概述
索引就是为特定的mysql字段进行一些算法排序,比如二叉树算法和哈希算法,哈希算法是通过简历特征值,然后根据特征值来快速查找。MyISAM和InnoDB存储引擎的表默认创建索引都是BTREE索引。MyISAM还支持全文本索引,该索引可以用于创建全文搜索。
不使用索引,MySQL必须从第一条记录开始读完整张表找到相关数据,如果表中查询的列有索引,MySQL就能快速到达下一个位置去搜寻到数据文件中间,而不用查询所有数据,大大提高查询效率。
索引的利弊
索引的好处:
- 减少检索过程中需要读取的数据量,提高检索效率,降低数据库IO成本。
- 降低数据库的排序成本。因为索引就是对字段数据进行排序后存储的,如果待排序字段和索引字段一致,在取出数据后就不用再次排序了。
索引的弊端:
- 索引也是一种数据,随着数据量增大,在建立索引的同时必然会占用大量表空间。
- 索引会增加增、删、改操作带来的IO量。
BTree索引
MySQL中使用最频繁的索引类型,基本所有的存储引擎都支持BTree索引,一些引擎在使用BTree索引时也会对存储结构稍作修改,比如MyISAM存储引擎使用的B+Tree。
- MyISAM引擎索引结构的叶子节点的数据域,存放的并不是数据记录,实际存放的是数据记录的地址。检索时先按照B+Tree的检索算法进行检索,找到关键字,取出对应数据域的数据,作为地址,根据地址找到对应的数据记录。索引文件和数据文件分离,这样的索引被称作非聚簇索引。
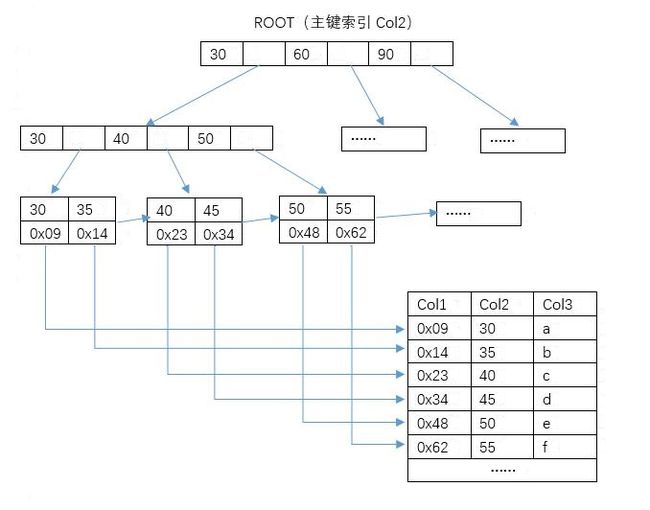
- InnoDB引擎索引结构的叶子节点的数据域,存放的就是实际的数据,或者说InnoDB的数据文件本身就是主键索引文件,这样的索引被称为聚簇索引。
Hash索引
主要是通过Hash算法,将数据库字段数据转换成定长的Hash值,将这条数据的行指针一同存入Hash表的对应位置,当发生Hash碰撞时(即两个不同关键字的Hash值相同),在对应Hash键下以连表形式存储。
在进行查询时,就对待查关键字再次执行相同的Hash算法,得到Hash值,然后到对应的Hash表中取出数据,如果发生Hash碰撞,就需要在取值时进行筛选。
Full-Text索引
MySQL中只有MyISAM支持全文索引,并且只有CHAR、VARCHAR、TEXT类型支持。可以通过多字段组合的全文索引一次性模糊匹配多个字段,用于替代效率低下的LIKE模糊匹配操作。
索引类型
UNIQUE唯一索引
不可以出现相同的值,可以有NULL值。
INDEX普通索引
允许出现相同的值。
PRIMARY KEY主键索引
不允许出现相同的值,且不能为NULL值,一个表只能有一个primary_key索引。
fulltext 全文索引
fulltext索引只适用于MyISAM表,同时只支持char、varchar、text类型;fulltext索引可用于在一篇文章中检索文本信息,针对较大的数据,全文索引很消耗时间和存储空间。
组合索引
为了更多的提高效率可建立组合索引,遵循最左前缀原则。
创建索引
我们可以在创建表的同时建立索引,也可以单独使用CREATE INDEX或者ALTER TABLE来为表添加索引。
CREATE INDEX
普通索引:CREATE INDEX 'index_name' ON table_name('column')
唯一索引:CREATE UNIQUE INDEX 'index_name' ON table_name('column')
不能使用CREATE INDEX语句创建PRIMARY KEY索引** ALTER TABLE**
普通索引:ALTER TABLE 'table_name' ADD INDEX index_name('column')
唯一索引:ALTER TABLE 'table_name' ADD UNIQUE ('column')
主键索引:ALTER TABLE 'table_name' ADD PRIMARY KEY('column')
组合索引:ALTER TABLE 'table_name' ADD INDEX index_name('column1','column2','column3')
删除索引
DROP INDEX index_name ON table_name
ALTER TABLE table_name DROP INDEX index_name
这两句是等价的,作用都是删除表table_name中的索引index_name。
删除主键索引只能使用以下方式:
ALTER TABLE table_name DROP PRIMARY KEY
查看索引
使用以下SQL语句查看索引信息:
show index from table_name;
Table:表名。
Non_unique:如果索引不能包括重复值则为0,可以包括重复值则为1。
Key_name:索引名。
Seq_in_index:索引中的序列号。
Column_name:列名。
Collation:列以什么方式存储在索引中,A表示升序,NULL表示无分类。
Cardinality:索引中唯一值数目的估计值。数值越大,进行联合索引时,MySQL使用该索引的机会越大。
Sub_part:如果列被部分编入索引,则为编入索引的字符数,如果整列被编入索引,则为NULL。
Packed:关键字的压缩方式,NULL为没有压缩。
Null:如果列含有NULL,则为YES,相反则为NO。
index_type:用过的索引方法,BTREE、HASH、RTREE、FULLTEXT
Comment:评注。
适合建立索引的地方
- 为维度高的列创建索引
比如表中有a、b、c、d、e、a、c、d、a、b一共10行数据,那么这张表的维度为5,不重复值出现的个数越多,维度越高。性别这种就不适合建立索引。 - 对join、where、on、order by、group by中出现的列使用索引
- 为较长的字符串使用前缀索引
- 使用组合索引可以减少文件索引大小,速度优于多个单列索引
不适合建立索引的地方
- 表记录太少,就几条数据
- 经常进行插入、删除、修改操作的表
- 数据重复且分布平均的字段,比如性别
- 唯一性太差的字段,即使频繁作为查询条件
使用索引注意
一般来说在where和join中出现的列需要建立索引,但也不完全是,因为MySQL只对<、<=、=、>、>=、between、in和部分情况下的like才会使用索引。
- 不要在列上进行计算
SELECT 'name' FROM 'stu' WHERE 'age'+10=30; //不会使用索引,因为所有索引列参与了计算
SELECT 'sname' FROM 'stu' WHERE LEFT('date',4) <1995; //不会使用索引,因为使用了函数运算
- 注意like语句操作
SELECT * FROM 'stu' WHERE 'name' LIKE '李%' //走索引
SELECT * FROM 'stu' WHERE 'name' LIKE "%李%" // 不走索引
- 字符串与数字比较不使用索引。
CREATE TABLE 'a' ('a' char(10));
EXPLAIN SELECT \* FROM 'a' WHERE 'a'="1" //走索引
EXPLAIN SELECT \* FROM 'a' WHERE 'a'=1 // 不走索引
- 避免使用or
//如果条件中有or,即使其中有条件带索引也不会使用。换言之,就是要求使用的所有字段,都必须建立索引, 尽量避免使用or 关键字 。
SELECT\* FROM 'stu' WHERE name='xxx' or class='xx' or age=18
- 正则表达式不使用索引。
- 使用短索引
对字符串列今夕索引,尽量指定一个前缀长度,如,一个列CHAR(255),前面的10个字符多数值是唯一的,就不要对整个列进行索引,短索引可以提高查询速度并节省存储空间。 - 索引中不要包含NULL
只要列中有NULL值就都不会被包含在索引中,复合索引中只要有一列包含NULL值,此列对复合索引就是无效的;在建立数据库库时就避免让字段默认值为NULL。 - 如果mysql估计使用全表扫描要比使用索引快,则不使用索引。
前缀索引
PS:前缀索引是对索引技巧的一种称呼,并非索引类型。
如果我们的索引列过长,就会产生很大的索引文件,可以使用前缀索引的方式进行索引,前缀索引应该控制在一个合适的点:
SELECT COUNT(DISTINCT(LEFT(\title`,10))) / COUNT(*) FROM Arctic; `
当计算出的值大于0.31黄金值时即可创建.
增加前缀索引:
ALTER TABLE \user` ADD INDEX `uname`(title(10));`
将用户名的索引建立在10,这样可以减小索引文件,提示索引速度。
参考:http://lib.csdn.net/article/mysql/44988
施工ing 2017-5-4