从广义上来讲:数据结构就是
一组数据的存储结构, 算法就是操作数据的方法数据结构是为算法服务的,算法是要作用在特定的数据结构上的。
10个最常用的数据结构:数组、链表、栈、队列、散列表、二叉树、堆、跳表、图、Trie树
10个最常用的算法:递归、排序、二分查找、搜索、哈希算法、贪心算法、分治算法、回溯算法、动态规划、字符串匹配算法
本文总结了20个最常用的数据结构和算法,不管是应付面试还是工作需要,只要集中精力攻克这20个知识点就足够了。
数据结构和算法(一):复杂度、数组、链表、栈、队列的传送门
数据结构和算法(二):递归、排序、通用排序算法的传送门
数据结构和算法(三):二分查找、跳表、散列表、哈希算法的传送门
数据结构和算法(四):二叉树、红黑树、递归树、堆和堆排序、堆的应用的传送门
数据结构和算法(五):图、深度优先搜索和广度优先搜索、字符串匹配算法、Trie树、AC自动机的传送门
数据结构和算法(六):贪心算法、分治算法、回溯算法、动态规划、拓扑排序的传送门
第十一章 二分查找
一、什么是二分查找?
-
- 二分查找是对一个有序的数据集合进行查找,通过每次跟区间中间的元素对比,将待查找的区间缩小为之前的一半,直到找到元素或者区间为空为止。
-
- 对于排好序的数组来说,使用二分查找,查找某个元素的时间复杂度为:O(logn)。第一次查找时区间大小为n,第二次查找时区间大小为n/2,第三次查找时区间大小为n/4,...,第k次查找时区间为n/(2 ^ k),最坏情况下第k次的时候区间变成空了,也就是n/(2^k) = 1,k =log2n,所以时间复杂度为O(logn)。
-
- O(logn)的查找效率非常惊人,有时候甚至比常量级时间复杂度O(1)效率还要高,为什么这么说呢?logn是个非常“恐怖”的数量级,即便n非常大,对应的logn也很小。例如:2的32次方,也就是大约42亿,在42亿个数据中,使用二分查找,最多需要比较32次。而O(1)代表的常数可能是一个非常大的数字,例如O(1000)、O(10000)等等,所以常数级时间复杂度算法有时候还没有O(logn)级别的执行效率高。
二、二分查找的局限性
-
- 二分查找依赖的是顺序表结构,简单来说就是数组。因为数组通过下标随机访问的时间复杂度为O(1),而链表想要随机访问一个数时间复杂度为O(n),通过一些系列计算,我们可以分析出来基于链表的二分查找时间复杂度为O(n)。
-
- 二分查找针对的是有序数据。如果数组没有序,那我们就需要先排序,一般排序的时间复杂度最低为O(nlogn),如果我们针对的是一组静态的数据,没有频繁的插入和删除,我们可以一次排序,多次二分查找,这样排序的成本可被均摊,二分查找的边际成本就会比较低。
- 但是,如果我们的数据集合涉及到频繁的插入、删除操作,维护有序的成本都会比较高,所以二分查找只适合于插入、删除操作不频繁、一次排序多次查找的场景中。针对动态变化的的数据集合的查找,可以使用二叉树。
-
- 数据量太少不适合二分查找。如果处理的数据很少,那就完全没有必要使用二分查找了,顺序遍历就够了;当数据量比较大时,二分查找的优势才会比较明显。
- 但是有一个特例,那就是比较操作特别耗时的时候,此时不管数据量大小,都推荐使用二分查找。例如:数组中存储的是长度超过300的字符串,如此长的字符串之间的大小比较非常耗时,我们就需要尽可能的减少比较次数,减少比较次数就会大大提高性能,这时二分查找就会比顺序遍历更有优势。
-
- 数据量太大也不适合二分查找。因为二分查找的底层依赖于数组,数组这种数据结构为了支持随机访问的特性,占用的空间必须是连续的,对内存要求比较苛刻。例如我们有个1G的数据要查找,用数组存储的话就需要连续的1G内存空间,如果系统剩余的空间都是零散的,不是连续的,也就无法开辟这样的数组了。所以太大的数据用数组存储就比较吃力,也就不能用二分查找了。
三、简单二分查找的代码实现
//二分查找-循环
var array = [1,2,3,4,5,6,7,8,9,11]
func searchArray(array: Array,target: NSInteger) -> NSInteger{
var low = 0
var hight = array.count - 1
while low <= hight {
let middle = (low + hight) / 2
if target == array[middle]{
return middle
}else if target < array[middle]{
hight = middle - 1
}else{
low = middle + 1
}
}
return -1
}
searchArray(array: array, target: 10)
searchArray(array: array, target: 3)
//二分查找-递归
func searchInternally(array:Array,low:NSInteger,high:NSInteger,target:NSInteger) -> NSInteger{
if low > high{
return -1;
}
let middle = (low + high) / 2
if array[middle] == target{
return middle
}else if array[middle] > target{
let newHigh = middle - 1
return searchInternally(array: array, low: low, high: newHigh, target: target)
}else{
let newLow = middle + 1
return searchInternally(array: array, low: newLow, high: high, target: target)
}
}
func recursionSearch(array:Array,target:NSInteger) -> NSInteger{
return searchInternally(array: array, low: 0, high: array.count - 1, target: target)
}
recursionSearch(array: array, target: 10)
recursionSearch(array: array, target: 3)
四、二分查找的四个变体问题
-
- 查找第一个值等于给定值的元素
//二分查找-第一个值等于给定值的元素
var array = [1,2,3,4,5,6,6,6,7,8,9,11]
func searchFistEqual(array:Array,target:NSInteger) -> NSInteger{
var low = 0
var high = array.count - 1
while low <= high {
let middle = (low + high) / 2
if array[middle] > target{
high = middle - 1
}else if array[middle] < target{
low = middle + 1
}else{
if middle == 0 || array[middle - 1] != target{
return middle
}else{
high = middle - 1
}
}
}
return -1
}
let a1 = searchFistEqual(array: array, target: 6)
print(a1)
-
- 查找最后一个值等于给定值的元素
//二分查找-最后一个值等于给定值的元素
var array = [1,2,3,4,5,6,6,6,7,8,9,11]
func searchLastEqual(array:Array,target:NSInteger) -> NSInteger{
var low = 0
var high = array.count - 1
while low <= high {
let middle = (low + high) / 2
if array[middle] > target{
high = middle - 1
}else if array[middle] < target{
low = middle + 1
}else{
if (middle == array.count - 1 || array[middle + 1] != target){
return middle
}else{
low = middle + 1
}
}
}
return -1
}
let a2 = searchLastEqual(array: array, target: 6)
print(a2)
-
- 查找第一个大于等于给定值的元素
//二分查找-查找第一个大于等于给定值的元素
var array3 = [1,2,3,4,5,6,6,6,7,7,8,9,11]
func searchFirstResult(array: Array,target: NSInteger) -> NSInteger{
var low = 0
var high = array.count - 1
while low <= high {
let middle = (low + high) / 2
if(array[middle] >= target){
if middle == 0 || array[middle - 1] < target{
return middle
}else{
high = middle - 1
}
}else{
low = middle + 1
}
}
return -1
}
let a3 = searchFirstResult(array: array3, target: 7)
print(a3)
-
- 查找最后一个小于等于给定值的元素
//二分查找-查找最后一个小于等于给定值的元素
var array4 = [1,2,3,4,5,6,6,6,7,7,8,9,11]
func searchLastResult(array: Array,target: NSInteger) -> NSInteger{
var low = 0
var high = array.count - 1
while low <= high {
let middle = (low + high) / 2
if array[middle] <= target{
if middle == array.count - 1 || array[middle + 1] > target{
return middle
}else{
low = middle + 1
}
}else{
high = middle - 1
}
}
return -1
}
let a4 = searchLastResult(array: array4, target: 5)
print(a4)
-
- 一般情况下,凡使用二分查找能解决的,绝大部分我们更倾向于用散列表或者二叉查找树。即便是二分查找更省内存,但是毕竟内存如此紧俏的时候不多,那么二分查找真的没什么作用了吗? 实际上,二分查找更适合用在“近似”查找问题上,在这类问题上二分查找的优势比较明显,例如这几个变体问题,用其他数据结构,比如二叉树、散列表,就比较难以实现了。
五、课后题
-
- 如何求一个数的平方根?要求精确到小数点后6位
-
- 两数相除问题,可以直接去leetcode上解答
-
- 搜索旋转排序数组,可以直接去leetcode上解答
第十二章 跳表
我们知道二分查找依赖的是数组的随机访问特性,那么链表真的无法使用二分查找了吗?
一、什么是跳表
-
- 跳表使用了空间换时间的设计思想,通过构建多级索引来提高查询效率,实现了基于链表的“二分查找”,插入、删除、查找的时间复杂度都是O(logn)。(跳表其实就是链表+多级索引,索引占用了更多的内存空间,同时索引也提高了提高查找效率)
-
- 跳表的空间复杂度为O(n),可以通过改变索引构建策略,有效平衡执行效率和内存消耗。
二、跳表的索引是怎么构建的呢?
-
- 对于一个单链表来说,即便链表中存储的数据是有序的,查找一个元素也只能从头开始遍历,时间复杂度就会很高,是O(n)。

-
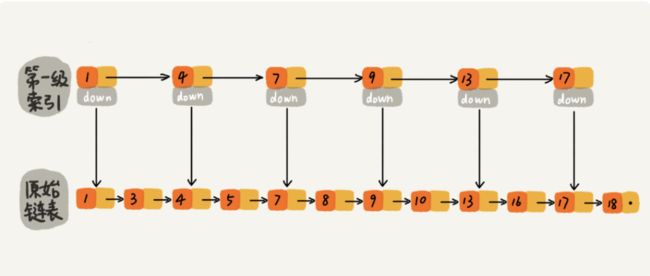
- 为了提高效率,我们像下图一样建立一级索引,每两个节点提取一个节点到上一级,提取出来的节点就构成了索引。图中的down表示down指针,指向下一级结点。
- 如下图,原来查找“16”需要遍历10个结点,建立1级索引之后,查找16只需要遍历7个结点了,查询效率提高了。
-
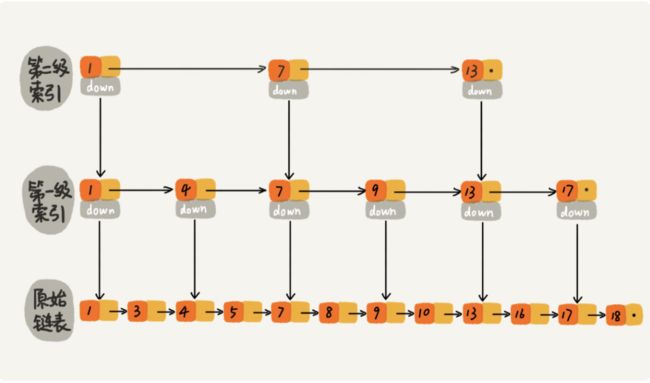
- 按照上述方式,我们在建立二级索引,查找效率又会提升很多。
- 如下图,一级索引的时候查找“16”需要遍历7个结点,建立二级索引之后,就只需要6个结点了。
-
- 由于案例中的数据量并不大,所以即便是建立了二级索引,效率提升也不是很明显,下图是包含64个结点的链表,为它建立五级索引之后,查找效率大幅提高。
- 原来没有建立索引时,查找“62”,需要遍历62个结点,建立五级索引后,只需要遍历11个结点了,查找效率大幅提高。

三、跳表的查询有多快?
跳表查询的时间复杂度为O(logn),这是怎样计算出来的呢?
-
- 假设一个链表一共有n个结点,每两个结点抽取一个建立一级索引,那么第一级索引的节点数量大约为n/2,第二级索引大约有n/4个结点,第三级索引大约有n/8个结点...
-
- 依次类推,第k级索引大约有n/(2k)个结点,已知最高等级索引有2个结点,所以当第k级索引为最高等级的索引时,即 n/(2k) = 2,k=log2n - 1,在加上原始链表这一层之后,整个跳表就有log2n个等级的索引,也可以说跳表的高度为log2n。
-
- 我们在链表中查询某个数据时,通过索引查找,不仅需要横向遍历每一级,又要一级一级往下走,所以如果每一层都要遍历m个结点,一共有log2n层,那么总共就需要遍历m * log2n个结点,时间复杂度也就是O(m * logn)
-
- 我们每两个结点取一个结点作为索引,那么每一级索引最多只需要遍历3个结点就可以了,也就是m = 3,所以时间复杂度就变成了O(3 * log2n),也就是O(logn)。
-
- 从这个分析过程我们可以看出,跳表通过建立索引进行查询,虽然额外占用了内存空间,但是可以大幅提高查找效率,这就是典型的空间换时间的设计思想。
四、跳表额外占用了多大的内存空间呢?
-
- 假设链表有n个结点,每两个结点抽取一个建立一级索引,那么第一级索引的节点数量大约为n/2,第二级索引大约有n/4个结点,第三级索引大约有n/8个结点...
2.额外使用的节点个数为n/2 + n/4 + n/8 + ... + 2,这是一个等比数列,通过公式求和,我们可以知道总共额外使用了n-2个结点,也就是空间复杂度为O(n)
3.也是就说n个结点的链表,每两个结点抽取一个建立索引,就额外需要大约n个结点存储索引。为了节省内存空间,我们可以每三个结点或每五个结点,抽取一个建立索引,额外需要的内存空间就会变成n/2或n/4.
-
- 但是实际开发中,大可不必如此在意额外内存空间,因为原始链表中存放的很可能是很大的对象,而索引结点只需要存储关键值和几个指针,并不需要存储对象,所以当对象远大于索引结点时,索引占用的内存空间就可以忽略了。
五、跳表的插入和删除
跳表插入、删除查询的时间复杂度为O(logn),这是怎样计算出来的呢?
-
- 在单链表中,一旦确认好要插入的位置,那么插入和删除操作的时间复杂度都是O(1)
-
- 在跳表中,查找某个位置需要O(logn),之后在进行插入和删除,所以跳表的插入和删除时间复杂度也是O(logn)。
六、跳表索引的动态更新
-
- 当我们不停的往跳表中插入数据,如果我们不更新索引,就有可能出现某两个索引结点中间数据非常多,极端情况下,跳表还会退化成链表。
-
- 跳表作为一种动态的数据结构,是通过随机函数来维护索引和原始链表大小之间的平衡的,也就是说,链表结点多了,索引结点也就相应增加一点,避免复杂度退化,以及查找、插入、删除性能下降。
-
- 跳表通过随机函数,来决定将这个结点插入到哪几级索引中,比例随机生成了3,那么我们就将这个结点插入到第一级索引到第三级索引,这三个等级的索引中。随机函数的选择非常有讲究,从概率上要保证跳表的索引大小和数据大小的平衡性,不至于让性能退化。
第十三章 散列表
一、什么是散列表?
-
- 散列表,也叫哈希表,利用了数组支持下标随机访问的特性,通过散列函数把元素的键值key映射为数组的下标,然后把数据存储在下标对应的位置。按照键值key查找数据时,只需要用同样的散列函数,就可以把key转化为数组下标,进而从数组下标的位置取到数据,时间复杂度为O(1)。
-
- 散列函数,在散列表中起到了非常关键的作用,它是一个函数,所以我们可以把它定义为hash(key),其中key代表元素的键值,hash(key)的值代表经过散列函数计算得到的散列值。

-
- 散列函数的设计非常考究,需要满足以下三个条件:
- (1). 散列函数计算得出的散列值是一个非负整数;
- (2). 如果key1 = key2,那么hash(k1) = hash(k2);
- (3). 如果key1 != key2,那么hash(k1) != hash(k2)。
-
- 第一点很好理解,因为数组下标从0开始的,所以需要非负整数;第二点也好理解,key相同,那么散列值也应相同;
- 第三点,看起来合情合理,但是实际情况下,想要找到key不同,散列值一定不同的散列函数几乎是不可能的,即便是业界著名的MD5、SHA、CRC等哈希算法,也无法完全避免这种散列冲突。而且数组的存储空间有限,也会加大散列冲突的概率。
二、如何解决散列冲突?
所谓散列冲突,上面也讲过了,就是key不同的时候,散列值hash(key)却意外的相同了。而且再好的散列函数也无法避免散列冲突,那么应该怎么解决呢? 常用的有两种解决办法:开放寻址法、链表法
1. 开放寻址法
(1). 开放寻址法的核心思想就是:如果出现了散列冲突,我们就重新探测一个空闲位置,插入进去。
(2). 那么如何重新探测空闲位置呢?这里介绍一个比较简单的方法:线性探测,当我们给散列表插入数据时,如果发现存储位置已经被占用了,我们就从当前位置依次往后查找,直到找到空闲位置为止。
-
(3). 探测空闲位置除了线性探测法,还有两种比较经典的探测方法:二次探测法、双重散列法。
二次探测跟线性探测很相似,线性探测每次探测的步长是1,探测的下标为hash(key) + 0、hash(key) + 1、hash(key) + 2、hash(key) + 3......,而二次探测步长是原来的二次方,探测下标为hash(key) + 02 、hash(key) + 12、hash(key) + 22、hash(key) + 32......
双重散列法,就是不仅要使用一个散列函数,而是使用一组散列函数hash1(key)、hash2(key)、hash3(key)、hash4(key)......,我们先使用第一个散列函数,如果计算得到的存储空间被占用了,在用第二个散列函数,依次类推,知道找到空闲的存储位置。
(4). 不管用哪种探测办法,当散列表中空闲位置不多时,散列冲突发生的概率都会大大提高。为了更加直观的表示散列表中的空闲位置的多少,引入了装载因子的概念,装载因子越大,说明空闲位置越少,冲突发生的概率越大,散列表的性能下降。
//装载因子用来衡量散列中空闲位置的多少
散列表的装载因子 = 填入表中的数据 / 散列表的长度
2. 链表法
-
(1). 链表法是一种更加常用的散列冲突解决办法,相比于开发寻址法,链表法要简单的多,如下图所示,在散列表中,每个桶(bucket)或者槽(slot)都会对应一条链表,所有散列值相同的元素都放在相同的槽位所对应的链表中。
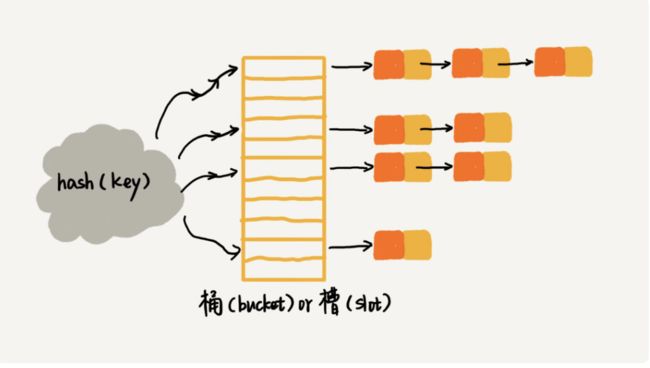 链表法
链表法 (2). 使用链表法解决散列冲突的散列表,插入元素的时候,只需要通过散列函数计算出数组下标,然后插入到下标所对应的链表中即可,所以时间复杂度为O(1)
(3). 但是查找和删除的时间复杂度就跟链表长度有关系了,如果链表长度是k的话,那么查找和删除的时间复杂度就是O(k)。如果是散列比较均匀的散列函数,分到每个槽的数据都差不多,平均链表长度k就等于数据总数/槽的个数。
三、如何设计工业级别的散列表?
散列表的查询效率不能简单地说是O(1),它跟散列函数、装载因子、散列冲突都有关系,如果散列函数设计的不好或者装载因子过高,都有可能导致散列冲突发生的概率提高,查询效率下降。
极端情况下,有些恶意攻击者,会精心构造数据,使所有的数据经过散列函数之后,都跳到同一个槽里,如果用链表法解决散列冲突,散列表就会退化为链表,时间复杂度从O(1)退化到O(n)
如果散列表中有10万条数据,那么退化后的查询效率就下降了10万倍,原先只需要0.1秒就可以查询到,现在需要1万秒,这样的查询操作就会消耗大量CPU或线程资源,导致系统无法响应其他请求,从而达到拒绝服务攻击(DOS)的目的,这就是散列表碰撞攻击的基本原理。
那么,如何设计一个可以应对各种异常情况的工业级别的散列表,避免在散列冲突的
情况下,散列表的性能急剧下降,并且能抵抗散列碰撞攻击?
1. 工业级散列表的要求
-
- 支持快速的插入、查询、删除操作
-
- 内存占用合理,不能浪费过多内存空间
-
- 性能稳定,极端情况下,散列表的性能也不能退化到无法接受。
2. 如何设计一个合适的散列函数?
-
- 散列函数设计的不能太复杂,太复杂势必会消耗很多计算时间,间接影响了散列表性能。
-
- 散列函数生成的值要尽可能随机并且均匀分布,这样才能最小化散列冲突,即便出现冲突,散列到每个槽里的数据也会比较均匀,不会出现某个槽里的数据特别多的情况。
-
- 实际工作中,还需要考虑各种因素,包括key的长度、特点、分布,还有散列表的大小。常用的设计方法有:数据分析法、直接寻址法、平方取中法、折叠法、随机数法等等。
3. 如何设计动态扩容策略?
-
- 随着不断的插入操作,装载因子不断扩大,当装载因子大到一定程度后,散列冲突就会变得不可接受。这个时候我们就需要动态扩容了,当装载因子达到一定的阈值的时候,重新申请一个更大的散列表,将数据搬移到新的散列表中。
-
- 装载因子阈值的设置要权衡时间、空间复杂度。如果内存不紧张,对执行效率要求比较高,就可以适当降低装载因子阈值;相反,如果内存空间紧张,对执行效率要求又不高,那么就可以适当增加装载因子阈值。
-
- 大部分情况下,往散列表中插入一个数据都会很快,但是当装载因子达到阈值之后,需要进行动态扩容的时候,需要新建一个更大的散列表,并且进行数据搬运操作,数据搬运的时候还得重新计算哈希值,此时就会非常耗时。
为了避免这种极个别的非常耗时操作,我们一般都会把集中一次的数据搬运操作,分散到多次操作中,当装载因子达到阈值之后,我们申请新的散列表,但并不搬移数据,当有新数据插入的时候直接插入到新的散列表,并且从旧散列表中搬运一条数据到新散列表,没有集中的搬运操作,就使得每次插入操作都很快了。
这期间的查询操作,需要先查新的散列表,再查老散列表,通过这样均摊下来,将以此扩容分摊到多次插入操作中,就可以保证任何情况下插入一个数据的时间复杂度都是O(1)了。
4. 如何选择合适的冲突解决办法?
-
- 开放寻址法的数据都在数组中,可以有效利用CPU缓存加快查询速度;但是删除数据比较麻烦,冲突的代价更高,装载因子的上限不能太大。
开放寻址法的装载因子不能超过1,接近1时,就会产生大量的散列冲突,导致大量的探测、再散列等,性能会下降很多。
而链表法的装载因子即便变成10,只要散列函数的值随机均匀,也就是链表的长度长了点而已,还是比顺序查找快多了。
总结一下: 当数据量较小、装载因子小的时候,适合采用开放寻址法。
-
- 链表法对内存利用率较高,对大的装载因子容忍度更高;但是链表的内存是零散的,对CPU缓存不友好。
- 其实我们对链表法稍加改造,将链表法中的链表改成跳表、红黑树等更高效的数据结构,就会更加高效。这样的话,即便出现散列冲突,极端情况下,所有的数据都进入到一个槽里,退化之后的查询时间也只不过是O(logn),这样就有效的避免了散列碰撞攻击。
总结一下: 链表法更适合于存储大对象、大数据量的散列表,支持更多的优化策略,例如用红黑树代替链表。
四、举例说明工业级别的散列表,以JAVA中的HashMap为例
-
- 初始大小,HashMap中的默认初始大小是16,如果事先知道大致数据量,就可以通过修改默认大小,减少动态扩容次数,提高HashMap性能。
-
- 装载因子和动态扩容,HashMap的装载因子默认是0.75,超过这个阈值,就会启动动态扩容,每次扩容都会变成原来大小的2倍。
-
- 散列冲突解决办法,HashMap底层采用链表法解决散列冲突,当链表长度过长时,链表就会转化成红黑树;当红黑树结点个数少于8个时,红黑树又会转化为链表。
-
- 散列函数,HashMap的散列函数并不复杂,追求的是简单高效、分局均匀,如下所示:
int hash(Object key) {
int h = key.hashCode();
return (h ^ (h >>> 16)) & (capitity -1); //capicity 表示散列表的大小
}
第十四章 为什么散列表和链表经常放在一起使用?
一、为什么散列表和链表经常放在一起使用?
-
- 散列表支持高效的查询、插入、删除操作,时间复杂度都是O(1),但是散列表中的数据都是通过散列函数打乱之后无规律存放的,也就是说,它无法支持按照某种顺序快速的遍历数据。
-
- 因为散列表是动态数据结构,会有很多插入或删除操作,当我们想按照顺序遍历散列表中的数据时,就需要先排序,这样效率势必会很低,为了解决这个问题,我们将散列表和链表(或者跳表)结合在一起使用。
二、如何将散列表和链表组合使用?
以一个插入、删除、查找时间复杂度均为O(1)的,LRU缓存淘汰算法为例。
-
- 先回顾一下如何用链表实现的LRU缓存淘汰算法的
(1). 我们需要维护一个访问时间从大到小有序排列的链表结构,因为缓存大小有限,当缓存空间不足时,将链表的头部结点删除。
(2). 当要插入某个数据时,先查找链表中是否存在,存在的话,就把它移动到链表尾部;不存在的话,就直接把它放到链表尾部;当要删除某个数据时,先查找到数据的位置再删除它。因为查找数据需要遍历整个链表,所以单纯用链表实现的LRU缓存淘汰算法,插入、删除、查找的时间复杂度都会很高,均为O(n)。
(3). 那么我们如何优化一下这个LRU算法,可以使得插入、删除、查找的时间复杂度都变成O(1)呢?
-
- 答案就是将散列表和链表组合使用
(1). 我们使用双向链表存储数据,链表中每个节点都需要存储:数据(data)、前驱指针(prev)、后继指针(next)、hnext指针(解决散列冲突用的)
(2). 同时呢也使用散列表存储数据(这个散列表使用链表法来解决散列冲突),所以每个节点都会在两条链中。一条是双向链表链、一条是散列表的链表链。前驱指针和后继指针是为了将结点串在双向链表中,hnext指针为了将结点串在散列表的链表中。最终组合效果如下图所示:

-
- 通过这样组合使用之后呢,查找一个数据可以直接使用散列表查找,时间复杂度就变成了O(1)了,同理删除和插入的时间复杂度也降低为O(1)了。
总结:链表的优势是可以记录顺序,散列表的优势是可以快速查找,两个结合使用,可以大幅提高效率。
第十五章 哈希算法
一、什么是哈希算法?
-
- 哈希算法的定义非常简单,一句话就可以概括,将任意长度的二进制值串映射为固定长度的二进制串,这个映射的规则就是哈希算法,原始数据经过映射得到的二进制值串,就是哈希值。
-
- 设计一个优秀的哈希算法并不容易,一般需要满足以下条件:
从哈希值不能反向推导出原始数据(所以哈希算法也叫单向哈希算法)
对输入数据非常敏感,哪怕原始数据只修改了1Bit,最后得到的哈希值也大不相同。
散列冲突的概率很小,针对不同的原始数据进行哈希,得到相同哈希值的概率很小。
哈希算法的执行效率要尽量高效,针对较长文本,也能快速计算得出哈希值。
-
- 例如经典的MD5哈希算法,即便只有一个字符不同,得到的哈希值也大相庭径。
MD5(" 我今天讲哈希算法!") = 425f0d5a917188d2c3c3dc85b5e4f2cb
MD5(" 我今天讲哈希算法 ") = a1fb91ac128e6aa37fe42c663971ac3d
-
- 哈希算法的应用非常多,这了介绍常见的7个应用:安全加密、唯一标识、数据校验、散列函数、负载均衡、数据分片、分布式存储。
二、哈希算法的应用 - 安全加密
-
- 最常见的用于加密的哈希算法有:MD5(Message-Digest Algorithm,MD5 消息摘要算法) 和 SHA(Secure Hash Algorithm,SHA 安全散列算法),除此之外,还有很多关于加密的哈希算法,例如DES(Data Encryption Standard,数据加密标准)、AES(Advanced Encryption Standard,高级加密标准)
-
- 对于加密的哈希算法而言,有两点格外重要,第一点是很难通过哈希值反向推导出原始数据,第二点是散列冲突概率要小。
-
- 无论再好的哈希算法都无法避免散列冲突,这是为什么呢?这里有一个鸽巢理论,就是说,如果有10个鸽巢,11只鸽子,那么肯定有1个鸽巢中鸽子的数量超过1只,也就是肯定有1个鸽巢存在至少2只鸽子。
-
- 同理,哈希算法产生的哈希值的长度是固定的且有限的,例如MD5哈希算法,产生的哈希值是固定128位的二进制串,能表示的数据是有限的,最多能表示2^128个数据,而我们要哈希的数据是无穷的,就必然存在哈希值相同的情况。
-
- 没有绝对安全的加密,越复杂、越难破解的加密方法,所需要的计算时间也就越长。例如SHA-265就比SHA-1更复杂、更安全,响应的计算时间也就会比较长。
三、哈希算法的应用 - 唯一标识
-
- 通过哈希算法,可以将部分数据抽取,并进行哈希,作为整体数据的唯一标识。
-
- 例如,如何从海量的图库中搜索一张图?我们就可以从图片的二进制码串抽取数据,从开头取100个字节,从中间取100个字节,从结尾取100个字节,然后将这300个字节放在一起,通过哈希算法,生成一个哈希值,作为唯一标识,通过这个唯一标识判断是否在图库中。
-
- 如果想进一步优化,我们就可以把图片的唯一标识和图片路径存储在散列表中,查询的时候,通过哈希算法对图片取唯一标识,然后去散列表中查找是否存在;如果不存在,则图片不在图库中;如果存在,就用图片路径取到图片,然后与要对比的图片一起做全量对比,完全一致,则为同一张图。
四、哈希算法的应用 - 数据校验
-
- 我们使用BT下载文件时,需要先下载文件的种子,种子里面包含了文件的哈希值,文件下载完毕后,我们对文件进行哈希得到哈希值,与种子中的哈希值进行对比,就可以知道文件是否被篡改过或者缺失过,通过这种方式,我们就可以实现数据校验。
-
- 之所以可以这样对比,是因为哈希算法有一个特点,就是对数据非常敏感,只要文件有一丁点内容改变,最后得出的哈希值也会完全不同,所以我们可以利用哈希算法数据敏感的特性,来实现数据校验。
五、哈希算法的应用 - 散列函数
-
- 散列表中的散列函数,就是哈希算法的一种应用,散列函数是散列表的关键所在,直接决定了散列冲突的概率和散列表的性能。
-
- 散列函数对是否能反向解密并不关心,更加关心散列后的值是否可以分布均匀;即便出现散列冲突也没事,只要不太过严重,都可以通过开放寻址法和链表法解决。
六、哈希算法的应用 - 负载均衡
-
- 如何实现一个会话粘滞的负载均衡算法呢?即同一个客户端,一次会话中所有的请求都路由到同一个服务器上
-
- 最简单的方法就是维护一张散列表,散列表中存放客户端IP地址与服务器编号的映射关系,客户端每次发出请求,都需要在映射表中查找服务器编号,再进行请求。这种做法很简单,但是有几个缺陷:
- 如果客户端很多,那么映射表可能会非常大,比较浪费内存空间
- 如果客户端上线、下线,映射表扩容、缩容时都会导致映射失败,需要重新维护映射表。
-
- 借助哈希算法,我们就可以很完美的解决这些问题,我们可以通过哈希算法,对客户端IP地址计算哈希值,将哈希值与服务器列表的大小进行取模运算,最终得到的值就是应该被路由的服务器编号。这样,我们就可以做到同一个IP地址过来的所有请求,都路由到同一个后端服务器上了。
七、哈希算法的应用 - 数据分片
-
- 如果我们对海量的数据进行分析,一台机器的内存不够用怎么办?我们可以采用多机分布式处理,对数据进行分片,以突破单机内存、CPU等资源的限制。具体可以这样来操作:我们将数据通过哈希算法计算出哈希值,与机器总数n进行取模,得到的值就是应该被分配到的机器编号,就可以将数据分配到不同的机器上。
-
- 例如:我们前边讲过的,如何快速判断图片是否在图库中?就是取图片的唯一标识与路径构建散列表。假设我们有1亿张图片,很显然,所需要的内存远远超过了单台机器的上限。
-
- 我们就可以使用数据分片,采用多台机器处理。从图库中取一张图,计算唯一标识,然后与机器总数n取模,得到的值就是要分配的机器编号,然后将唯一标识和图片路径发往对应的机器构建散列表,这就完成了数据分片。
-
- 判断某张图是否在图库中时,就可以通过同样的哈希算法,计算出唯一标识,然后与机器总数n取模,得到机器编号,然后去对应的机器中查询散列表。
-
- 现在,我们来计算一下,给1亿张图片构建散列表大约需要多少台机器呢?
-
- 假设我们用MD5计算哈希值,哈希值长度就是128比特,也就是16字节;文件路径平均大小是128字节;用链表法解决散列冲突的话,需要存储指针,指针占用8字节;所以散列表中的每个数据单元大约占用152个字节。
-
- 假设一台机器内存为2G大小,散列表的装载因子为0.75,那么一台机器大概可以给1000万张图片构建散列表,2x1024x1024x1024x0.75/152大约为1千万,1亿张图片大约需要10台机器。在工程中这种估算还是很重要的,能事先对需要投入的资源、资金有个大概了解,更好的评估解决方案的可行性。
八、哈希算法的应用 - 分布式存储
-
- 现在的互联网都是有海量的数据的,而海量的数据需要缓存,一个缓存机器肯定是不够的,所以我们需要将数据分布在多台机器上,这就是分布式存储的思想。
-
- 我们可以借用数据分片的思想,通过哈希算法取到哈希值,然后与机器个数取模,得到机器编号,将数据存储在对应编号的机器上。但是,这种做法会产生一个问题,就是需要扩容时,就会增加机器数,这是否取模的结果就会发生变化,导致所有数据请求都会穿透缓存,直接去请求数据库,这样就可能发生雪崩效应,压垮数据库。(例如:有10台机器,数据13与10取模得到3,去3号机器拿缓存数据,此时,增加了1台机器,数据13与11取模得到了2,就回去2号机器拿缓存数据,拿不到缓存,就会去请求数据库,从而引发雪崩,所以机器扩容、缩容后,要对数据做大量的搬移工作,以避免雪崩)
-
- 但是大量的数据迁移费时费力,有没有办法可以避免大量的数据迁移呢?一致性哈希算法就要登场了。一致性哈希算法可以使我们在新增机器后,不需要大量迁移数据。
这里有个漫画很好的解释了一致性哈希算法的原理,可以点击查看
- 但是大量的数据迁移费时费力,有没有办法可以避免大量的数据迁移呢?一致性哈希算法就要登场了。一致性哈希算法可以使我们在新增机器后,不需要大量迁移数据。