不用Selenium如何爬课表。
首先先看下工大的信息门户的网页,分析下:

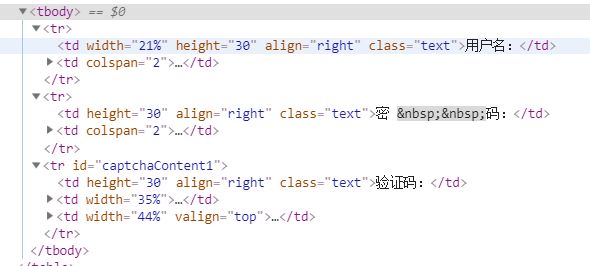
先用py获取下网站的源码吧。
import requests
session = requests.session()
res = session.get("http://my.hfut.edu.cn/login.portal")
with open("1.html", "wb") as f:
f.write(res.content)

所以验证码是这个死的图片了?这想想都不科学,这个图片访问多少回都不变的...
不知道验证码的请求是什么,那就用Fiddler抓包看看登录过程中访问了什么页面。

显然第15个有点意思,/captchaGenerate.portal,看来就是他了。
先用浏览器访问下试试,发现每次都不一样,现在十分放心QAQ
下载验证码图片保存到本地肯定不难,直接
captchaImg = session.get("http://my.hfut.edu.cn/captchaGenerate.portal", stream = True).content
# stream = True 的作用是避免把下载的文件储存在内存中
with open("captchaImg.jpg", "wb") as f:
f.write(captchaImg)
打开这个图片也不难,先手动输入吧
from PIL import Image
# 先找到文件路径吧
jpg = Image.open(("{}/captchaImg.jpg").format(os.getcwd()))
# 打开这个图片
jpg.show()
# 手动输入
captcha_code = input("请输入验证码:")
jpg.close()
再开下Fiddler,不如先登录下,看看登录过程中访问了什么页面。
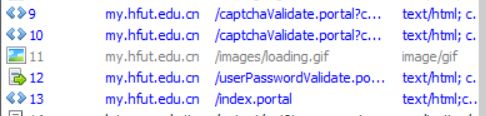
嗯,目测就是第12个了,看下表单。
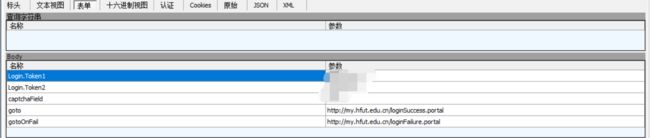
哎呦不错,现在可以构造post内容了(居然明文传输,不怕泄露密码吗
data = {
"Login.Token1" : username,
"Login.Token2" : password,
"captchaField" : captcha_code,
"goto" : "http://my.hfut.edu.cn/loginSuccess.portal",
"gotoOnFail" : "http://my.hfut.edu.cn/loginFailure.portal"
}
假如发生了什么错误怎么处理,于是就有了下面这段神奇的代码(一点都不神奇,手动滑稽,上大学了连自己学号密码都记不住,还是说验证码输错了
try:
loginres = session.post("http://my.hfut.edu.cn/userPasswordValidate.portal", data = data)
logcont = loginres.text
# print(logcont)
if logcont.find("验证码非法") != -1 :
print("验证码非法")
raise RuntimeError("验证码非法")
elif logcont.find("用户不存在或密码错误") != -1:
print("用户不存在或密码错误")
raise RuntimeError("用户不存在或密码错误")
print("登陆成功")
except:
print("登录失败")
exit(0)
接下来就可以访问本科教务的那个页面了。
session.get("http://jxglstu.hfut.edu.cn/eams5-student/wiscom-sso/login")
先看看课表页面的组成,以我的为例,http://jxglstu.hfut.edu.cn/eams5-student/for-std/course-table/info/97097,貌似最后一项数字有点别的含义嗷
Fiddler抓包发现他是页面跳转的,从http://jxglstu.hfut.edu.cn/eams5-student/for-std/course-table跳转到那个页面的,所以访问肯定直接访http://jxglstu.hfut.edu.cn/eams5-student/for-std/course-table就行了。
看下网页源代码
res = session.get("http://jxglstu.hfut.edu.cn/eams5-student/for-std/course-table")
with open("2.html", "wb") as f:
f.write(res.content)
你会发现它什么都没有...估计是ajax动态生成的...不如开始Fiddler抓包
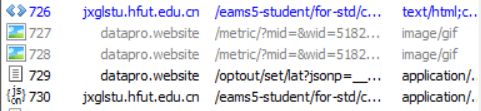
然后你就发现了这个神奇的网址
/eams5-student/for-std/course-table/get-data?bizTypeId=2&semesterId=74&dataId=97097
这个dataId很显然能拿到,就是访问那个跳转后的网址最后面的,这个semesterId和bizTypeId咋拿到呢
首先吧,底下有一堆转义字符的json,让人很不爽,一开始估计这俩东西就在这里面。
用py解析下这段json试试。
在这里我发现了一种叫unicode-escape的特殊的decode方式,然后就解析出来了。
# 查找课表
tableres = session.get("http://jxglstu.hfut.edu.cn/eams5-student/for-std/course-table/get-data?bizTypeId=2&semesterId=74&dataId=97097)
src = str(BeautifulSoup(tableres.content, "lxml").select("body script")[1].string)
src = '[' + re.search("(?<='\[).*?(?=\]')", src).group() + ']'
# src = src[src.find("'[")+1:src.find("]'")+1]
src = src.encode().decode("unicode-escape")
myjson_d = json.loads(src)
这个里面的确有semesterId,但是bizTypeId是什么玩意?
于是我在源码中搜索,很快就找到了。
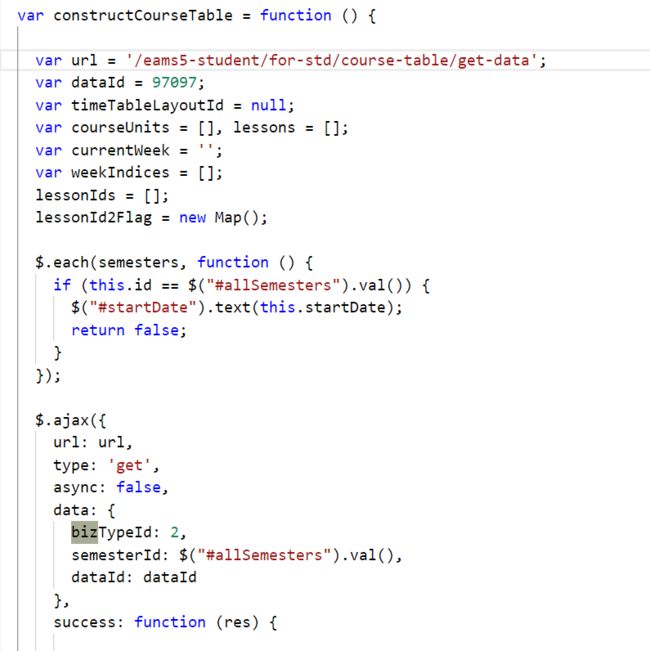
这不就是ajax的源码吗...allSemesters?是不是在源码里有呢...其实一搜索就发现了
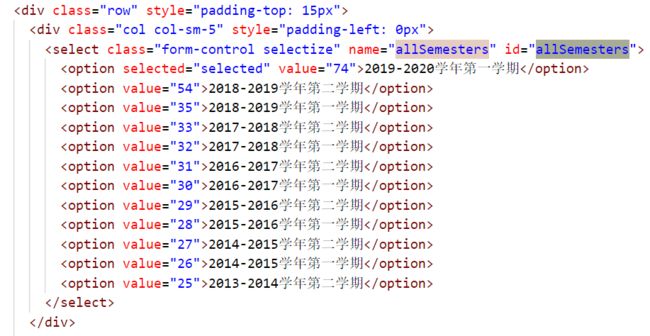
完全不用解析那个辣鸡的json...
访问那个页面出来的是意料之中的json,解析课表的那个js完全暴露在源码中,直接看看就能转换,然后就完事了。
当然,我还想获取下姓名和学号,这个全是静态的,方法基本就用BeautifulSoup直接就能出来,我就不写了。
import json
import os
import re
import requests
from bs4 import BeautifulSoup
from PIL import Image
# 账号密码学期
username = input("请输入学号:")
password = input("请输入密码:")
term = [
"2019-2020学年第一学期",
"2018-2019学年第二学期",
"2018-2019学年第一学期",
"2017-2018学年第二学期",
"2017-2028学年第一学期",
"2016-2017学年第二学期",
"2016-2017学年第一学期",
"2015-2016学年第二学期",
"2015-2016学年第一学期",
"2014-2015学年第二学期",
"2014-2015学年第一学期",
"2013-2014学年第二学期",
]
print("请选择学期序号:")
for i in range(0, len(term)):
print(i ,".", term[i])
term = term[int(input())]
# 初始化请求
session = requests.session()
session.headers["User-Agent"] = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36"
# 请求页面,构造Session
session.get("http://my.hfut.edu.cn/login.portal")
# 请求验证码
captchares = session.get("http://my.hfut.edu.cn/captchaGenerate.portal", stream = True)
captchaimg = captchares.content
# 将验证码写入文件
try:
with open(username + "captchaimg.jpg", "wb") as f:
f.write(captchaimg)
except:
exit(0)
del f
del captchaimg
del captchares
# 手动输入验证码
jpg = Image.open(("{}/" + username + "captchaimg.jpg").format(os.getcwd()))
jpg.show()
captcha_code = input("请输入验证码:")
jpg.close()
del jpg
# 构造post内容
data = {
"Login.Token1" : username,
"Login.Token2" : password,
"captchaField" : captcha_code,
"goto" : "http://my.hfut.edu.cn/loginSuccess.portal",
"gotoOnFail" : "http://my.hfut.edu.cn/loginFailure.portal"
}
# 请求
try:
loginres = session.post("http://my.hfut.edu.cn/userPasswordValidate.portal", data = data)
logcont = loginres.text
# print(logcont)
if logcont.find("验证码非法") != -1 :
print("验证码非法")
raise RuntimeError("验证码非法")
elif logcont.find("用户不存在或密码错误") != -1:
print("用户不存在或密码错误")
raise RuntimeError("用户不存在或密码错误")
print("登陆成功")
except:
print("登录失败")
exit(0)
del captcha_code
del logcont
del loginres
# 登录本科教务
session.get("http://jxglstu.hfut.edu.cn/eams5-student/wiscom-sso/login")
# 访问课表页面
tableres = session.get("http://jxglstu.hfut.edu.cn/eams5-student/for-std/course-table/")
# 获取dataID
dataId = tableres.url
dataId = dataId[dataId.rfind('/')+1:]
# 写入源代码到文件
# a_file = open("tmp.temp", "wb")
# a_file.write(tableres.content)
# a_file.close()
# # 获取页面中的脚本文件,获取学期的Id
# src = str(BeautifulSoup(tableres.content, "lxml").select("body script")[1].string)
# src = '[' + re.search("(?<='\[).*?(?=\]')", src).group() + ']'
# # src = src[src.find("'[")+1:src.find("]'")+1]
# # 处理下那个json,因为有部分\u字符
# src = src.encode().decode("unicode-escape")
# # 将json转换为字典数组
# myjson_d = json.loads(src)
# ansi = 0
# for i in range(0, len(myjson_d)):
# if myjson_d[i]["name"] == term:
# break
# semesterId = myjson_d[i]["id"]
# del i
# del myjson_d
# del src
# del tableres
# 获取学期Id
semidarr = BeautifulSoup(tableres.content, "lxml").find(id = "allSemesters").contents
for i in range(1, len(semidarr), 2):
if semidarr[i].string == term:
break
semesterId = semidarr[i].attrs["value"]
del i
del semidarr
# 查找姓名和班级
soup = BeautifulSoup(session.get("http://jxglstu.hfut.edu.cn/eams5-student/for-std/student-info/").content, "lxml")
namestr = soup.find_all(class_ = "list-group-item text-right")[1].contents[3].text
clsstr = soup.find_all(class_ = "rounded info-page")[1].contents[5].contents[35].string
del soup
# 查找课表
a = session.get("http://jxglstu.hfut.edu.cn/eams5-student/for-std/course-table/get-data?bizTypeId=2&semesterId=" + str(semesterId) + "&dataId=" + str(dataId))
# print(a.content)
with open("table.json", "wb") as f:
f.write(a.content)
# 将json转换为字典数组
table_json = json.loads(a.content)
print(table_json)
# 根据字典数组写入文件
table_arr = [
"序号 课程代码 课程名称 教学班代码 教学班名称 课程类型 开课部门 授课教师 日期时间地点人员 已排课时 已选学生数 教材 备注\n"
]
c = " "
for i in range(0,len(table_json["lessons"])):
itm = ""
# 序号
itm += str(i + 1) + c
# 课程代码
itm += table_json["lessons"][i]["course"]["code"] + c
# 课程名称
itm += table_json["lessons"][i]["course"]["nameZh"] + c
# 教学班代码
itm += table_json["lessons"][i]["code"] + c
# 教学班名称
itm += table_json["lessons"][i]["nameZh"] + c
# 课程类型
itm += (table_json["lessons"][i]["courseType"]["nameZh"] if (table_json["lessons"][i]["courseType"] != None) else "") + c
# 开课部门
itm += table_json["lessons"][i]["openDepartment"]["nameZh"] + c
# 授课教师
teacherStr = ""
for obj in table_json["lessons"][i]["teacherAssignmentList"]:
teacherStr += obj["person"]["nameZh"] + "(主讲)" if obj["role"] == "MAJOR" else "(助讲)" if obj["role"] == "MINOR" else "(助理)" if obj["role"] == "ASSISTANT" else ""
teacherStr += ' '
itm += teacherStr + c
del teacherStr
# 日期时间地点人员
flag = table_json["lessonId2Flag"][str(table_json["lessons"][i]["id"])]
if flag == "publish":
if table_json["lessons"][i]["scheduleText"]["dateTimePlacePersonText"]["textZh"] != None:
itm += table_json["lessons"][i]["scheduleText"]["dateTimePlacePersonText"]["textZh"].replace("\n", "")
else:
itm += ""
elif flag == "noPublish":
itm += "未发布"
elif flag == "dontNeedSchedule":
itm += "不排课"
del flag
itm += c
# 已排课时
itm += str(table_json["lessons"][i]["actualPeriods"]) + c
# 已选学生数
itm += str(table_json["lessons"][i]["stdCount"]) + c
# 教材
courseTextbookStat = table_json["courseId2CourseTextbookStat"][str(table_json["lessons"][i]["course"]["id"])]
textbookName = '-'
if courseTextbookStat != None:
if courseTextbookStat["textbook"] != None:
textbookName = courseTextbookStat["textbook"]["name"]
elif courseTextbookStat["notPublishTextbook"] != None:
textbookName = courseTextbookStat["notPublishTextbook"]
itm += textbookName + c
del textbookName
del courseTextbookStat
# 备注
itm += table_json["lessons"][i]["remark"] if table_json["lessons"][i]["remark"] != None else ""
table_arr.append(itm)
table_arr.append('\n')
with open("table.txt", "w") as f:
f.write("姓名:" + namestr + '\n')
f.write("学号:" + username + '\n')
f.write("学期:" + term + '\n')
f.write("班级:" + clsstr + '\n')
f.writelines(table_arr)
# f.write(str(table_json))
# exit(0)