爬取网页数据:
1.安装selectorGadget插件
这个插件是安装在谷歌浏览器上的,长这样:

安装方法:先下载这个插件,是一个文件:
然后点击谷歌浏览器
这里,更多工具,扩展程序,把那个crx文件拖进去就好了。
2.用R语言实现网页爬取
访问https://movie.douban.com/top250网页

3.现在我们从这个网站上爬下这些数据:
Rank:电影排名(1-250)
Title:电影标题
Description:电影描述
Year:电影年份
Country:国家或地区
Genre:电影类型
Rating:用户打分
这个一个包含所有字段的页面截图
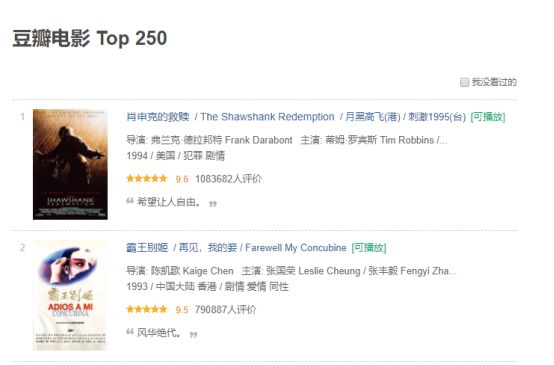
步骤1:现在我们先来爬取rank字段。为此,我们将使用Selector Gadget来获取包含排名的特定CSS选择器。您可以在浏览器中点击这个扩展程序,并用光标选择排名字段。
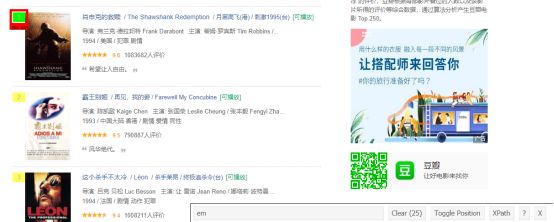
步骤2:当你确定已选择字段后,查看对应的css选择器,在底部查看
�
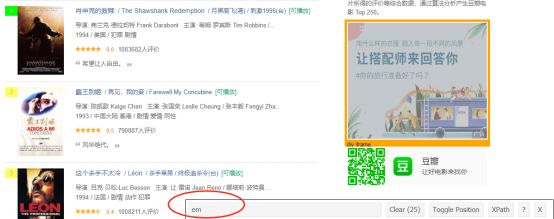
步骤3:当您知道CSS选择器已包含了排名顺序之后,您可以使用这个简单的R语言代码来获取所有的排名:
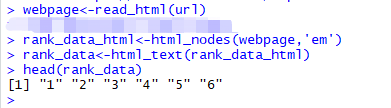
步骤4:当您有了数据后,请确保它看起来是您所需的格式。我在对数据进行预处理,将其转换为数字格式。
步骤5:现在您可以清除选择器部分并选择所有标题。您可以直观地检查所有标题是否被选中。使用您的光标进行任何所需的添加和删除。
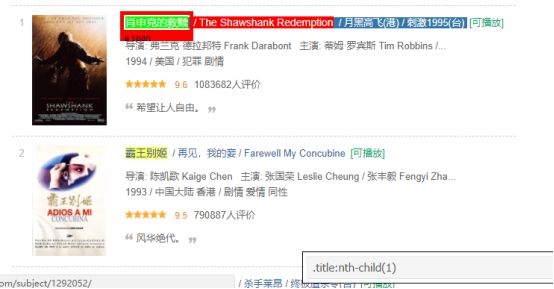
步骤6:再一次,我有了相应标题的CSS选择器:.title:nth-child(1)。我将使用该选择器和以下代码爬取所有标题。

步骤7:在下面的代码中,我对description、year、country、genre、rating做了同样的操作。

爬取电影类型gener部分
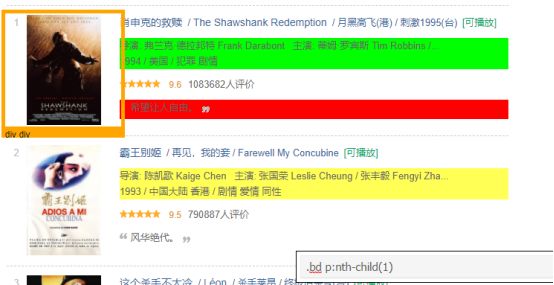
有点难度,因为不能直接定位到类型那里,我先把整个爬取下看看。

然后我采用strsplit()函数不断地对gener_data进行字符串切割直到选择到电影类型的第一个,以下是我的代码:



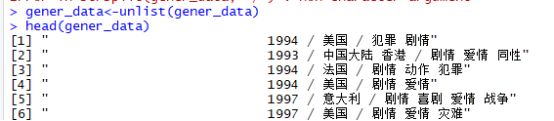



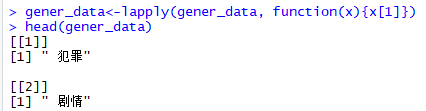

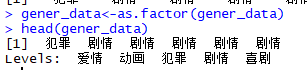
爬取year、country、rating部分也是一样的方法。
步骤8:按照这种做法,然后我突然发现这样做只是爬取了一页的数据而已,也就是第1到第25的电影,后面的数据没抓取到。我观察后发现每页的数据有规律:
这个第一页的网址:
https://movie.douban.com/top250?start=0&filter=
这是第二页的网址:
https://movie.douban.com/top250?start=25&filter=
它是有规律的,所以我才用了循环来爬取10页的数据,爬取数据的完整代码在末尾。
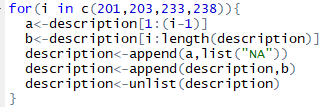
步骤9:爬完数据后验证时发现description部分,year部分,gener部分还有country部分有错误。

人为查找之后发现description部分缺失的是201,203,233,238
修改:
而年份,国家和剧情出现错误是因为排行78的电影那里出现错误:
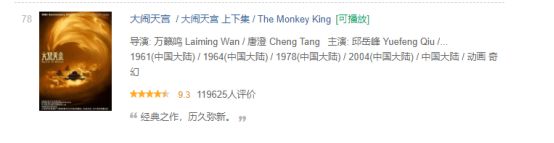
所以我着重查看那个位置爬下来的数据并进行修改,代码如下:

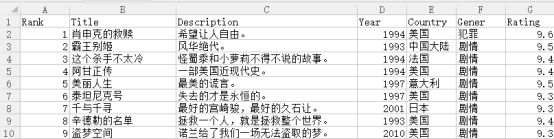
步骤10:将数据整理到一起:

结果发现数据有些原因,没办法我就在excel表上进行修改了,变成下表:
对爬取的数据进行可视化分析

(1)哪种类型的电影更受欢迎

可以看到剧情类电影大受欢迎,其次是喜剧,动作,犯罪跟动画。其实网页数据显示电影类型都多个,但是我只选择了第一个,可能有点影响。
(2)哪个时期的电影更受青睐

就这份榜单来讲,20世纪的电影更多一些。
�(3)哪个地区的电影更受欢迎
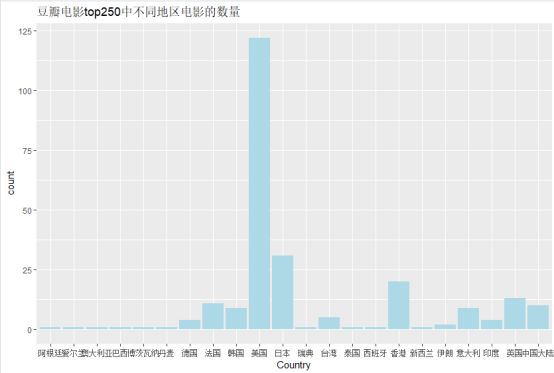
从这个图可以看到,美国的电影最受欢迎,影响也最广,毕竟好莱坞不是盖的哈哈。其次是日本电影,香港电影,英国,法国跟我们内地的电影。我个人也很喜欢日本电影,真的很有韵味。
这个分析我就做到这里啦,第一次做第一次发表,有很多不对的地方欢迎指出谢谢!
参考资料:https://mp.weixin.qq.com/s/mIL-p2q7Jp-dhkXkDIrdHQ
爬取网页数据完整代码:
library(rvest)
for (i in 0:9) {
url<-paste('https://movie.douban.com/top250?start=',25*i,'&filter=&type=',sep="")
webpage<-read_html(url)
#使用css选择器爬取rank排名部分
rank_data_html<-html_nodes(webpage,'em')
rank_data<-html_text(rank_data_html)
rank_data<-as.numeric(rank_data)
#使用css选择器爬取电影标题title部分
title_data_html<-html_nodes(webpage,'.title:nth-child(1)')
title_data<-html_text(title_data_html)
#爬取电影描述description部分
description_data_html<-html_nodes(webpage,'.inq')
description_data<-html_text(description_data_html)
description_data<-unlist(description_data)
#爬取电影类型gener、年份year、国家country部分
total_data_html<-html_nodes(webpage,'.bd p:nth-child(1)')
total_data<-html_text(total_data_html)
total_data<-strsplit(total_data,'\n')#按\来划分内容,向量变成了列表
total_data[1]<-NULL#爬下来的第一个元素是“豆瓣”,是不要的,要删掉
total_data<-lapply(total_data,function(x){x[-c(1,2,4)]})#去除不要的内容,只保留含有年份,国家,电影类型的元素
total_data<-unlist(total_data)#将列表转为向量再操作
total_data<-strsplit(total_data,'/')
#选择年份部分
year_data<-lapply(total_data, function(x){x[-c(2,3)]})
year_data<-unlist(year_data)
year_data<-sub("^\\s+","",year_data)
#选择国家部分
country_data<-lapply(total_data, function(x){x[-c(1,3)]})
country_data<-unlist(country_data)
country_data<-strsplit(country_data,' ')
country_data<-lapply(country_data, function(x){x[1]})
country_data<-unlist(country_data)
#选择电影类型部分
gener_data<-lapply(total_data,function(x){x[-c(1,2)]})
gener_data<-unlist(gener_data)
gener_data<-strsplit(gener_data,' ')
gener_data<-lapply(gener_data,function(x){x[1]})
gener_data<-unlist(gener_data)
#爬取评分部分rating
rating_data_html<-html_nodes(webpage,'.rating_num')
rating_data<-html_text(rating_data_html)
rating_data<-as.numeric(rating_data)
#将爬取的特征整合到一个数据框
if(i==0){
rank<-rank_data
title<-title_data
description<-description_data
year<-year_data
country<-country_data
gener<-gener_data
rating<-rating_data
} else {
rank<-c(rank,rank_data)
title<-c(title,title_data)
description<-c(description,description_data)
year<-c(year,year_data)
country<-c(country,country_data)
gener<-c(gener,gener_data)
rating<-c(rating,rating_data)
}
}
for(i in c(201,203,233,238)){
a<-description[1:(i-1)]
b<-description[i:length(description)]
description<-append(a,list("NA"))
description<-append(description,b)
description<-unlist(description)
}
for (i in c(78)) {
c<-country[1:(i-1)]
d<-country[(i+4):length(country)]
country<-append(c,list("香港"))
country<-append(country,d)
country<-unlist(country)
}
for (i in c(78)) {
m<-gener[1:(i-1)]
n<-gener[(i+4):length(gener)]
gener<-append(m,list("动画"))
gener<-append(gener,n)
gener<-unlist(gener)
}
for (i in c(78)) {
e<-year[1:(i-1)]
f<-year[(i+3):length(year)]
year<-append(e,list("1961","1997","1987"))
year<-append(year,f)
year<-unlist(year)
}
for (i in c(81,82,83)) {
year<-year[-i]
}
length(rank)
length(title)
length(description)
length(year)
length(country)
length(gener)
length(rating)
movie_df<-data.frame(Rank=rank,Title=title,Description=description,Year=year,Country=country,Gener=gener,Rating=rating)
str(movie_df)
head(movie_df)
write.csv(movie_df,"doubanmovietop250.csv",row.names = FALSE)