Scrapy-redis分布式爬虫+Docker快速部署
打算爬一个网站的数据,量比较大,url链接从0开始达到2亿,刚开始用request递归写了个爬虫,发现速度低的可怜,不算任何的错误,也只能达到.5秒一个请求,这速度实在不能忍,所以想着用分布式爬虫,所以才有了这篇文章
开发环境+框架、库
开发环境:macOS High Sierra 10.13 Python3.5
开发工具:PyCharm
Python库:pymysql、scrapy、scrapy-redis、requests、BeautifulSoup4、redis-py
运行环境:Centos7.4 Centos6.9 Docker
开始搭建环境
安装Python3Windows请自行查找教程安装、Mac用户系统自带了Py2.6,我建议升级到Python3,用HomeBrew安装即可
Homebrew安装命令
/usr/bin/ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"
然后使用brew install python安装Python3
安装成功后再终端输入python3查看是否安装成功,如果输入python默认使用本机的py2,当然也可以去配置文件设置个alias将python设置成启动py3

如图安装成功
然后用
easy_install pip安装
Python的包管理工具
pip
注意:有的人用的是Anaconda作为py环境,我刚开始也是用的Anaconda,但是在install scrapy-redis的时候发现无法导入,默认源都没有这个库,但我没找到哪个源有,所以强制切换了本机环境为brew的python3,如果你能用conda install scrapy-redis那就不用切换
切换环境:
在终端输入which python3
将下面的路径复制出来
打开
Finder按
Command + Shift + G输入
~/找到
.bash_profile文件

如果没有这个文件的,先看一下是否开启了显示隐藏文件功能,没开始可以使用
Command + Shift + .开启,如果你的系统不是
macOS Sierra及之后的系统,那么需要使用命令
defaults write com.apple.finder AppleShowAllFiles -bool true来开启隐藏文件功能(需要强制重启
Finder生效)
打开.bash_profile文件
将
Anaconda的环境变量注释掉,将
brew安装的写入进去,路径就是上面
which python3获得的,最后
bin后面换成
${PATH}即可,然后输入
source ~/.bash_profile使之立即生效,然后终端查看一下,是否已经切换成功(刚开始路径是
anaconda)
开始安装第三方库
pip install requests scrapy scrapy-redis redis BeautifulSoup4
至此环境方面的东西已经处理完
简单原理介绍
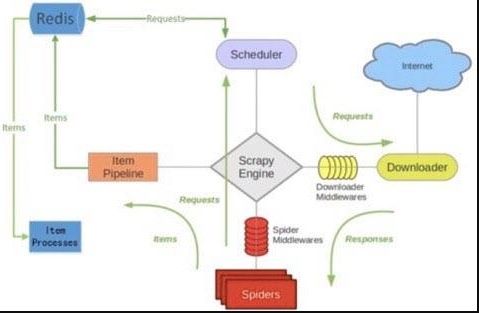
这是在网上找了一张图,很好的解释了
scrapy-redis原理,我简单的描述下主要原理
使用
redis来维护一个
url queue,然后
scrapy爬虫都连接这一个
redis获取
url,且当爬虫在
redis处拿走了一个
url后,
redis会将这个
url从
queue中清除,保证不会被2个爬虫拿到同一个
url,即使可能2个爬虫同时请求拿到同一个
url,在返回结果的时候
redis还会再做一次去重处理,所以这样就能达到分布式效果,我们拿一台主机做
redis queue,然后在其他主机上运行爬虫.且
scrapy-redis会一直保持与
redis的连接,所以即使当
redis queue中没有了
url,爬虫会定时刷新请求,一旦当
queue中有新的
url后,爬虫就立即开始继续爬.
创建工程
打开终端随便找个空目录运行scrapy startproject projectname来初始化一个scrapy项目
目录结构如下
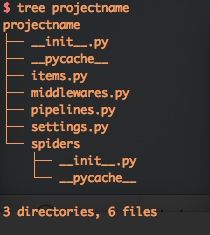
用Pycharm打开(其他工具也可)
工程需要修改地方主要在于Spider和settings,其他的都和正常Scrapy项目一样
首先是Spider,我们新建的一般都是继承与scrapy.Spider,要使用Scrapy-redis需要继承RedisCrawlSpider,引入from scrapy_redis.spiders import RedisCrawlSpider,且不再需要start_urls,用redis_key来取代
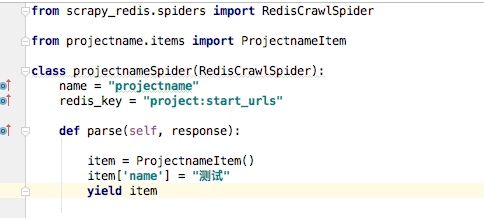
修改setting.py,添加以下选项
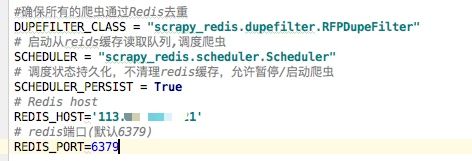
如果需要将
item结果返回到
redis需要使用
scrapy_redis提供的
pipelines,如下

其余都按
Scrapy正常项目编写
主服务器环境搭建
主要就安装redis开启外网访问
我这里环境是Centos 6.9
1、直接使用yum安装
yum install redis
2、启动redis
systemctl start redis.service
3、设置开机启动(非必要)
systemctl enable redis.service
4、设置redis密码(非必要)
打开文件/etc/redis.conf,找到其中的# requirepass foobared,去掉前面的#,并把foobared改成你的密码
如果是本地安装了redis想测试的话,Mac上启动redis是使用redis-server命令

然后新开个终端使用
redis-cli连接

服务器上也是一样的使用
redis-cli连接
注意:服务器上搭建的redis外网应该是无法访问,需要修改配置文件,如果是Mac运行的话,配置文件路径在启动redis的时候会写,上图中有,如果是Centos安装的redis,默认是在/etc/redis/redis.conf下,如果没有就在redis的安装目录下
将下图标记处的bind 127.0.0.1加上#,然后重启一下redis外网即可链接
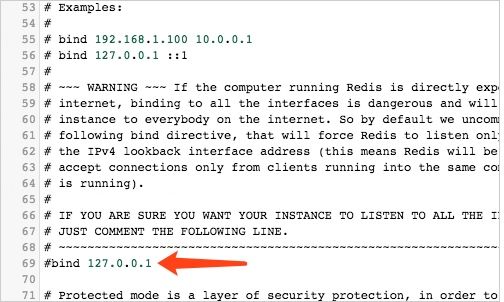
测试连接

子服务器跑爬虫
用其他服务器运行爬虫(也可以用运行redis的服务器)
通过ftp、scp等方式将爬虫上传至服务器上
然后在子服务器上也安装python3和pip
命令依次是
yum install python34
yum install python34-setuptools
easy_install-3.4 pip
yum install -y python34-pip.noarch python34-devel.x86_64
最后一条不安装的话用pip会出现报错
然后安装一下第三方库
pip install requests scrapy scrapy-redis redis BeautifulSoup4
最后运行爬虫
scrapy runspider vmSpider.py
最后的参数是你的Spider名字
如下图,爬虫启动成功,等待url待爬
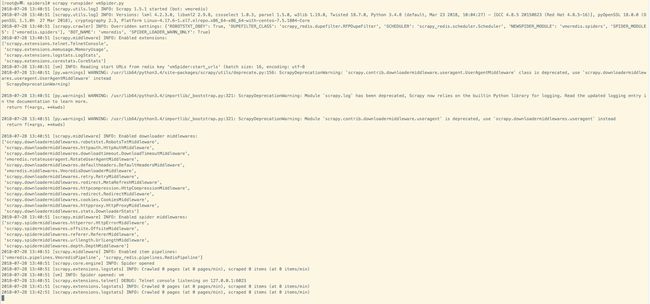
测试
连接主服务器,往redis中push一条url

返回子服务器可以看到,爬虫已经将我刚刚添加的那条
url给请求了

且根据我的提取规则把我要的数据也提取了出来并且也帮我把数据返回到了
redis里
而
redis里的urls就又是空的了
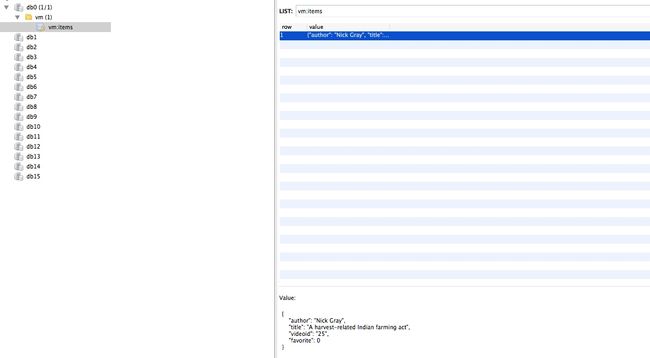
为了对比一下,我把爬虫关掉,又添加了一条
url
可以看到现在
url就在
redis里了

综上,我们的效果已经达到了,可以在多台服务器上跑爬虫了,然后在主服务器上的
redis里会把爬回的数据汇总
处理返回的数据
scapy-redis把数据全部返回到了redis里,我们不可能等它留在那,得想办法提取出去,我这里是提取到MySQL中,这个我的思路就是,直接在主服务器上跑个脚本去redis里提取就行了
直接上代码
import redis
import json
import pymysql
import logging
import time
# mysql
connection = pymysql.connect('127.0.0.1', 'vdata', 'root', 'vdata', 3306)
cursor = connection.cursor()
# redis
pool = redis.ConnectionPool(host='127.0.0.1', port=6379, decode_responses=True)
r = redis.Redis(connection_pool=pool)
r.pipeline()
# log
logging.basicConfig(level=logging.ERROR,
format='%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)s',
datefmt='%a, %d %b %Y %H:%M:%S',
filename='myapp.log',
filemode='a')
while True:
print('循环中')
k,v = r.blpop(['vm:items'])
result = json.loads(v)
title = result['title']
videoid = result['videoid']
author = result['author']
fav = result['favorite']
sql = 'insert into vindex(title, videoid, author,favorite)(select "%s","%s","%s","%s" from dual where not exists(select * from vindex where videoid="%s"))' % (
title, videoid, author, fav, videoid)
try:
n = cursor.execute(sql)
connection.commit()
if n == 0:
print('数据已存在...')
except Exception as err:
connection.rollback()
print('插入数据库错误,数据库回滚,错误信息:' + str(err))
logging.error(str(title) + '------insert Error:' + str(err))
代码中关键部分是k,v = r.blpop(['vm:items']),这句会去redis里获取items list中第一行的值,获取到了就将redis里的这个值删除,然后我们存到数据库里,当然我在数据库sql里也做了下重复数据不允许插入,然后我们在服务器上跑这个脚本就行了
流程就成了爬虫从redis获取url,然后返回请求的数据到redis,脚本从redis获取数据到mysql存储.挺完美的,缺点也有,目前没有做错误处理,如果url拿走了没请求成功就不知道了,下次添加个中间件,把失败的url也返回到redis,然后根据状态码重新添加回queue让爬虫继续爬.
Docker
虽然看上去挺不错了,但是发现个问题,我到一台服务器上部署的时候,就得走一遍安装python``pip第三方库这样的流程,虽然也不麻烦,但是感觉还是不够省事,然后就发现了Docker
注意:Docker要求Centos内核版本要高于3.1,而Centos6.9默认是2.6,查看内核命令uname -r
如果不是3.1的内核装不上
Docker,办法可以升级内核或者升级
Centos7,如果只是升级内核的话,
Docker是无法安装到最新版本的,但我由于服务器里数据较多,就只选择升级了内核
1、安装elrepo yum 源(提供内核更新、硬件驱动等软件源支持)
rpm --import https://www.elrepo.org/RPM-GPG-KEY-elrepo.org
rpm -Uvh http://www.elrepo.org/elrepo-release-6-8.el6.elrepo.noarch.rpm
2、内核升级
yum --enablerepo=elrepo-kernel -y install kernel-lt
3、修改引导文件
vi /etc/grub.conf
将
default设置成0``default=0表示使用第一个内核启动
4、重启服务器
reboot
5、查看内核
uname -r看看是否已经是3.1以上了
安装Docker
#安装 Docker
yum -y install docker
#启动 Docker 后台服务
service docker start
#测试运行 hello-world
docker run hello-world
然后我们来让Docker帮我们自动化,需要使用到Docker Compose做编排服务
首先安装一下Docker Compose,这里可以用pip安装,但使用pip安装就违背我们的初衷了,还得先装python,所以我们用官方推荐的方式curl
sudo curl -L https://github.com/docker/compose/releases/download/1.22.0/docker-compose-$(uname -s)-$(uname -m) -o /usr/local/bin/docker-compose
sudo chmod +x /usr/local/bin/docker-compose
$ docker-compose --version
docker-compose version 1.22.0, build 1719ceb
先在我们的项目目录下建立3个文件docker-compose.yml``Dockerfile``requirements.txt
第一个文件docker-compose.yml
version: '3'
services:
spider:
build: .
volumes:
- .:/code
- 代表使用V3版本的写法
- services(v1版本没services)
- 建立一个名为spider的services
- 用当前目录下的
Dockerfile构建服务 - 装载路径,将当前目录下的文件装载到容器的/code目录下(会自动建立文件夹)
第二个文件Dockerfile
#Python3作为基础映像
FROM python:3.5
#设置环境变量,使用which Python可以查看
ENV PATH=/usr/local/bin:$PATH
#添加当前目录到容器里
ADD . /code
#设置容器工作路径
WORKDIR /code
#安装Python插件
RUN pip install -r requirements.txt
# #设置容器工作目录
WORKDIR /code/vmoredis/vmoredis/spiders
# #运行命令
CMD /usr/local/bin/scrapy runspider vmSpider.py
这里要注意,先设置工作路径为/code是为了能运行pip,运行完了再将路径设置到Spider下,才能访问到Spider文件,不然就提示找不到对应的py文件
第三个文件requirements.txt
BeautifulSoup4
scrapy
scrapy_redis
redis
pymysql
requests
就是我们需要安装的python库
上传服务器测试
上传文件到服务器,目录如下

cd到根目录下,运行
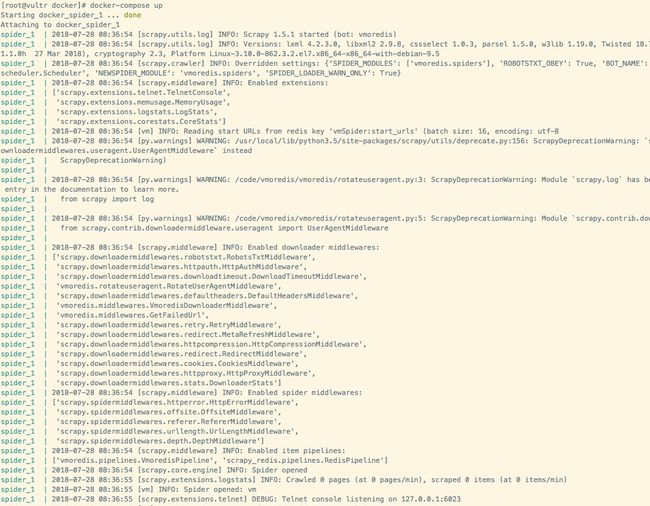
docker-compose up
注意:这里有个问题,就是我之前测试的时候运行了
docker-compose up,后来我换了正式的文件,发现还是之前的报错

这个
test.py是我测试时运行的,现在居然还是这个错误,我以为是缓存,在网上搜索了,说要加参数
--no-recreate啥的,最后去看了文档才知道,改变了
Dockerfile是需要用
build命令重构才行,意思先
docker-compose build再
docker-compose up就可以了
如图启动成功,只需要安装docker,然后这些依赖啥的自动就好了,省事,虽然要安装
docker,但是
docker可以开多个服务例如
docker-compose scale spider=4,也可以自己搭建仓库注册镜像,就更省事了