接到一个有趣的作业,就是分析豆瓣用户关注的小组,通过小组标签给这个用户画像。
任务主要有这几部分:
1.通过爬取的数据,利用Spark Graphx对这些数据构图
2.将这个图进行可视化
3.对用户进行画像分析,找出他的兴趣标签
环境搭建
首先需要搭建Spark,如果需要yarn进行可视化管理的话还需要安装Hadoop,这里我安装的是Hadoop2.7.4+Spark2.2.0
CentOS7安装Hadoop2.7.4
1.安装JDK1.8
将原有的OpenJDK卸载,并下载rpm包进行安装,将JAVA_HOME、PATH等环境变量配置好,检验JAVA是否安装成功。
2.安装Hadoop2.7.4
配置免密登录
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
新建文件夹/usr/hadoop,并在该目录下再新建四个文件夹
/usr/hadoop/hdfs/data
/usr/hadoop/hdfs/name
/usr/hadoop/hdfs/namesecondary
/usr/hadoop/tmp
下载Hadoop2.7.4,并将其放置在/usr/hadoop/目录下,解压
设置环境变量,并使环境变量生效,source /etc/profile
JAVA_HOME=/usr/java/jdk1.8.0_144/
JRE_HOME=/usr/java/jdk1.8.0_144/jre/
SCALA_HOME=/usr/lib/scala
HADOOP_HOME=/usr/hadoop/hadoop-2.7.4
SPARK_HOME=/usr/spark-2.2.0-bin-hadoop2.7
PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin:$SCALA_HOME/bin:$SPARK_HOME/bin:$HADOOP_HOME/bin
CLASSPATH=$JAVA_HOME/lib/tools.jar:$JAVA_HOME/lib/dt.jar
export JAVA_HOME
export JRE_HOME
export PATH
export CLASSPATH
export SCALA_HOME
export HADOOP_HOME
export SPARK_HOME
进入$HADOOP_HOME/etc/hadoop目录,配置 hadoop-env.sh等。涉及的配置文件如下:
hadoop-2.7.4/etc/hadoop/hadoop-env.sh
hadoop-2.7.4/etc/hadoop/yarn-env.sh
hadoop-2.7.4/etc/hadoop/core-site.xml
hadoop-2.7.4/etc/hadoop/hdfs-site.xml
hadoop-2.7.4/etc/hadoop/mapred-site.xml
hadoop-2.7.4/etc/hadoop/yarn-site.xml
(注意:有的文件只有template,需要改名,例如mv mapred-site.xml.template mapred-site.xml)
配置hadoop-env.sh
# The java implementation to use.
#export JAVA_HOME=${JAVA_HOME}
export JAVA_HOME=/usr/java/jdk1.8.0_144
配置yarn-env.sh
#export JAVA_HOME
export JAVA_HOME=/usr/java/jdk1.8.0_144
配置core-site.xml
添加如下配置:
description最好不要用中文
fs.default.name
hdfs://localhost:9000
HDFS的URI,文件系统://namenode标识:端口号
hadoop.tmp.dir
/usr/hadoop/hdfs/tmp
namenode上本地的hadoop临时文件夹
配置hdfs-site.xml
添加如下配置
dfs.name.dir
/usr/hadoop/hdfs/name
namenode上存储hdfs名字空间元数据
dfs.data.dir
/usr/hadoop/hdfs/data
datanode上数据块的物理存储位置
dfs.replication
1
副本个数,配置默认是3,应小于datanode机器数量
配置mapred-site.xml
添加如下配置:
mapreduce.framework.name
yarn
配置yarn-site.xml
添加如下配置:
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.webapp.address
${yarn.resourcemanager.hostname}:8999
(注意:这里将yarn的管理端口改为8999,访问管理页面时也需要用该端口访问)
Hadoop启动
1)格式化namenode
$ bin/hdfs namenode –format
当多次格式化时,遇到个选择,选择no,如果选择yes,将会导致namenode和datanode中/usr/hadoop/hdfs/data/current/VERSION、/usr/hadoop/hdfs/name/current/VERSION中CclusterID 不一致,从而发生sbin/start-all.sh启动时,有的DataNode进程启动不起来(jps查看),遇到这样情况,将name/current下的VERSION中的clusterID复制到data/current下的VERSION中,覆盖掉原来的clusterID,让两个保持一致,然后重启,启动后执行jps,查看进程,参考(https://my.oschina.net/u/189445/blog/509385)
2)启动NameNode 和 DataNode 守护进程
$ sbin/start-dfs.sh
3)启动ResourceManager 和 NodeManager 守护进程
$ sbin/start-yarn.sh
或者直接$sbin/start-all.sh 将上述所有进程启动。
启动验证
1)执行jps命令,有如下进程,说明Hadoop正常启动
# jps
54679 NameNode
54774 DataNode
15741 Jps
55214 NodeManager
55118 ResourceManager
54965 SecondaryNameNode
在浏览器中输入:http://HadoopMaster的IP:8999/ 即可看到YARN的ResourceManager的界面。注意:默认端口是8088,这里我设置了yarn.resourcemanager.webapp.address为:${yarn.resourcemanager.hostname}:8999。
或输入http://HadoopMaster的IP:50070/查看NameNode状态
Spark安装
下载spark-2.2.0-bin-hadoop2.7,并进行解压,配置SPARK_HOME环境变量,运行spark-shell,查看spark是否能够正常启动。
至此,生产环境搭建完毕!
开发环境
折腾了两天,写代码运行调试,最麻烦的环节还属运行调试。调试都是通过maven将程序打成jar包,然后上传到装有Hadoop、Spark的服务器(用一个虚拟机来模拟)上在沙盒里进行运行,执行效率之慢可想而知。有没有什么更为便捷的办法,写完代码,右键直接执行呢,答案是有的。
Win7 64位+IDEA开发Spark应用
下载编译好的Hadoop bin目录文件夹(其中包含winutils.exe、hadoop.dll等文件)
设置环境变量HADOOP_HOME,在Path变量中增加一条,%HADOOP_HOME%/bin
下载Hadoop对应版本编译好的Spark文件
设置环境变量SPARK_HOME,在Path变量中增加一条,%SPARK_HOME%/bin
cmd弹出窗口中测试安装是否成功

(这个版本可能会报Hive错误,可以忽略)
IDEA配置
在运行某个Scala应用时,需要增加一条配置参数,
-Dspark.master=local[2]

如若开发时依然提示找不到Hadoop目录,可以在代码中增加一条属性配置
System.setProperty("hadoop.home.dir", "D:\\hadoop-2.7.4\\")
正题
首先,看一下数据结构,有两个数据集,一个是用户数据机另一个是小组数据集,这些数据集都是从Mongodb中导出而来。
用户(persons.json)
{"_id":{"$oid":"59f3de6b0b6e9a0b9ca7bf4e"},"name":"person1","no":"168812667","group1":"HZhome","group2":"145219","group3":"276209","group4":"hzhouse","group5":"467221"}
...
小组(groups.json)
{"_id":{"$oid":"59f3de5f0b6e9a0b9ca7bf49"},"name":"杭州租房","no":"HZhome","tag1":"杭州","tag2":"租房","tag3":"合租","tag4":"求租","tag5":"杭州租房"}
...
由实例数据可以看出,persons.json每行记录存有用户信息,同时还包括该用户加入的组号(groupx)。而groups.json中记录小组的信息。这两个数据集通过groupsno进行关联(注意:groupno并非是数字字符串)
其次,对数据进行处理
因为每行都是一条json格式的记录,可以利用fastjson对记录进行解析,因此pom.xml文件如下
4.0.0
com.dhl
DoubanGraphx
1.0-SNAPSHOT
1.8
1.8
UTF-8
2.11
2.11.8
2.2.0
org.scala-lang
scala-library
${scala.version}
org.apache.spark
spark-core_${scala.tools.version}
${spark.version}
provided
org.apache.spark
spark-sql_${scala.tools.version}
${spark.version}
org.apache.spark
spark-graphx_${scala.tools.version}
${spark.version}
com.alibaba
fastjson
1.2.32
org.scala-tools
maven-scala-plugin
2.15.2
compile
对persons.json进行解析,构建用户和小组之间的关系,同时graphx需要Long类型字段作为其VertexID,这里我们通过利用导出数据的oid字段进行运算获得(作为Mongodb表中的rowid,该字段应该具备唯一性)
case class Person(poidhex: VertexId, oid: String, name: String, no: String, groupno: String, vertextype: String)
def parsePerson(str: String): List[Person] = {
var result = List[Person]()
val json = JSON.parseObject(str)
val oidjson = json.getJSONObject("_id")
val oid = oidjson.getString("$oid")
val oidhex = new BigInteger(oid, 16).longValue()
val name = json.getString("name")
val no = json.getString("no")
val groups = new ListBuffer[String]
val jsonset = json.keySet().iterator()
while (jsonset.hasNext() == true) {
val strkey = jsonset.next()
if (strkey.length() > 4 && strkey.substring(0, 5).compareTo("group") == 0) {
result .::=(Person(oidhex, oid, name, no, json.getString(strkey),"p"))
}
}
result
}
同样,对groups.json进行处理
case class Group(goidhex: VertexId, oid: String, name: String, groupno: String, tags: List[String], vertextype: String)
def parseGroup(str: String): Group = {
val json = JSON.parseObject(str)
val oidjson = json.getJSONObject("_id")
val oid = oidjson.getString("$oid")
val oidhex = new BigInteger(oid, 16).longValue()
val name = json.getString("name")
val groupno = json.getString("no")
var tags = List[String]()
val jsonset = json.keySet().iterator()
while (jsonset.hasNext() == true) {
val strkey = jsonset.next()
if (strkey.length() > 3 && strkey.substring(0, 3).compareTo("tag") == 0) {
tags .::=(json.getString(strkey))
}
}
Group(oidhex, oid, name, groupno, tags, "g")
}
审查数据时候发现groups.json中存在no相同的记录,为此需要进行去重
System.setProperty("hadoop.home.dir", "D:\\hadoop-2.7.4\\")
val conf = new SparkConf().setAppName("Douban User Relationship")
val sc = new SparkContext(conf)
val sqlContext = new org.apache.spark.sql.SQLContext(sc)
import sqlContext.implicits._
val personsData = sc.textFile("C:\\Users\\daihl\\Desktop\\persons2.json")
val groupsData = sc.textFile("C:\\Users\\daihl\\Desktop\\groups2.json")
val personsRDD: RDD[Person] = personsData.flatMap(parsePerson).cache()
val groupsRDD: RDD[Group] = groupsData.map(parseGroup).cache()
//将RDD转为DataFrame
val personsdf = sqlContext.createDataFrame(personsRDD)
val groupsdf = sqlContext.createDataFrame(groupsRDD)
//根据groupno进行去重
val groupsds = groupsdf.dropDuplicates("groupno")
再通过groupno字段,将两个数据集进行连接,并生成graphx的边
val relation = personsdf.join(groupsds, personsdf("groupno") === groupsds("groupno"))
val edges = EdgeRDD.fromEdges(relation.rdd.map(row => Edge(row.getAs[Long]("poidhex"), row.getAs[Long]("goidhex"), ())))
再将person和group进行合并,作为图中的节点
由于数据集的合并需要相同的schema,所以需要对person和group进行schema转变
val newNames=Seq("oidhex", "oid", "name","no","vertextype")
val personsselect = personsdf.select("poidhex","oid", "name","no","vertextype").dropDuplicates("no").toDF(newNames:_*)
val groupsselect = groupsds.select("goidhex","oid", "name","groupno","vertextype").toDF(newNames:_*)
最终构建图
val vertexnode: RDD[(VertexId, (String, String, String))] = personsselect.union(groupsselect).rdd.map(row => (new BigInteger(row(1).toString, 16).longValue(), (row(2).toString, row(3)toString, row(4)toString)))
val defaultvertexnode = ("null", "null", "null")
val graph =Graph(vertexnode,edges,defaultvertexnode)
graphx图的可视化
最简单的可以利用GraphStream进行可视化(linkuriou.js也值得研究)
//创建原始可视化对象
val graphStream:SingleGraph = new SingleGraph("GraphStream")
// 设置graphStream全局属性. Set up the visual attributes for graph visualization
// 加载顶点到可视化图对象中
for ((id,(name:String, no:String, vertextype:String)) <- graph.vertices.collect()) {
val node = graphStream.addNode(id.toString).asInstanceOf[SingleNode]
node.addAttribute("ui.label",id +"\n"+name)
}
//加载边到可视化图对象中
for (Edge(x, y, defaultvertexnode) <- graph.edges.collect()) {
val edge = graphStream.addEdge(x.toString ++ y.toString,
x.toString, y.toString,
true).
asInstanceOf[AbstractEdge]
}
//显示
graphStream.display()
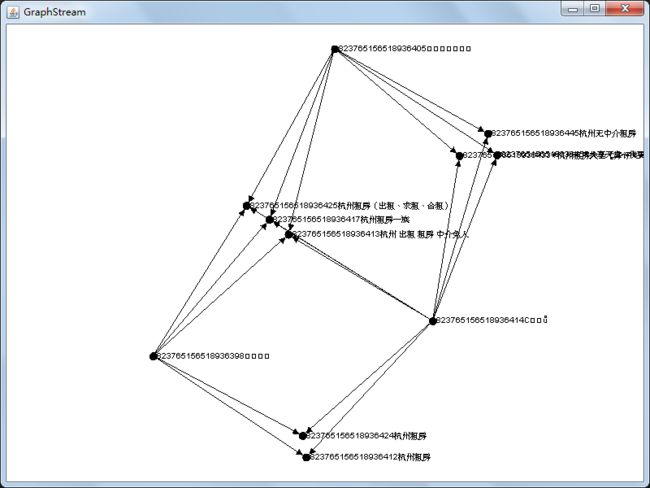
总结
1.对Spark、Spark Graphx有了初步的了解和认识
2.对RDD、DataFrame、DataSet的操作的理解还需要深入
接下来工作
1.尝试利用GraphFrames进行构图
2.尝试利用linkuriou.js进行图的可视化
3.对用户进行画像分析,找出他的兴趣标签