简单线性回归
> fit<-lm(weight ~ height, data=women) #在R中,拟合线性模型最基本的函数就是lm( ),格式为:myfit <- lm(formula, data),其中,formula形式为Y~ X1 + X2 + XK
> summary(fit)
Call:
lm(formula = weight ~ height, data = women)
Residuals:
Min 1Q Median 3Q Max
-1.7333 -1.1333 -0.3833 0.7417 3.1167
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -87.51667 5.93694 -14.74 1.71e-09 ***
height 3.45000 0.09114 37.85 1.09e-14 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 1.525 on 13 degrees of freedom
Multiple R-squared: 0.991, Adjusted R-squared: 0.9903
F-statistic: 1433 on 1 and 13 DF, p-value: 1.091e-14
> women$weight
[1] 115 117 120 123 126 129 132 135 139 142 146 150 154 159 164
> fitted(fit)#列出拟合模型的预测值
1 2 3 4 5 6 7 8
112.5833 116.0333 119.4833 122.9333 126.3833 129.8333 133.2833 136.7333
9 10 11 12 13 14 15
140.1833 143.6333 147.0833 150.5333 153.9833 157.4333 160.8833
> residuals(fit)#列出拟合模型的残残值
1 2 3 4 5 6
2.41666667 0.96666667 0.51666667 0.06666667 -0.38333333 -0.83333333
7 8 9 10 11 12
-1.28333333 -1.73333333 -1.18333333 -1.63333333 -1.08333333 -0.53333333
13 14 15
0.01666667 1.56666667 3.11666667
> plot(women$height, women$weight, xlab="Height(in inches)", ylab="Weight(in pounds)")
> abline(fit)#表示画一条y=a+bx的直线
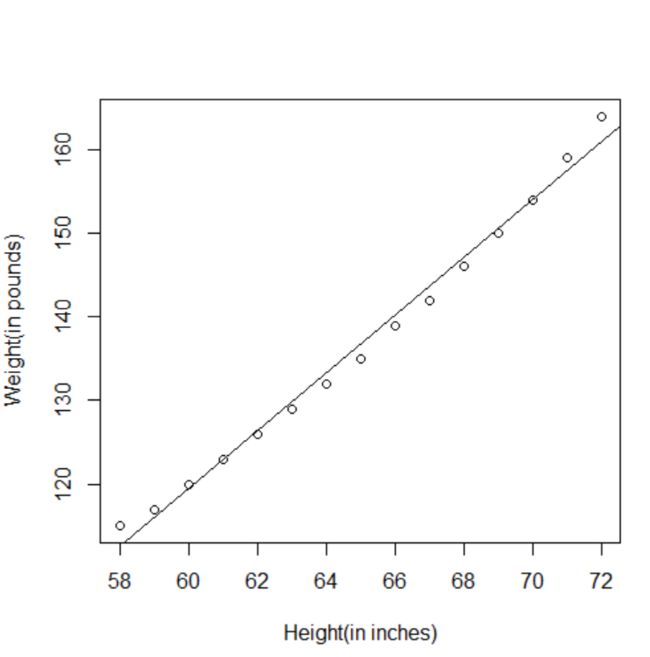
结果:Weight= -87.52 + 3.45*Height
多项式回归
> fit2<-lm(weight~height + I(height^2), data=women)
> summary(fit2)
Call:
lm(formula = weight ~ height + I(height^2), data = women)
Residuals:
Min 1Q Median 3Q Max
-0.50941 -0.29611 -0.00941 0.28615 0.59706
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 261.87818 25.19677 10.393 2.36e-07 ***
height -7.34832 0.77769 -9.449 6.58e-07 ***
I(height^2) 0.08306 0.00598 13.891 9.32e-09 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 0.3841 on 12 degrees of freedom
Multiple R-squared: 0.9995, Adjusted R-squared: 0.9994
F-statistic: 1.139e+04 on 2 and 12 DF, p-value: < 2.2e-16
> plot(women$height, women$weight, xlab="Height(in inches)", ylab="Weight(in lbs)")
> lines(women$height, fitted(fit2))#lines( )函数做的是一般连线图,其输入是x,y的点向量。
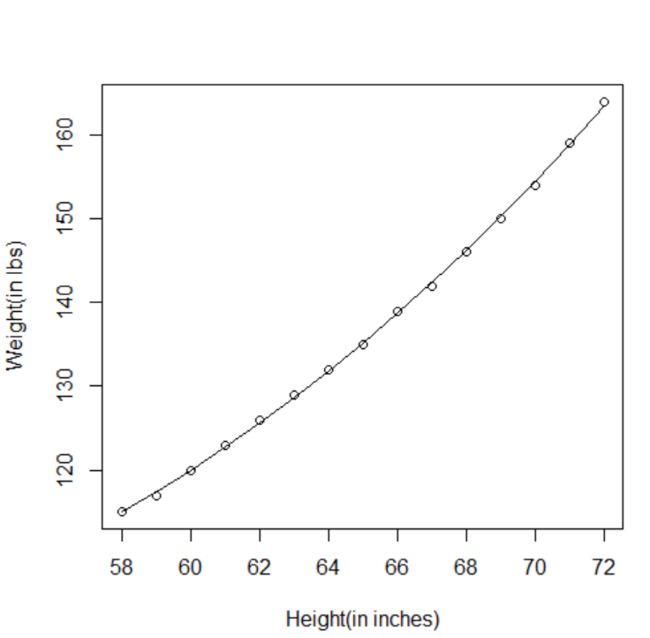
结果:Weight= 261.88 - 7.35*Height + 0.083*Height^2
> fit3<- lm(weight~ height + I(height^2)+I(height)^3, data=women)
> library(car) #package car needs to be installed
> scatterplot(weight~height, data=women, spread=FALSE, smoother.args=list(Ity=2), pch=19, main="Women Age 30-39", xlab="Height(inches)",ylab="Weight(lbs.)")
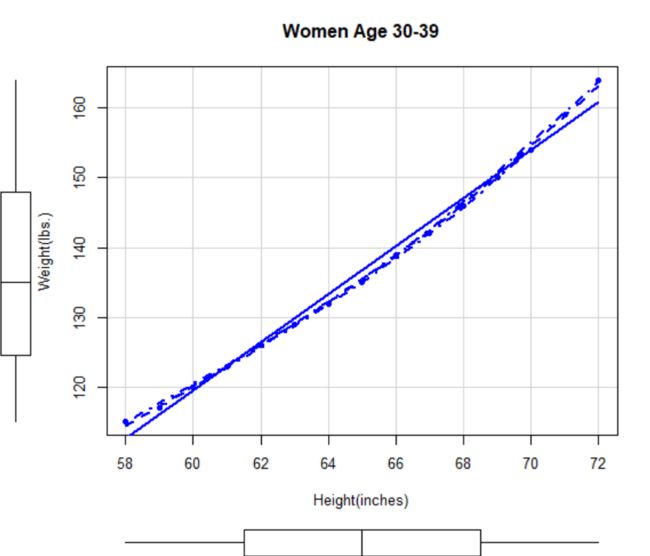
这个功能加强的图形,既提供了身高与体重的散点图、线性拟合曲线和平滑拟合曲线,还在相应边界展示了每个变量的箱线图。speard=FALSE选项删除了正负均方根在平滑曲线上的展开和非对称信息。smoother.args=list(Ity=2)选项设置loess拟合曲线为虚线。pch=19选项设置点为实心圆(默认为空心圆)。可以看到,曲线的拟合比直线更好。
检测二变量关系
> states<- as.data.frame(state.x77[,c("Murder","Population","Illiteracy","Income","Frost")])
> cor(states)
Murder Population Illiteracy Income Frost
Murder 1.0000000 0.3436428 0.7029752 -0.2300776 -0.5388834
Population 0.3436428 1.0000000 0.1076224 0.2082276 -0.3321525
Illiteracy 0.7029752 0.1076224 1.0000000 -0.4370752 -0.6719470
Income -0.2300776 0.2082276 -0.4370752 1.0000000 0.2262822
Frost -0.5388834 -0.3321525 -0.6719470 0.2262822 1.0000000
> library(car)
> scatterplotMatrix(states, spread=FALSE, smoother.args=list(Ity=2),main="scatter plot Matrix")
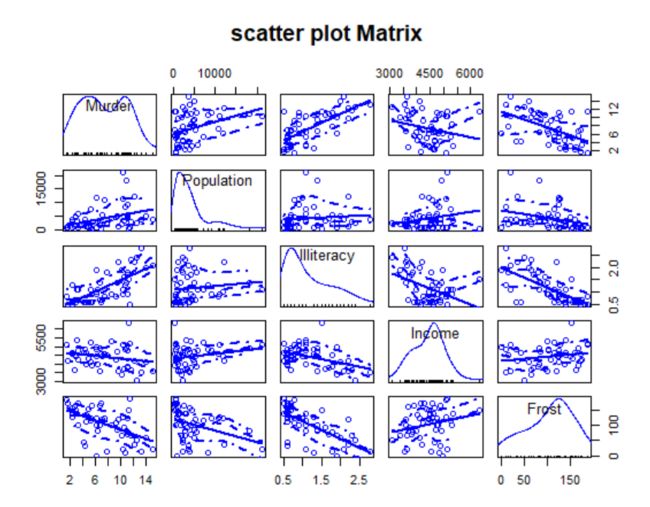
从图中可以看到,谋杀率是双峰曲线,每个预测变量都一定程度上出现了偏斜。谋杀率随着人口和文盲率的增加而增加,随着收入水平和结霜天数增加而下降。
多元线性回归
<- lm(Murder~Population+Illiteracy+Income+Frost, data=states)
> summary(fit)
Call:
lm(formula = Murder ~ Population + Illiteracy + Income + Frost,
data = states)
Residuals:
Min 1Q Median 3Q Max
-4.7960 -1.6495 -0.0811 1.4815 7.6210
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 1.235e+00 3.866e+00 0.319 0.7510
Population 2.237e-04 9.052e-05 2.471 0.0173 *
Illiteracy 4.143e+00 8.744e-01 4.738 2.19e-05 ***
Income 6.442e-05 6.837e-04 0.094 0.9253
Frost 5.813e-04 1.005e-02 0.058 0.9541
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 2.535 on 45 degrees of freedom
Multiple R-squared: 0.567, Adjusted R-squared: 0.5285
F-statistic: 14.73 on 4 and 45 DF, p-value: 9.133e-08
#当预测变量不止一个时,回归系数的含义为:一个预测变量增加一个单位,其他预测变量保持不变时,因变量要增加的数量。例如,人口率上升1%时,谋杀率会上升2.24%,在0.05水平下显著。
有交互项的多元线性回归
> fit<- lm(mpg ~ hp+ wt +hp:wt, data=mtcars)
> summary(fit)
Call:
lm(formula = mpg ~ hp + wt + hp:wt, data = mtcars)
Residuals:
Min 1Q Median 3Q Max
-3.0632 -1.6491 -0.7362 1.4211 4.5513
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 49.80842 3.60516 13.816 5.01e-14 ***
hp -0.12010 0.02470 -4.863 4.04e-05 ***
wt -8.21662 1.26971 -6.471 5.20e-07 ***
hp:wt 0.02785 0.00742 3.753 0.000811 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 2.153 on 28 degrees of freedom
Multiple R-squared: 0.8848, Adjusted R-squared: 0.8724
F-statistic: 71.66 on 3 and 28 DF, p-value: 2.981e-13
> #Pr(>|t|)一栏中,马力和车重的交互项是显著的,这意味着应变量与其中一个预测变量的关系依赖于另一个预测变量的水平。此例说明:每加仑汽油行驶英里数与汽车马力的关系依车重不同而不同。
#预测模型mpg=49.81-0.12*hp-8.22*wt+0.03*hp*wt
> library(carData)
> plot(effect("hp:wt", fit,, list(wt=c(2.2,3.2,4.2))), multiline=TRUE) #需要载入effects包。
得到如下的结果

> #从图中可以看出,随着车重的增加,马力与每加仑汽油行驶英里数的关系减弱了。当wt=4.2时,直线几乎是水平的,表明随着hp的增加,mpg不会发生改变。
R语言OLS回归的基本知识到这就结束了,咱们下期再见!O(∩_∩)O哈哈~