说明:文章内容截选自实验楼教程【R 语言基础入门】~
前言:本课程主要讲解包括 R 语言的基本数据结构 , tidyverse 生态 , 以及一些用R解决实际问题的案例。属于 R 语言小白入门基础课程,难度简单。十分适合想要学习 R 语言的同学进行入门学习。
本教程一共分为【基础数据结构】和【tidyverse生态链两篇】,请有需要的朋友mark下来方便完整学习。如果你的电脑并未安装R编程环境,可以直接移步实验楼【R 语言基础入门】,无需下载,在线实验环境操作更轻松。
R语言简介
四十多年前, R 语言的始祖诞生了 , John Chambers 在贝尔实验室中开发出S语言 ,用于快速地进行数据探索, 统计分析和可视化 。十几年后 , 新西兰奥克兰大学的 Robert Gentleman 和 Ross Ihaka 在 S 语言的基础上发明了 R 语言 。
R 语言流淌着统计学的血液 , 它内置了海量的统计函数 ,使用者可以利用其对数据进行快速交互分析 。 同时作为一门图灵完备的解释性语言 , R 的使用者比 SAS , SPSS 等统计软件的使用者拥有了更大程度的自由。
进入 21 世纪后 ,由于个人计算机的普及和统计学科的发展 , R 社群得以进一步发展 , 一些富有想象力的优秀工具涌现出来 。 如果把 R 语言比作一辆车的话 , Rstudio 的出现使得我们有了信息更加丰富的仪表盘 , dplyr , data.table 等等数据处理的包加强了引擎 , ggplot , shiny 等等可视化的工具使得车的外型更好看。
与大多用于工程实践的编程语言相比 , R 语言更像是一个灵巧的研究工具 ,在处理大量数据 , 性能方面比较薄弱。但是与其他工具交互就能漂亮地解决问题 , 例如与 Spark 配合 (sparkR) 解决数据量较大的情况 , 与 C++(Rcpp) 配合可以解决性能不足的问题。
早在五十多年前 , John Tukey 就在论文 "The Future of Data Analysis"[1] 中发表了这样的看法:统计学不应该只是关于统计推断的数学理论,而应该和现实世界联系起来,成为一种“科学”。为了实现这样的目标,需要有收集和整理数据、分析和解释数据的技术,并且把实践当成检验理论的标准。
R语言及其生态作为连接现实世界中的数据和数学模型的桥梁,正在社群的努力下一步一步地把这些想法具体化。
让我们进入 R 语言的世界!
R语言基本数据结构
下面用 R 的解释器来熟悉一下 R 语言的基本数据结构。
首先让我们先进入 R 环境下
sudo R
1 向量
向量是 R 语言中最基本的数据类型,在 R 中没有单独的标量(例如 1 本质上是 c(1)) 。
赋值
R 中可以用 = 或者 <- 来进行赋值 , <-的快捷键是 alt + - 。
> a <- c(2,5,8)
> a
[1] 2 5 8
筛选
我们可以用下标来筛选,例如
> a[1:2]
[1] 2 5
注意 R 语言的下标是从 1 开始的。
当然我们也可以用逻辑进行筛选,例如
> a[a>4]
[1] 5 8
为了了解这个式子的原理,我们先看看 a>4 是什么
> a>4
[1] FALSE TRUE TRUE
我们可以看到这是一个布尔值构成的向量,我们在用这个布尔值
做下标时只会选出答案为 TRUE 的值。
另外,负数下标表示不选这个这些下标,例如:
> a[-2]
[1] 2 8
合并向量
c() 可以合并向量,例如
> c(a[1] , 3 , a[2:3] , 1)
[1] 2 3 5 8 1
循环补齐
向量有个比较有趣的性质,当两个向量进行操作时,如果长度不等,
长度比较短的一个会复制自己直到自己和长的一样长。
> a <- c(3,4)
> b <- c(1,2,5,6)
> a+b
[1] 4 6 8 10
a 自动变成了 c(3,4,3,4) 然后与b相加 , 得到了下面的结果。
动手试一试
自己创建几个向量 , 自己玩一玩,
可以试一试下面几个函数:
- length
- which.max
- which
遇到不懂的可以用 help 函数,例如我不知道 which 函数
是干什么的,可以用
help("which")
来获取关于 which 函数的帮助文档。
2 矩阵
矩阵,从本质上来说就是多维的向量,我们来看一看
我们如何新建一个矩阵。
> a <- matrix(c(1,2,3,4) , nrow = 2)
> a
[,1] [,2]
[1,] 1 3
[2,] 2 4

可以看到向量元素变为矩阵元素的方式是按列的,从第一列
到第二列,如果我们想按行输入元素,那么需要加入 byrow = TRUE
的参数:
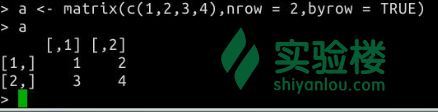
> a <- matrix(c(1,2,3,4) , nrow = 2 , byrow = TRUE)
> a
[,1] [,2]
[1,] 1 2
[2,] 3 4
筛选矩阵
与向量相似,我们可以用下标来筛选矩阵,
例如:
> a[1:2,2]
[1] 2 4
可以看到结果退化成了一个向量。
线性代数
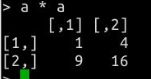
当我们对两个矩阵相乘,我们得到的结果是
对应元素两两相乘的结果,例如
> a * a
[,1] [,2]
[1,] 1 4
[2,] 9 16
而这不是我们想要的矩阵乘法,在 R 中我们在乘法旁边加两个
百分号来做矩阵乘法:
> a%*%a
[,1] [,2]
[1,] 7 10
[2,] 15 22
此外,我们可以用 t() 来求矩阵的转置 , 用 solve() 来求矩阵的逆。
3 数据框
数据框类似矩阵,与矩阵不同的是,数据框可以有不同的数据类型。
一般做数据分析,我们把一个类似 excel 的表格读入 R ,默认的格式
就是数据框 , 可见数据框是一个非常重要的数据结构。
一般来说我们需要分析的数据,每一行代表一个样本,每一列代表一个
变量。
下面我们用 R 内置的数据集 iris 来看一看数据框的使用。
> data("iris")
> head(iris)
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 5.1 3.5 1.4 0.2 setosa
2 4.9 3.0 1.4 0.2 setosa
3 4.7 3.2 1.3 0.2 setosa
4 4.6 3.1 1.5 0.2 setosa
5 5.0 3.6 1.4 0.2 setosa
6 5.4 3.9 1.7 0.4 setosa

我们用 data 函数调入了 iris 这个数据集 , 然后用 head 函数来看一看这个数据
的前几行 , 可以看到有 sepal 的长度,宽度,petal 的长度和宽度,还有一个变量
Species 来描述样本的类别。
我们可以用 summary 函数来对数据集做大致的了解:
> summary(iris)
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
Min. :4.300 Min. :2.000 Min. :1.000 Min. :0.100 setosa :50
1st Qu.:5.100 1st Qu.:2.800 1st Qu.:1.600 1st Qu.:0.300 versicolor:50
Median :5.800 Median :3.000 Median :4.350 Median :1.300 virginica :50
Mean :5.843 Mean :3.057 Mean :3.758 Mean :1.199
3rd Qu.:6.400 3rd Qu.:3.300 3rd Qu.:5.100 3rd Qu.:1.800
Max. :7.900 Max. :4.400 Max. :6.900 Max. :2.500

可以直观地看到每个变量的信息,对于几个数值变量,我们可以看到最小值,中位数等等统计信息。而对于 Species 这个分类变量,我们看到的是计数信息。
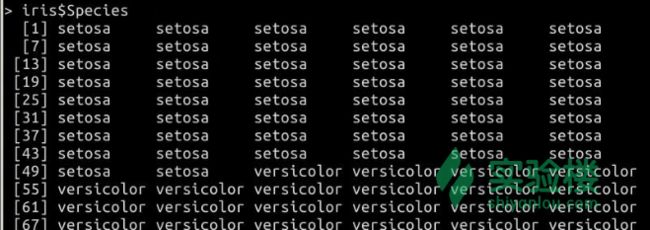
筛选数据框与矩阵相似,都可以通过数字下标来获取子集,不同地是因为数据框有不同的列名,我们也可以通过列名来获取某一特定列,例如
> iris$Species
[1] setosa setosa setosa setosa setosa setosa setosa setosa setosa setosa setosa setosa setosa setosa setosa setosa setosa setosa ...
我们可以用 names() 函数来获取数据框的列名
> names(iris)
[1] "Sepal.Length" "Sepal.Width" "Petal.Length" "Petal.Width" "Species"

并可以通过为其赋值改变列的名字。
4 列表
列表是一种递归式的向量,我们可以用列表来存储不同类型的数据,比如
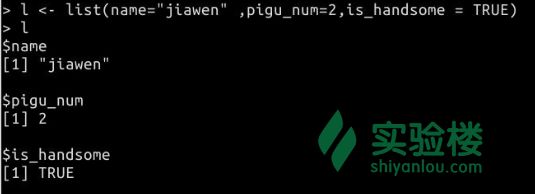
> l <- list(name="jiawen" , pigu_num=2 , is_handsome = TRUE)
> l
$name
[1] "jiawen"
$pigu_num
[1] 2
$is_handsome
[1] TRUE
列表有多种索引方式,可以用如下方式获取。
> l$name
[1] "jiawen"
> l[[2]]
[1] 2
> l[["is_handsome"]]
[1] TRUE

上面的内容涵盖了 R 语言最基本的数据结构,希望对想学习R语言的小伙伴儿有所帮助。
最后:
文章只是截选实验楼教程【R 语言基础入门】第一节主要内容,如果你想查看完整的文档,点击【R 语言基础入门】即可。
传送门:
往期回顾: 【R语言入门:基础数据结构】
下期预告:【R语言入门:tidyverse 生态链】
更多趣味实验可以直接访问实验楼,在线实验环境操作方便,为大家定期更新最佳实验!(●'◡'●)

课程咨询,欢迎添加班主任微信:
