高位之前,是纯小数。
首先看最基本的一个8位组成的存储单元。
8位(计算机是以8位为一个单元存储的)的二进制无符号整数的表数范围是8位全0到8位全1,即0到2的8次方-1=255。
这个是怎么算出来的?
例如00到11(11表示的是3,2的1次方加2的0次方,这里是二进制转十进制,因为范围是给人看的,十进制就是日常生活中是进制,因此要转换成十进制来表示表数范围,即2的2次方-1)的表数范围为0到2的2次方-1,范围大小为4。
000到111(111表示的是7)表数范围是0到2的3次方-1(这里这个换算数学公式的叫什么来着?)。
由此可知,一个8位的存储单元存储的无符号表数范围为0到255。
那么有符号的情况下呢?
对于有符号整数,二进制最高位表示正负,不表示数值,最高位0表示正数,为1表示负数。因此,对于数据,能表示数值的就剩下n-1位。对于8位的数据。
例如byte(byte是8位的数据) -1 用 二进制表示为1000 0001。1 用 二进制表示为0000 0001。有效数据表示位为7位。 因此最大数据为111 1111 ,表示的是127(2的八次方-1)。
但是问题在于负数最小是-128 。这个是怎么来的?
按以上道理同理的话应该是-127,为什么实际最小数据为-128?
这就需要理解原码、补码、反码相关 概念了。
计算机内部是以二进制进行存储数据的,数据分为有符号和无符号两种类型。但是这样在做运算时会导致错误的发生,因此有了补码等相关。
0000 0001
+ 0000 0001
—————————
0000 0010 ………………2
这是没有问题的,但是当进行减法运算的时候呢?
当相减时 1-1=? 由于计算机只会加法不会减法,它会转化为1+(-1) ,因此
0000 0001
+ 1000 0001
____________________
1000 0010 …………… -2 ,1-1= -2? 这显然是不对了。此时就需要反码了。
直接用最高位表示符号位的叫做原码。
反码
是原码除最高位其余位取反。
正数的反码和原码相同,负数的反码是原码除了符号位,其余为都取反,因此-1 的原码为 1 0000001 ,反码为 1 1111110, 现在再用反码来计算 1+(-1) (就是说,目前的数据的运算,都需先把数据换成反码,再进行运算,再转换成原码)。
0000 0001
+ 1111 1110
————————
1111 1111 …………再转化为原码就是 1000 0000 = -0 。
但是这个又带来了新的问题,出现了-0。-0和0是重复的。为避免0的重复,有了补码的概念。
补码
正数的补码是其本身,负数的补码为其反码加一 。所以,负数转化为补码需两个步骤, 第一,先转化为反码,第二: 把反码加一。。
1+(-1) 运算是数据的补码进行运算。
0000 0001
+ 1111 1111
________________
1 0000 0000 …………………… 这里变成了9位,由于数据的存储单元是8位的,最高位1无法存入,因此被丢弃。最后结果为0000 0000(即0)。
总结:数据的运算是补码之间的运算(运算结果是补码形式)。
那么回到之前的问题,8位的byte的-128是怎么来的呢?
1000 0000 表示的是-128。原因是什么?
这其实就是一个环。补码就是同余。
同余:给定一个正整数m,如果两个整数a和b满足a-b能够被m整除,即(a-b)/m得到一个整数,那么就称整数a与b对模m同余,记作a≡b(mod m)。对模m同余是整数的一个等价关系。
8位只能表示256个数,0到255,但我还想表示一些负数怎么办呢?就用与该负数同余的正数来表示呗。-1=255,-2=254,等等。


图片出处:《计算机组织与体系结构》第九章。https://www.zhihu.com/question/20159860
以上图为例,一个圆(内含4位的二进制,这里简化了数据,实际最小是8位,但是同理可推),顺时针和逆时针方向分别代表了+1和-1运算。当走到交汇处的时候,要做什么运算?
1000本质上是-0.
0111(+7) +1的话是1000(即8)。1001(-7-1的话)的话,正好也是1000.。
1001->1000 (-1)。从-1到-8可以看到补码是依次递减的。
0111 -> 1000 (+1)
一个表数范围为16的圈。怎么划分数据范围。
0到15为一个圈,-8到7为一个圈。
8的原码是1000,补码也是1000,-8的原码是1 1000,补码为1 1000。丢弃最高位,依然是1000.
如果以0为起始点,那么结尾为什么不是8而是-8?
-127到127是255个,为了不浪费编码位置,想把-0利用起来,因此将-0通过补码算法处理后将这些负数(-1、-2、-3等)连接起来,表面上是-8,其实是-0了。主要是通过补码算法连接这些负数。
因此是-8而不是8.
补码算法的存在,就是为了表达更好地这些数据。
本质其实是数学问题(深入可参考这篇:原码, 反码, 补码 详解)。
参考链接:
1字节的表示范围为-128到127,为什么不是-128到128
https://zhidao.baidu.com/question/588564780479617005.html
参考链接:
https://books.google.com/books?id=cWLgsoi8fbEC&pg=RA1-PA8&lpg=RA1-PA8&dq=%E6%95%B0%E5%92%8C%E7%A0%81%E7%9A%84%E5%B7%AE%E5%88%AB&source=bl&ots=V3kzCixekj&sig=b_gTuItX9iSd9ZIk1igWgwzmzok&hl=zh-CN&sa=X&ved=0ahUKEwip_dvDpOvZAhVQ12MKHUUkA1sQ6AEIbDAH#v=onepage&q=%E6%95%B0%E5%92%8C%E7%A0%81%E7%9A%84%E5%B7%AE%E5%88%AB&f=false
原码, 反码, 补码 详解
浅析为什么char类型的范围是 —128~+127
http://blog.csdn.net/daiyutage/article/details/8575248
基本数据类型之数组
如何声明、构造和初始化数组。
数组是被某公共名引用的变量的集合,并且可以有一维或者多维。
声明和初始化数组。
可以使用多种方式来声明数组。你可以声明时不初始化。这种情况,数组变量被创建,但是没有分配空间。
数组也是对象,可通过new新建对象。
数组的数组
理论上来说,java数组都是一维的(多维数组类似于矩阵)。
暂时略过,待想写
第七章 运算符
第八章 流程控制
本章目标:
第九章 方法
本章目标
定义方法及其有效的返回值。
区别重载方法和覆盖方法。
确定重载方法和覆盖方法的合法返回类型。
使用特殊的应用super来编写覆盖方法的代码。
第十章 构造器
本章目标:
什么是构造器,以及使用方法。
构造器方法没有返回类型,并不使用void。这是因为构造器的隐含返回类型是该类本身。
十一章 对象和类
本章目标:
1.定义类,包括成员变量和成员方法(成员是相对于类而言的,是全局的)。
2.正确地使用public、abstract、final、strictfp等类修饰符。
3.用private、protected、public、static、final、volatile、native或abstract修饰符声明变量和方法。
4.基于访问控制关键字确定何时能对变量和方法进行访问。
5.使用“是什么”和“有什么”关系创建面向对象的层次。
6.定义内类,并说明如何使用内类。
7.如何使用匿名类和静态内类。
用java编写的所以东西都保存在类中。
类实例是对象的特定实现
(这句话拆开来关键字是 类实例 对象 特定实现 。牢记这句话,类是一个抽象的概念,类的实例是对象的实现,例如person这个类,是一个统称,概括了、抽象了人这个种类的生物,但是人又可以有不同的个体,这个个体就是对象,对象的实现就是类的实例, 人类小明就是类的实例,即对象的实现。类是一个抽象的概念,它不存在于现实中的时间/空间里,类只是为所有的对象定义了抽象的属性与行为。就好像“Person(人)”这个类,它虽然可以包含很多个体,但它本身不存在于现实世界上 。对象是类的一个具体。它是一个实实在在存在的东西)。
参考链接:
对象和类有什么区别
https://zhidao.baidu.com/question/354461709.html
对象使用声明、表达式和其他结构以作实际的工作。这样做的目的是为了可以重复使用这些代码。
重用性是面向对象编程语言和java强大之处。
类可以基于其他类进行创建。实际上,所以的类都是基于名为Object的基类进行创建的。
当扩展基类或任何其他类时,新创建的类就拥有了其他父类的所以属性和方法。也就是说,类通过继承来接收其父类的特性。继承之后,你可以更改父类的方法,或者为子类定义新方法。
对象
对象是信息的容器(对象的实现是类的实例,小明是对象,小明的实现是人这个类的实例)。可以在程序中实例化对象,以便于包含和管理信息。对象所包含的信息就是其数据。对象中的数据(姓名、身高体重等)通常被称作其实例变量或者字段(field)。对象使用方法来管理数据。
对象被封装,这样可以向用户隐藏数据的实现。所以对象都有行为、状态和标识。
对象有三大属性: 状态,行为,标识符。
对象的状态是什么?
对象的状态是由其字段的当前值来决定的。
对于JVM来说,Java对象状态很简单,一个是new创建的新对象,一个是没有任何对象引用它时的垃圾对象,对于垃圾对象,JVM会在合适时间对其进行回收。对与Hibernate来说,一个Java对象会有四种状态:
临时状态(transient):刚用new语句创建,还没有别持久化,尚未处于Session的缓存中。处于临时状态的Java对象被称为临时对象。
持久化状态(persistent):已经被持久化,并加入到Session的缓存中。处于持久化状态的Java对象被称为持久化对象。
删除状态(removed):不再处于Session的缓存中,并且Session已经计划将其从数据库种删除。处于删除状态的Java对象被称为删除对象。
游离状态(detached):已经被持久化,但不再处于Session的缓存中。处于游离状态的Java对象称为游离对象。
行为是什么?
行为是指对象的方法 。
标志符
标志符的定义:标志符是一个对象的属性,他区分了这个对象与所有其他对象。对象的类型把对象与其他类型的对象区分出来,而标志符则把对象与所有其他对象区分出来。
参考链接:
Java对象在Hibernate持久化层的状态
http://leekai.me/java-object-in-hibernate/
Java中对象的三种状态
http://blog.csdn.net/guozhenqiang19921021/article/details/51770113
面向对象的特征有五个,标识唯一性,分类性,多态性,封装性,模块独立性,能分别解释下吗?
https://zhidao.baidu.com/question/520335269.html
java中对象有哪些属性?什么是状态?什么是行为?二者之间有何关系?
https://zhidao.baidu.com/question/430143377.html?qbl=relate_question_0&word=%B6%D4%CF%F3%B5%C4%D7%B4%CC%AC
创建和销毁对象
java中,对象的数据空间并不预先分配。相反地,它只会在需要时再创建。垃圾收集器会在后台运行,查找不再使用的内存,并负责释放这些内存。
类变量
下面讨论变量在类中是如何使用的。
使用“是什么”和“有什么”的面向对象关系。
is a是继承,has a 是组合。简单来说就是继承跟组合。
DOG IS A ANIMAL 也就是说狗是一种动物。
另外一种 dog has a eyes 表示 狗自身有眼睛。
is a 是从属的关系,has a 表示你自己有。
例如,如何定义以下这些类的层次关系?
下面是3个类,如何定义这些类,使类的扩展性更好?首先来看看不考虑扩展性的情况。
1、包括职员编号的Employee类。
定义一个employee类,包含全局变量mEmployeeNumber。
2、全职职员类(full-time)。
包括一个职员编号。
包括这周工作的小时数。
用salary()方法计算自己薪水。
定义一个full-time类(表示全职的员工),包含全局变量mEmployeeNumber(职员编号),mWorkTime(工作的小时数),
以及函数salary(),例如薪水的计算是
工作时长*工作时薪-税-社保之类的。
3、退休职员(Retired)类。
包括一个职员编号。
包括工作的年数。
用自己的salary()方法计算薪水。
定义一个Retired类。包含全局变量mEmployeeNumber(职员编号),mWorkTotalYear(工作年数),函数salary()。
现在需要将这些类的共同点进行提取,抽象出这些类。
到底应该如何抽象对象以达到耦合度最小的情况?
首先来看employee类,全局变量mEmployeeNumber,这个是三个类都有的属性,因此可以将这个类放在顶层。
employee作为基类,让其它两个类继承其属性。又因为full-time和Retired都拥有各自的salary()函数,employee中没有salary()函数,因此,salary函数 可以在employee类中用abstract修饰,当employee作为基类(虽然是基类,但是层次结构上来说是处于顶层)的时候,其他两个类继承基类后需要重写salary函数,这样就有了各自的salary函数。
full-time和Retired在继承了employee基类之后,再各自定义自己的全局变量mWorkTime和mWorkTotalYear即可。
因此可以将类变成如下的层次结构

此时employee和fullTime之间的关系是继承(fullTime is employee ,这就是Dog is Animal)。
然后,使用这些类和由此引起的类层次,创建一个叫Ralph Cramden的全职职员对象(即新建一个Ralph Cramden类,在Ralph Cramden类继承自fullTime)。但是,40年后当Ralph 需要退休的时候,又需要重新创建一个新的Ralph类继承自Retired类。如果中途发生变化呢?例如中途停止工作一年又如何?要不停地创建新的对象?
现在为了避免创建多个对象,需要对类的层次进行修改。很明显,之前的类层次设计有问题。问题出在对特定领域没有完全理解“是什么(is a)”和“有什么(has a)”的区别。
is a 定义了一个超类和一个子类之间的一种直接关系:子类是超类的一种。has a描述了一个对象的一部分和另一个对象之间的关系,它们通常是不同的类型:一个对象的部分是另一个对象。
首先将基类employee类进行修改,修改其全局属性。employee在原有id属性之上增加status变量(这是一个类变量)。需要把全职或退休这种状态用has a这种方式表现出来,而不是用is a。当用到需要变化的,把变量提取出来并增加一层层次结构,能提高复用度。此时只用创建一个Employee即可(这种情况是Employee就是一个 你需要创建的职员类)。
这种层次结构里,实际需要创建的职员类在顶层。之前的层次结构中实际创建的职员类是继承自最底层的类。

一个职员“有(has a)”某种状态(状态是个属性),全职或退休都“是(is a)”某状态。

练习:
创建如下类:2Dshape、Circle、Square和Point。Piont根据(x,y)坐定位。Circle除了一个(x,y)坐标原点之外,还有半径属性。正方形除了一个(x,y)坐标点之外,还有边长。这些类中哪些是超类,哪些是子类?有哪些类相互间具备“有什么(has a)”关系?
首先,思路应该是:2Dshape是超类。包含了所以的二维图像,Circle、Square类为子类,point为has a属性。
圆形和正方形都属于“is a”,即都有除了坐标点之外的属性(子类在父类的基础上衍生了新的属性)。

练习:
定义一个类层次来表示咖啡豆装运。咖啡豆在一个存货系统中可能有不同的特征。这取决于是否经过检验,以及检验的结果(是否合格,评判标准可能是新鲜或不新鲜)。
如何创建一个合适的类来表示描述记录咖啡豆装运检验这个整个事件?
例如
public class CoffeeBeanState{
//是否新鲜的状态
}
这个是可以通用的类。
是否经过检验,这个用is a。
这个检验状态是会发生改变的。
类关键字
public abstract final 。
变量关键字
static final volatile
访问控制关键字
public protected private
类的类型转换
把一种对象类型转换为另一种类型。
内类。
思考:如何将一个接口实现为匿名类?
参考链接:
接口的匿名内部类实现
https://zhidao.baidu.com/question/345963995.html
基于接口实现匿名内部类的注意事项
https://blog.csdn.net/wuya112709/article/details/51422152