
上图Pivotal主页展示“Adopt the Silicon Valley State ofMind”, Pivotal公司是由EMC和VMware于2013年联合成立的一家新公司,定位于下一代云计算和大数据应用相结合的公司。重要的是这家成立不久的独角兽公司与一些重要的技术有着千丝万缕的关联,如Spring, Spring Boot, Redis, RabbitMQ, 而其中雇佣了一些Apache顶级项目的顶级开发者。
好了,一上来就跑题了。我们继续互联网技术架构-分布式存储。
总目录:
分布式存储概述
分布式存储特性 - 哈希分布/一致性哈希分布
分布式存储协议 - 两阶段与Paxos
1. 概述
分布式存储作为互联网之核心基石,没有分布式海量存储就好比无源之水。分布式系统不是什么新鲜事物,教科书里已经研究了好多年,但是不温不火,直到近年互联网大数据应用的兴起才使得它大规模的应用到工程实践中,其主要特点概括为:规模大+成本低。现在的大型互联网公司少则几百几千个PC服务器,多的达到数百万级别低成本PC服务器集群;
总体来说,分布式存储需要具备以下一些要素:
可扩展:灵活水平扩展到成百上千上万,并且整体性能线性增长。
低成本:构建与低成本PC,兼备自动容错,自动负载均衡等机制。
高性能:秒,毫秒,亚秒级别。
易用:构建生态环境,与其它系统集成,如监控,运维,数据导入。
分布式存储的挑战来源自于其设计的两个技术领域:分布式 + 存储:
数据分布式:数据如何分布,数据如何跨服务器读写?
一致性:数据如何replication,多个副本之间又如何同步
容错:检测,并迁移故障服务器上的数据
负载均衡:如何“空中加油”,运行中添加,卸载服务器
事务并发:分布式事务,并发控制
分布式存储数据分类:
按照其所处理的数据类型来分的话,大体分为
非结构化数据:如文本,图像,图片,视频,音频等
结构化数据:类似关系型数据库
半结构化数据:介于上面二者之间,如HTML文档,换言之其模式结构于内容混合。
分布式存储系统分类:
有了数据,我们看一下容器如何划分:
分布式文件系统:存储非结构化文件对象;如FB Haystack; GFS, HDFS
分布式键值系统:存储半结构化数据,如Amazon Dynamo, Memcache
分布式表格:存储半结构化数据,如BigTable,HBase, DynamoDB
分布式数据库:存储结构化数据,如MySQL Sharding, Amazon RDS,以及阿里OceanBase.
2. 分布式存储特性
分布式存储包括了数据的分布,复制,一致性,容错等。
一致性:分布式存储系统会将数据冗余备份,称之为replication/copy. 副本是目前分布式存储系统容错的唯一方法。如有3个客户端A,B,C
强一致:如A先写入,系统保证后续A,B,C的读去都返回最新值
弱一致:如A先写入,系统不保证后续A,B,C的读去都返回最新值
最终一致:“最终”只有个时间的延迟,如replication等,如A先写入,同时假设后续无其他更新相同的值,“最终”A,B,C都会读到A写入的最新值
数据分布:分布式存储当然会设计数据如何分布了,同时要考虑自动负载均衡
哈希分布:无需多说,类似HashMap的index了,基本思路都是选取某业务相关主键key,然后hash(key) % N(服务器数量), 当然如果这里hash函数的散列性比较好的话,数据可以比较均匀的分布到集群。
上面可以么?如果仔细看过HashMap的极客们应该知道,当HashMap的数量超过一定负载后,需要resize, rehash。这有什么问题么?内存处理当然没什么大问题,这可是分布式存储啊,你这么一resize,rehash可不得了,涉及很多数据的迁移,耗时耗力。况且,分布式会动态增加,卸载节点,都不用超过一定数量限制。如何解决?
一致性哈希(Distributed Hash Table, DHT):算法如下,给系统每个节点分配一个随机token,使得这些token构成一个哈希环,存放时,根据hash(key)的值,存放到顺时针第一个大于/等于该值的token所在节点。这样,每次节点的变更只会影响哈希环中相邻的节点,对其他没有影响。
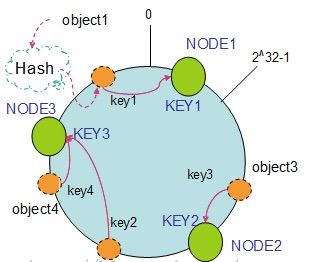
如上图所示,假设哈希空间为0-2^32-1大小:
1>首先求出每个服务器node的hash值(一般情况下对机器的hash计算是采用机器的IP或者机器唯一的别名作为输入值),将其分配到圆环上
2>采用同样算法计算待存储对象的key的hash值,将其分配到这个圆环
3>开始顺时针查找,并分配到第一个找到的服务器节点
通过上图可以看出对象与机器处于同一哈希空间中,在这样的部署环境中,
hash环是不会变更的,因此,通过算出对象的hash值就能快速的定位到对应的机器中,这样就能找到对象真正的存储位置了。
上文提到,普通hash求余最大问题就是当count也就是机器的数量变化,如添加,删除后,需要rehash,并进行位置调整。我们来看一下一致性哈希如何处理:
1. 节点删除
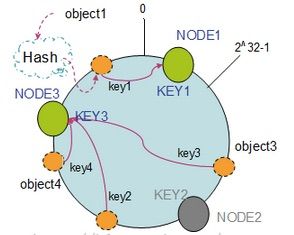
如图,灰色的node2被删除,则只需按照瞬时针迁移,object3则会被迁移到
node3中,所以仅仅会影响object3位置,其他对象无需改动。
2. 节点添加
如果我们要在集群中添加一个新的节点node4,通过哈希算法得到key4,并映射到环中。
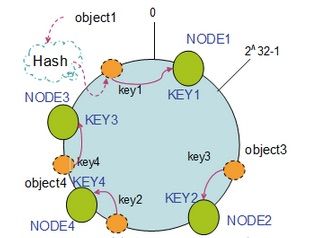
按照顺时针迁移规则,我们把object2迁移到node4中,其他object保持原位。
另外,稍微提及一下,当一致性哈希算法在服务节点太少时,容易因为节点分部不均匀而造成数据倾斜问题。为了解决这种数据倾斜问题,一致性哈希算法引入了虚拟节点机制,即对每一个服务节点计算多个哈希,每个计算结果位置都放置一个此服务节点,称为虚拟节点。
参考MIT论文:http://dl.acm.org/citation.cfm?id=258660
顺序分布:通常做法是将一个大表顺序划分成连续范围,即子表。如经常用来举例的用户表,按照主键分为1-10000,10001-20000,... 80000-90000等。再添加类似B+树索引。其中叶子相当于子表。
分布式复制:replication,常见做法类似数据库同步操作日志(commit log)
容错:容错是分布式存储系统设计的重要目标,当然是自动容错。
故障检测:心跳,通用做法。官方叫法是,Lease(租约)协议,即带有超时时间的一种授权。
故障恢复:迁移,通用做法。但是当Master节点/总控节点出现故障时,为了HA, 我们就要重新选主了,正所谓国家不可一日无主,当然现代社会,要通过Paxos协议选举,如我们介绍过的ZK.
3. 分布式协议
重要的分布式协议:Paxos选举协议与两阶段提交协议。其中Paxos协议在我们介绍ZK的时候,就有小伙伴提出详细介绍。
两阶段提交协议:Two-phase Commit, 2PC.主要用来确保多个节点或者分布式操作的原子性。如果有使用过JTA或者做过大型银行转账系统的应该使用过。
如跨数据库操作:
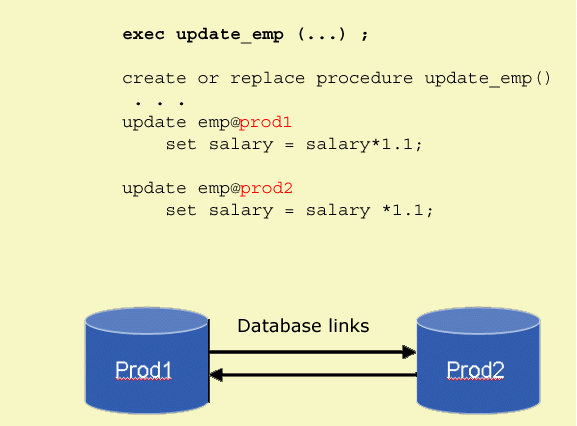
恰如其名,2PC通常分为两个阶段:
阶段1: 请求阶段Prepare Phase, 协调者通知参与者准备提交或者取消事务;
阶段2: 提交阶段Commit Phase, 协调者将阶段1的结果进行投票表决,当且仅当所有参与者同意提交事务时,协调者才通知所有参与者提交,否则通知所有参与者取消。
如下图所示:
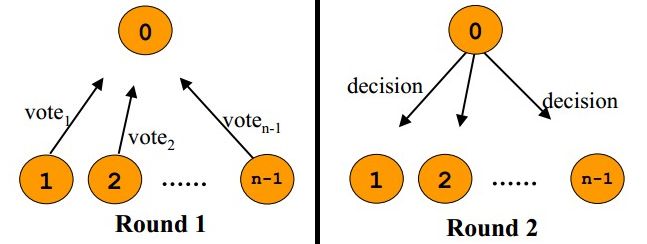
两阶段提交协议是阻塞协议,执行过程中需要加锁,且无法容错,所以... 大多数分布式存储系统都避而远之。同理可证,JTA。
Paxos协议:主要用于解决多个节点之间一致性问题。如主节点出现故障时,其它节点如何协调选主。同时,当做到了多个节点之间的操作日志一致性,就能够在这些节点上来构建高可用服务包括分布式锁,分布式命名,配置服务等。
多数情况下,系统只有一个备点提议者Proposer, 所以它的提议总是会很快被大多数节点接受。
执行步骤:
批准(accept): Proposer发送accept消息给所有其它节点(acceptor)接受某个提议,acceptor可以选择接受或者拒绝
确认(acknowledge): 如果超过一半的acceptor接受,则提议生效,proposer发送acknowledge消息通知所有acceptor提议生效
如果系统有多个proposer,则各自分别发起提议,如修改操作或者提议自己选主,如果proposer第一次发起的accept请求没有被acceptor中多数派批准,则需要进行一轮完整的Paxos协议,如下:
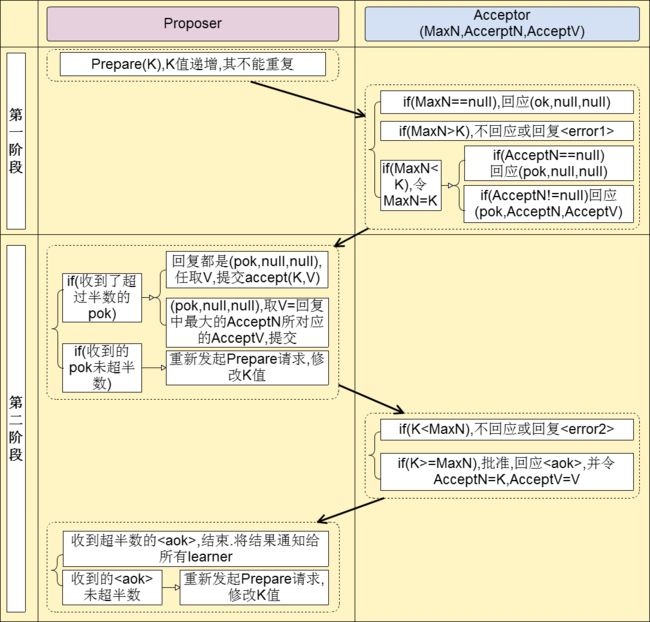
1. 准备prepare: Proposer首先选择一个提议序号n给其它acceptor节点发送
prepare消息,Acceptor收到消息后,如果提议序号已经大于它已经回复的所有prepare消息,则acceptor将自己上次接受的提议回复给proposer,并承诺不再回复小于n的提议。
2. 批准accept:Proposer收到了acceptor中多数派队prepare的回复后,就进入批准阶段。如果在之前的prepare阶段acceptor回复了上次接受的提议,则提议值发给acceptor批准。Acceptor在不违背它之前在prepare阶段的承诺前提下接受这个请求。如果超过一半的acceptor接受,提议值生效,Proposer发送acknowledge消息通知所有acceptor。
稍微有点绕,Paxos需要确保2点,正确性,即只有一个提议值会生效;可终止性,即最终会有一个提议值生效。数学语言,有且只有一个。
受限与篇幅以及时间,我们会分2篇来介绍分布式存储系统。下一篇将提及著名Google分布式数据库
“The largest single database on earth”。

公众号:技术极客TechBooster
