专业名词
| 缩写 | 全称 | 注释 |
|---|---|---|
| SDS | Software Defined Storag | 软件定义存储技术 |
| RAID | Redundant Array of Independent Disk | 磁盘阵列技术 |
| DG | Disk Group | 硬盘组 |
| VD | Virtual Disk | 虚拟磁盘(等效磁盘组) |
| Mirroring | -- | 镜像技术,又称为复制技术(Replication) |
| Striping | --- | 条带(可提供并行的数据吞吐能力) |
| Erasure Code | --- | 纠删码(提供高可用性和高速读写能力) |
| RADOS | Reliable,Autonomic,Distributed Object Store | 可靠的自主的分布式对象存储 |
| OSD | Object Storage Device | 对象存储设备 |
| MDS | Metadata Server | 元数据服务 |
| MTTR | Mean Time To Restoration | 平均恢复时间 |
块存储、文件存储、对象存储
块存储
就好比硬盘一样, 直接挂在到主机, 一般用于主机的直接存储空间和数据库应用(如: mysql)的存储。
块存储(DAS/SAN)通常应用在某些专有的系统中,这类应用要求很高的随机读写性能和高可靠性,上面搭载的通常是Oracle/DB2这种传统数据库,连接通常是以FC光纤(8Gb/16Gb)为主,走光纤协议。如果要求稍低一些,也会出现基于千兆/万兆以太网的连接方式,MySQL这种数据库就可能会使用IP SAN,走iSCSI协议。
通常使用块存储的都是系统而非用户,并发访问不会很多,经常出现一套存储只服务一个应用系统,例如如交易系统,计费系统。典型行业如金融,制造,能源,电信等。
文件系统
文件存储(NAS)相对来说就更能兼顾多个应用和更多用户访问,同时提供方便的数据共享手段。
在PC时代,数据共享也大多是用文件的形式,比如常见的的FTP服务,NFS服务,Samba共享这些都是属于典型的文件存储。几十个用户甚至上百用户的文件存储共享访问都可以用NAS存储加以解决。
在中小企业市场,一两台NAS存储设备就能支撑整个IT部门了。CRM系统,SCM系统,OA系统,邮件系统都可以使用NAS存储统统搞定。甚至在公有云发展的早几年,用户规模没有上来时,云存储的底层硬件也有用几套NAS存储设备就解决的,甚至云主机的镜像也有放在NAS存储上的例子。
文件存储的广泛兼容性和易用性,是这类存储的突出特点。
但是从性能上来看,相对SAN就要低一些。NAS存储基本上是以太网访问模式,普通千兆网,走NFS/CIFS协议。
对象存储
前面说到的块存储和文件存储,基本上都还是在专有的局域网络内部使用,而对象存储的优势场景却是互联网或者公网,主要解决海量数据,海量并发访问的需求。
基于互联网的应用才是对象存储的主要适配(当然这个条件同样适用于云计算,基于互联网的应用最容易迁移到云上),基本所有成熟的公有云都提供了对象存储产品,不管是国内还是国外。
对象存储常见的适配应用如网盘、媒体娱乐,医疗PACS,气象,归档等数据量超大而又相对“冷数据”和非在线处理的应用类型。
这类应用单个数据大,总量也大,适合对象存储海量和易扩展的特点。
网盘类应用也差不多,数据总量很大,另外还有并发访问量也大,支持10万级用户访问这种需求就值得单列一个项目了。归档类应用只是数据量大的冷数据,并发访问的需求倒是不太突出。
另外基于移动端的一些新兴应用也是适合的,智能手机和移动互联网普及的情况下,所谓UGD(用户产生的数据,手机的照片视频)总量和用户数都是很大挑战。毕竟直接使用HTTP get/put就能直接实现数据存取,对移动应用来说还是有一定吸引力的。
对象存储的访问通常是在互联网,走HTTP协议,性能方面,单独看一个连接的是不高的(还要解决掉线断点续传之类的可靠性问题),主要强大的地方是支持的并发数量,聚合起来的性能带宽就非常可观了。
性能容量

- 块存储就像超跑,根本不在意能不能多载几个人,要的就是极限速度和高速下的稳定性和可靠性,各大厂商出新产品都要去纽北赛道刷个单圈最快纪录,千方百计就为提高一两秒。块存储容量也不大,TB这个数量级,支持的应用和适用的环境也比较专业(FC+Oracle),在乎的都是IOPS的性能值。
- 文件存储像集卡,普适各种场合,又能装数据(数百TB),而且兼容性好,只要你是文件,各种货物都能往里塞,在不超过性能载荷的前提下,能拉动常见的各种系统。标准POXIS接口,后车门打开就能装卸。卡车也不挑路,不像块存储非要上赛道才能开,普通的千兆公路就能畅通无阻。速度虽然没有块存储超跑那么块,但跑个80/100码还是稳稳当当。
- 对象存储就像海运货轮,应对的是"真·海量",几十上百PB的数据,以集装箱/container(桶/bucket)为单位码得整整齐齐,里面装满各种对象数据,十万客户发的货(数据),一条船就都处理得过来,按照键值(KeyVaule)记得清清楚楚。海运速度慢是慢点,有时候遇到点网络风暴还不稳定,但支持断点续传,最终还是能安全送达的,对大宗货物尤其是非结构化数据,整体上来看是最快捷便利的。
访问方式
- 块存储通常都是通过光纤网络连接,服务器/小机上配置FC光纤HBA卡,通过光纤交换机连接存储(IP SAN可以通过千兆以太网,以iSCSI客户端连接存储),主机端以逻辑卷(Volume)的方式访问。连接成功后,应用访问存储是按起始地址,偏移量Offset的方法来访问的。
- NAS文件存储通常只要是局域网内,千兆/百兆的以太网环境皆可。网线连上,服务器端通过操作系统内置的NAS客户端,如NFS/CIFS/FTP客户端挂载存储成为一个本地的文件夹后访问,只要符合POXIS标准,应用就可以用标准的open,seek, write/read,close这些方法对其访问操作。
- 对象存储不在乎网络,而且它的访问比较有特色,只能存取删(put/get/delete),不能打开修改存盘。只能取下来改好后上传,去覆盖原对象。
分布式
- 对象存储的定义就把元数据管理和数据存储访问分开在不同的节点上,多个节点应对多并发的访问,这自然就是一个分布式的存储产品。
- 分布式文件系统就很多了,各种开源闭源的产品数得出几十个,在不同的领域各有应用。
- 分布式的块存储产品就比较少,也很难做好。
层次关系
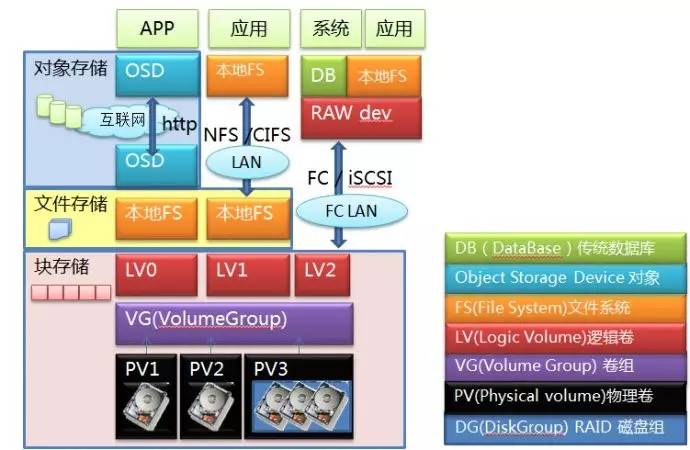
从底层往上看,最底层就是硬盘,多个硬盘可以做成RAID组,无论是单个硬盘还是RAID组,都可以做成PV,多个PV物理卷捏在一起构成VG卷组,这就做成一块大蛋糕了。
接下来,可以从蛋糕上切下很多块LV逻辑卷,这就到了存储用户最熟悉的卷这层。到这一层为止,数据一直都是以Block块的形式存在的,这时候提供出来的服务就是块存储服务。
你可以通过FC协议或者iSCSI协议对卷访问,映射到主机端本地,成为一个裸设备。在主机端可以直接在上面安装数据库,也可以格式化成文件系统后交给应用程序使用,这时候就是一个标准的SAN存储设备的访问模式,网络间传送的是块。
如果不急着访问,也可以在本地做文件系统,之后以NFS/CIFS协议挂载,映射到本地目录,直接以文件形式访问,这就成了NAS访问的模式,在网络间传送的是文件。
如果不走NAS,在本地文件系统上面部署OSD服务端,把整个设备做成一个OSD,这样的节点多来几个,再加上必要的MDS节点,互联网另一端的应用程序再通过HTTP协议直接进行访问,这就变成了对象存储的访问模式。当然对象存储通常不需要专业的存储设备,前面那些LV/VG/PV层也可以统统不要,直接在硬盘上做本地文件系统,之后再做成OSD,这种才是对象存储的标准模式,对象存储的硬件设备通常就用大盘位的服务器。
系统层级上来说,这三种存储是按照块->文件->对象逐级向上的。文件一定是基于块上面去做,不管是远端还是本地。而对象存储的底层或者说后端存储通常是基于一个本地文件系统(XFS/Ext4..)。
相关开源组件
目前比较流行的开源项目有:
- Ceph
- GlusterFS
- Swift
- HDFS
- FastDFS
- Ambry
基本特性对比
| 存储系统 | Ceph | GlusterFS | Swift | HDFS | FastDFS | Ambry |
|---|---|---|---|---|---|---|
| 开发语言 | C++ | C | Python | Java | C | Java |
| 开源协议 | LGPL | GPL3 | Apache | Apache | GPL3 | Apache |
| Start数 | 4667/2501 | 1626/636 | 1759/915 | 7558/4,786 | 3011/915 | 1073/206 |
| 存储方式 | 对象/文件/块 | 文件/块 | 对象 | 文件 | 文件/块 | 对象 |
| 在线扩容 | 支持 | 支持 | 支持 | 支持 | 支持 | 支持 |
| 冗余备份 | 支持 | 支持 | 支持 | 支持 | 支持 | 支持 |
| 单点故障 | 不存在 | 不存在 | 不存在 | 存在 | 不存在 | 不存在 |
| 易用性 | 一般 | 简单 | 一般 | 一般 | 简单 | 简单 |
| 跨集群 | 不支持 | 支持 | 不支持 | 不支持 | 不支持 | 不支持 |
| 适用场景 | 大中小文件 | 大中小文件 | 大中小文件 | 大中文件 | 中小文件 | 大中小文件 |
Ceph
Ceph是个开源的分布式存储,底层是RADOS,这是个标准的对象存储。以RADOS为基础,Ceph 能够提供文件,块和对象三种存储服务,旨在提供一个扩展性强大、性能优越且无单点故障的分布式存储系统。
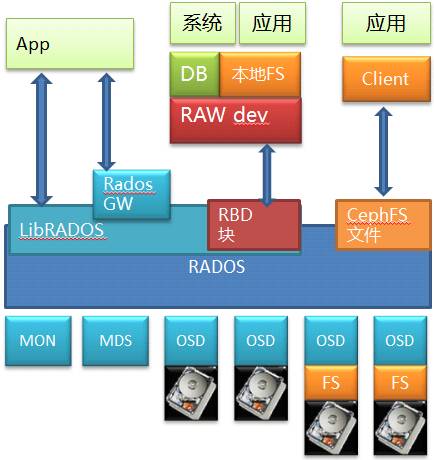
在Ceph存储中,包含了几个重要的核心组件,分别是Ceph OSD、Ceph Monitor和Ceph MDS。一个Ceph的存储集群至少需要一个Ceph Monitor和至少两个Ceph的OSD。运行Ceph文件系统的客户端时,Ceph的元数据服务器(MDS)是必不可少的。
其中通过RBD提供出来的块存储是比较有价值的地方,毕竟因为市面上开源的分布式块存储少见。
当然它也通过CephFS模块和相应的私有Client提供了文件服务,这也是很多人认为Ceph是个文件系统的原因。
另外它自己原生的对象存储可以通过RadosGW存储网关模块向外提供对象存储服务,并且和对象存储的事实标准Amazon S3以及Swift兼容。所以能看出来这其实是个大一统解决方案,啥都齐全。
RADOS也是个标准对象存储,里面也有MDS的元数据管理和OSD的数据存储,而OSD本身是可以基于一个本地文件系统的,比如XFS/EXT4/Brtfs。
数据访问路径,如果看Ceph的文件接口,自底层向上,经过了硬盘(块)->文件->对象->文件的路径;如果看RBD的块存储服务,则经过了硬盘(块)->文件->对象->块,也可能是硬盘(块)->对象->块的路径;再看看对象接口(虽然用的不多),则是经过了硬盘(块)->文件->对象或者硬盘(块)->对象的路径。
GlusterFS
GlusterFS是Scale-Out存储解决方案Gluster的核心,它是一个开源的分布式文件系统,具有强大的横向扩展能力,通过扩展能够支持数PB存储容量和处理数千客户端。GlusterFS借助TCP/IP或InfiniBand RDMA网络将物理分布的存储资源聚集在一起,使用单一全局命名空间来管理数据。GlusterFS基于可堆叠的用户空间设计,可为各种不同的数据负载提供优异的性能。
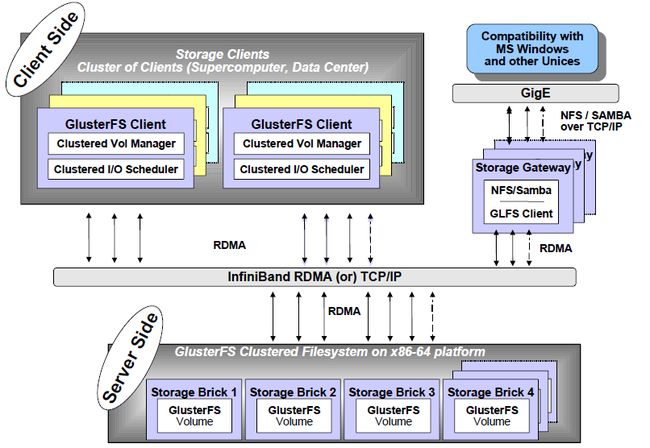
它主要由存储服务器(Brick Server)、客户端以及NFS/Samba存储网关组成。不难发现,GlusterFS架构中没有元数据服务器组件,这是其最大的设计这点,对于提升整个系统的性能、可靠性和稳定性都有着决定性的意义。GlusterFS支持TCP/IP和InfiniBand RDMA高速网络互联,客户端可通过原生Glusterfs协议访问数据,其他没有运行GlusterFS客户端的终端可通过NFS/CIFS标准协议通过存储网关访问数据。
GlusterFS是一个具有高扩展性、高性能、高可用性、可横向扩展的弹性分布式文件系统,在架构设计上非常有特点,比如无元数据服务器设计、堆栈式架构等。然而,存储应用问题是很复杂的,GlusterFS也不可能满足所有的存储需求,设计实现上也一定有考虑不足之处,下面我们作简要分析。
1.无元数据服务器 vs 元数据服务器
无元数据服务器设计的好处是没有单点故障和性能瓶颈问题,可提高系统扩展性、性能、可靠性和稳定性。对于海量小文件应用,这种设计能够有效解决元数据的难点问题。
它的负面影响是,数据一致问题更加复杂,文件目录遍历操作效率低下,缺乏全局监控管理功能。同时也导致客户端承担了更多的职能,比如文件定位、名字空间缓存、逻辑卷视图维护等等,这些都增加了客户端的负载,占用相当的CPU和内存。
2. 用户空间 vs 内核空间
用户空间实现起来相对要简单许多,对开发者技能要求较低,运行相对安全。用户空间效率低,数据需要多次与内核空间交换,另外GlusterFS借助FUSE来实现标准文件系统接口,性能上又有所损耗。
内核空间实现可以获得很高的数据吞吐量,缺点是实现和调试非常困难,程序出错经常会导致系统崩溃,安全性低。纵向扩展上,内核空间要优于用户空间,GlusterFS有横向扩展能力来弥补。
3. 堆栈式 vs 非堆栈式
GlusterFS堆栈式设计思想源自GNU/Hurd微内核操作系统,具有很强的系统扩展能力,系统设计实现复杂性降低很多,基本功能模块的堆栈式组合就可以实现强大的功能。查看GlusterFS卷配置文件我们可以发现,translator功能树通常深达10层以上,一层一层进行调用,效率可见一斑。
非堆栈式设计可看成类似Linux的单一内核设计,系统调用通过中断实现,非常高效。后者的问题是系统核心臃肿,实现和扩展复杂,出现问题调试困难。
4. 原始存储格式 vs 私有存储格式
GlusterFS使用原始格式存储文件或数据分片,可以直接使用各种标准的工具进行访问,数据互操作性好,迁移和数据管理非常方便。然而,数据安全成了问题,因为数据是以平凡的方式保存的,接触数据的人可以直接复制和查看。这对很多应用显然是不能接受的,比如云存储系统,用户特别关心数据安全,这也是影响公有云存储发展的一个重要原因。
私有存储格式可以保证数据的安全性,即使泄露也是不可知的。GlusterFS要实现自己的私有格式,在设计实现和数据管理上相对复杂一些,也会对性能产生一定影响。
5. 大文件 vs 小文件
弹性哈希算法和Stripe数据分布策略,移除了元数据依赖,优化了数据分布,提高数据访问并行性,能够大幅提高大文件存储的性能。
对于小文件,无元数据服务设计解决了元数据的问题。
但GlusterFS并没有在I/O方面作优化,在存储服务器底层文件系统上仍然是大量小文件,本地文件系统元数据访问是一个瓶颈,数据分布和并行性也无法充分发挥作用。
因此,GlusterFS适合存储大文件,小文件性能较差,还存在很大优化空间。
6. 可用性 vs 存储利用率
GlusterFS使用复制技术来提供数据高可用性,复制数量没有限制,自动修复功能基于复制来实现。
可用性与存储利用率是一个矛盾体,可用性高存储利用率就低,反之亦然。
采用复制技术,存储利用率为1/复制数,镜像是50%,三路复制则只有33%。
其实,可以有方法来同时提高可用性和存储利用率,比如RAID5的利用率是(n-1)/n,RAID6是(n-2)/n,而纠删码技术可以提供更高的存储利用率。但是,鱼和熊掌不可得兼,它们都会对性能产生较大影响。
Swift
Swift 是OpenStack开源云计算项目的子项目之一,被称为对象存储,提供了强大的扩展性、冗余和持久性。 构筑在比较便宜的标准硬件存储基础设施之上,无需采用 RAID(磁盘冗余阵列),通过在软件层面引入一致性散列技术和数据冗余性,牺牲一定程度的数据一致性来达到高可用性和可伸缩性,支持多租户模式、容器和对象读写操作,适合解决互联网的应用场景下非结构化数据存储问题。

- 代理服务(Proxy Server):对外提供对象服务 API,会根据环的信息来查找服务地址并转发用户请求至相应的账户、容器或者对象服务;由于采用无状态的 REST 请求协议,可以进行横向扩展来均衡负载。
- 认证服务(Authentication Server):验证访问用户的身份信息,并获得一个对象访问令牌(Token),在一定的时间内会一直有效;验证访问令牌的有效性并缓存下来直至过期时间。
- 缓存服务(Cache Server):缓存的内容包括对象服务令牌,账户和容器的存在信息,但不会缓存对象本身的数据;缓存服务可采用 Memcached 集群,Swift 会使用一致性散列算法来分配缓存地址。
- 账户服务(Account Server):提供账户元数据和统计信息,并维护所含容器列表的服务,每个账户的信息被存储在一个 SQLite 数据库中。
- 容器服务(Container Server):提供容器元数据和统计信息,并维护所含对象列表的服务,每个容器的信息也存储在一个 SQLite 数据库中。
- 对象服务(Object Server):提供对象元数据和内容服务,每个对象的内容会以文件的形式存储在文件系统中,元数据会作为文件属性来存储,建议采用支持扩展属性的 XFS 文件系统。
- 复制服务(Replicator):会检测本地分区副本和远程副本是否一致,具体是通过对比散列文件和高级水印来完成,发现不一致时会采用推式(Push)更新远程副本,例如对象复制服务会使用远程文件拷贝工具 rsync 来同步;另外一个任务是确保被标记删除的对象从文件系统中移除。
- 更新服务(Updater):当对象由于高负载的原因而无法立即更新时,任务将会被序列化到在本地文件系统中进行排队,以便服务恢复后进行异步更新;例如成功创建对象后容器服务器没有及时更新对象列表,这个时候容器的更新操作就会进入排队中,更新服务会在系统恢复正常后扫描队列并进行相应的更新处理。
- 审计服务(Auditor):检查对象,容器和账户的完整性,如果发现比特级的错误,文件将被隔离,并复制其他的副本以覆盖本地损坏的副本;其他类型的错误会被记录到日志中。
- 账户清理服务(Account Reaper):移除被标记为删除的账户,删除其所包含的所有容器和对象。
HDFS
Hadoop分布式文件系统(HDFS)被设计成适合运行在通用硬件(commodity hardware)上的分布式文件系统。它和现有的分布式文件系统有很多共同点。但同时,它和其他的分布式文件系统的区别也是很明显的。
HDFS是一个高度容错性的系统,适合部署在廉价的机器上。HDFS能提供高吞吐量的数据访问,非常适合大规模数据集上的应用。HDFS放宽了一部分POSIX约束,来实现流式读取文件系统数据的目的。
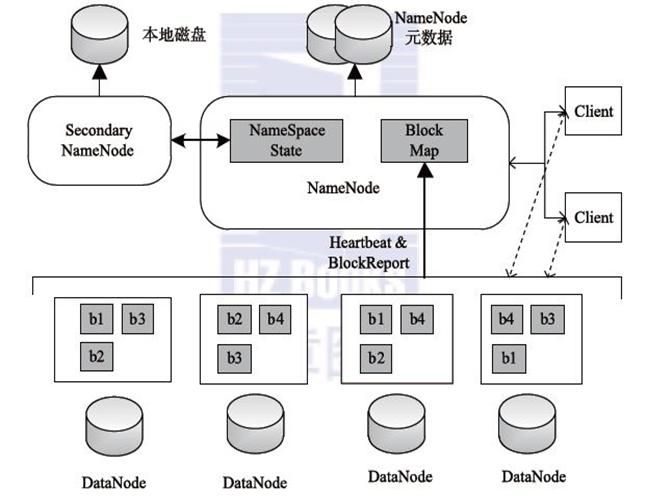
HDFS 采用Master/Slave的架构来存储数据,这种架构主要由四个部分组成,分别为HDFS Client、NameNode、DataNode和Secondary NameNode。
- Client:客户端
- 文件切分。文件上传 HDFS 的时候,Client 将文件切分成一个一个的Block,然后进行存储。
- 与 NameNode 交互,获取文件的位置信息。
- 与 DataNode 交互,读取或者写入数据。
- 提供一些命令来管理 HDFS,比如启动或者关闭HDFS。
- 可以通过一些命令来访问 HDFS。
- NameNode:master,它是一个主管、管理者。
- 管理 HDFS 的名称空间
- 管理数据块(Block)映射信息
- 配置副本策略
- 处理客户端读写请求。
- DataNode:Slave。NameNode 下达命令,DataNode 执行实际的操作。
- 存储实际的数据块。
- 执行数据块的读/写操作。
- Secondary NameNode:并非 NameNode 的热备。当NameNode挂掉的时候,它并不能马上替换 NameNode 并提供服务。
- 辅助 NameNode,分担其工作量。
- 定期合并 fsimage和fsedits,并推送给NameNode。
- 在紧急情况下,可辅助恢复 NameNode。
FastDFS
FastDFS 是一个开源的高性能分布式文件系统(DFS)。 它的主要功能包括:文件存储,文件同步和文件访问,以及高容量和负载平衡。主要解决了海量数据存储问题,特别适合以中小文件(建议范围:4KB < file_size < 500MB)为载体的在线服务。

FastDFS 系统有三个角色:跟踪服务器(Tracker Server)、存储服务器(Storage Server)和客户端(Client)。
- Tracker Server:跟踪服务器,主要做调度工作,起到均衡的作用;负责管理所有的 storage server和 group,每个 storage 在启动后会连接 Tracker,告知自己所属 group 等信息,并保持周期性心跳。
- Storage Server:存储服务器,主要提供容量和备份服务;以 group 为单位,每个 group 内可以有多台 storage server,数据互为备份。
- Client:客户端,上传下载数据的服务器,也就是我们自己的项目所部署在的服务器。
为了支持大容量,存储节点(服务器)采用了分卷(或分组)的组织方式。存储系统由一个或多个卷组成,卷与卷之间的文件是相互独立的,所有卷的文件容量累加就是整个存储系统中的文件容量。一个卷可以由一台或多台存储服务器组成,一个卷下的存储服务器中的文件都是相同的,卷中的多台存储服务器起到了冗余备份和负载均衡的作用。
在卷中增加服务器时,同步已有的文件由系统自动完成,同步完成后,系统自动将新增服务器切换到线上提供服务。当存储空间不足或即将耗尽时,可以动态添加卷。只需要增加一台或多台服务器,并将它们配置为一个新的卷,这样就扩大了存储系统的容量。
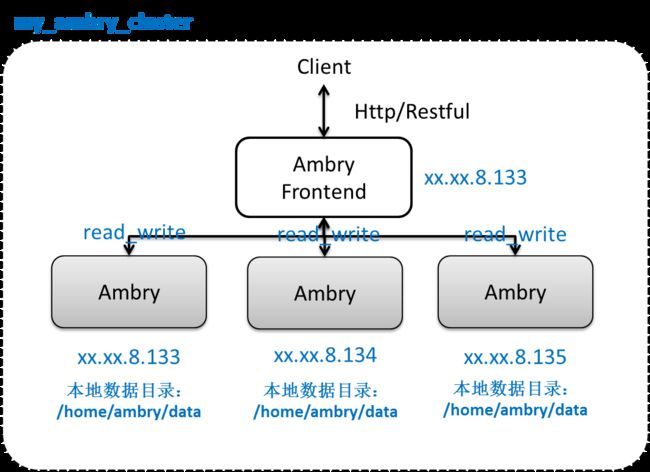
Ambry
Ambry是一个分布式不可变高可用对象存储系统,并且可容易扩展。 Ambry适用于存储从几KB到几GB的多媒体对象,并能保证高吞吐量以及低延迟。他也能实现从客户端到存储层端到端的直接通信,反之亦可。系统可以跨机房多活热部署,并且能提供非常廉价的存储。

Ambry包含负责保存和检索数据的数据节点(data node),前端节点(Frontend node)将请求经过预处理发送到后端数据节点,并且集群管理者(Cluster manager)管理并协调数据节点上的数据。
数据节点之间互相复制数据,并且可以跨机房复制,并需要保证写之后读的一致性。前端提供HTTP API,包括POST,GET和DELETE对象。
同样的,这个路由库可以直接被客户端调用以提升性能。在LinkedIn,这些前端节点扮演着CDN的角色。
Ambry是一个偏向于处理的存储。这意味着当一个对象放入Ambry时,这个对象的ID被返回。这简化了系统设计并促使系统去中心化。客户端可以通过这个ID访问对应对象,这也意味着Ambry内的对象是不可变的。基于Ambry建立一个键值对访问并且支持对象可变的系统非常繁琐。
设计工作原理:
- 高可用以及水平可扩展;
- 低操作与运维开销;
- 低MTTR;
- 跨机房多活;
- 对于大小对象操作高效;
- 节约成本。
简单部署设计图:
其他
很多公司都想自己开发一套对象存储环境,为什么要选择厂家开发的对象存储呢?
公司很想自己研究一套ceph对象存储环境,自己运维,节省成本,
但问题多多?
请问什么条件下才适合自己研发对象存储,什么条件下适合选择购买厂家的成熟SDS方案?
Ceph并不是开源对象存储最好的选择,Ceph是个统一存储,有分布式块,文件,对象三种存储接口,比较全,这是它比较受关注的原因。单独来看底层的对象存储Rados,在开发者社区中口碑并不是很好,坑很多。
如果公司想自研,得有相当层次的开发团队,对大规模并行系统,存储底层,网络,操作系统都有点经验的,并且后续有Devops的思想准备,时间周期也不会太短,还要处理社区版本迭代和你自选分支的冲突或者渐行渐远的问题。
如果是选择厂商的SDS方案,如果是基于Ceph做的(国内不少厂商),其实这个阶段成熟与否还不好说,毕竟这项目社区里参与者很多,时间也不长,所谓成熟也就是有一部分坑能填上吧。前面说的社区版本迭代跟不跟的问题也还是一样存在的。
如果是纯看对象存储,Swift是个更好的选择,这也是OpenStack最早的两个项目之一,比较成熟,开发文档也很多,坑没有这么多,阿里在几年前就投入团队用C语言改写该项目,侧面也说明对该项目架构设计的认同。
HDFS文件系统和OpenStack swift对象存储有何不同?
- HDFS使用了中央系统来维护文件元数据(Namenode,名称节点),而在Swift中,元数据呈分布式,跨集群复制。使用一种中央元数据系统对HDFS来说无异于单一故障点,因而扩展到规模非常大的环境显得更困难。
- Swift在设计时考虑到了多租户架构,而HDFS没有多租户架构这个概念。
- HDFS针对更庞大的文件作了优化(这是处理数据时通常会出现的情况),Swift被设计成了可以存储任何大小的文件。
- 在HDFS中,文件写入一次,而且每次只能有一个文件写入;而在Swift中,文件可以写入多次;在并发操作环境下,以最近一次操作为准。
- HDFS用Java来编写,而Swift用Python来编写。
- 另外,HDFS被设计成了可以存储数量中等的大文件,以支持数据处理,而Swift被设计成了一种比较通用的存储解决方案,能够可靠地存储数量非常多的大小不一的文件。
- HDFS被设计成可以使用Hadoop,跨存储环境里面的对象实现MapReduce处理。而Openstack的使用者公司来说,他们想使用的是Swift里面的处理,而非MapReduce。
参考文档
- 对象存储、文件存储、块存储,从应用角度看有何不同?“狠角色”们是怎么搭配的?
- oss-server
- 腾讯云存储专家深度解读基于Ceph对象存储的混合云机制
- 云存储云计算
- GlusterFS 和 Ceph 比比看
- link
- GlusterFS源码解析 —— GlusterFS 结构体系分析
- 分布式对象存储Ambry
- 用FastDFS一步步搭建文件管理系统
- HDFS文件系统和OpenStack swift对象存储有何不同
- swift对象存储
- HDFS百度百科
- 开源分布式存储系统的对比