学习大数据技术有一段时间了,之前也写过一些零零散散的博客,作为自己学习的一些记录,不过每篇博客都只是涵盖部分技术。这次想写一篇比较完整的博客,记录一个完整的项目从头到尾生产的过程,也是对自己学习的一个总结
废话不多说,直入正题
这次的项目涉及了两条流程
一条是离线处理。爬虫爬到股票数据后,先交给 Map Reduce 清洗一下,生成格式化的数据,然后倒入 hive 进行分析,之后交给 sqoop 导出至 mysql 并用 echarts 可视化展现
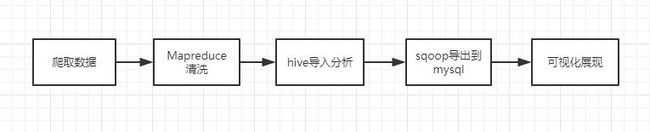
另一条是实时处理。爬虫一直爬取数据,flume 监控爬虫爬下来的文件所在目录,并不断传送给 kafka,spark streaming 会定期从 kafka 那里拿到数据,实时分析并将数据保存到 mysql,最后可视化。

离线流程
网页结构分析
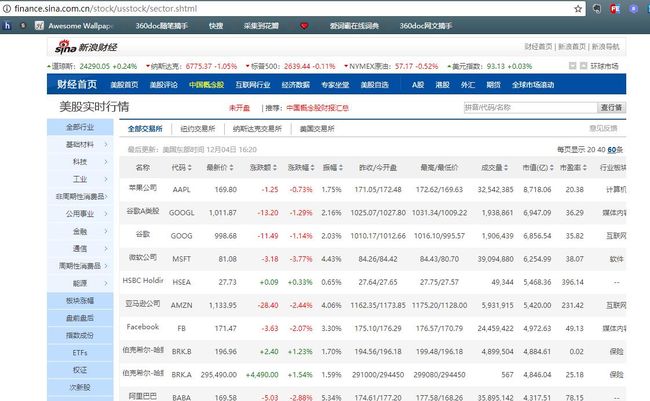
本次爬取 新浪财经美股实时行情,页面长这样
F12,打开开发者工具,选择 network 面板,F5 刷新页面,找到股票的 json 数据的 api 接口。
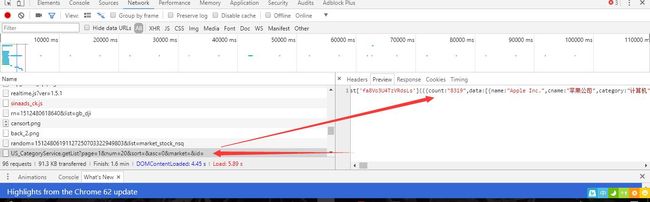
不同的网站寻找 api 接口的方式不太一样,给大家一个小诀窍,一般的接口都是 xhr 或 script 类型,而且它的 url 后面一般都会跟着一个 page 参数,代表着这是第几页
双击 url 之后来到了一个新的页面
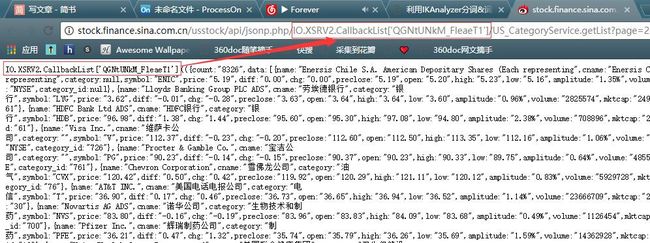
这里可以看到返回的数据不是标准的 json 格式,前面跟着一串
IO.XSRV2.CallbackList['QGNtUNkM_FleaeT1'] ,而且我们也可以在 url 里面看到这一串字符,现在在 url 里他删掉,结果就变成了下面这样子。

现在数据的格式基本标准了,只不过最前面多了两对小括号,我们在会在爬虫程序里面去掉它。根据上面拿到的的 url ,开始编写我们的爬虫。
爬取数据
爬虫程序我写了两种方案,一种是用 python 语言写的;还有一种是使用 java 语言实现的 webmagic 框架写的,由于篇幅问题,python 的方案就不在这篇博客里面采用了,以后可能会单开一篇博客介绍 python 版的股票爬虫。
WebMagic 是一个国人写的简单灵活的Java爬虫框架。
要使用 webmagic ,首先下载它的依赖包 webmagic-0.7.3-all.tar.gz
在 eclipse 里面新建一个 Java Project,在工程根目录下新建一个文件夹,将依赖包解压至文件夹中,全选之后添加到 Build Path
然后就可以写爬虫代码了
private Site site = Site.me().setDomain("stock.finance.sina.com.cn").setSleepTime(2000)
.setUserAgent("Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:39.0) Gecko/20100101 Firefox/39.0");
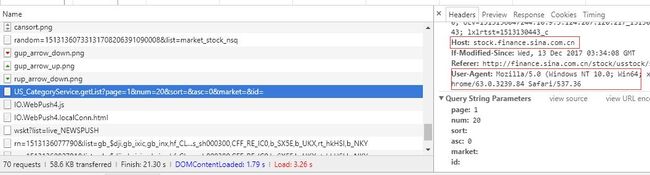
首先构建要请求的 Site ,这里注意一点,代码最上面的 setDomain("stock.finance.sina.com.cn") 里面的这个 "stock.finance.sina.com.cn" 就是下图中的 Host,同时也是爬虫程序下载的网页所存放的目录
然后编写一个方法,过滤掉前面提到的 json 数据外边的两对小括号
public String regexJson(String source) {
//用于去掉包裹 json 数据的两对小括号
String regex = "\\{.*\\}";
String result;
Pattern pattern = Pattern.compile(regex);
Matcher matcher = pattern.matcher(source);
if (matcher.find()) {
result = matcher.group(0);
} else {
result = null;
}
return result;
}
在 process 方法中编写爬虫逻辑
@Override
public void process(Page page) {
// TODO Auto-generated method stub
page.putField("sixty", regexJson(page.getJson().toString()));
}
主方法
public static void main(String[] args) {
String url_init = "http://stock.finance.sina.com.cn/usstock/api/jsonp.php/" +
"/US_CategoryService.getList?num=60&sort=&asc=0&page=1";
String url_pattern = "http://stock.finance.sina.com.cn/usstock/api/jsonp.php/" +
"/US_CategoryService.getList?num=60&sort=&asc=0&page=";
String output = "/data/edu1/tmp/";
QueueScheduler scheduler = new QueueScheduler();
Spider spider = Spider.create(new GetStock())
.addUrl(url_init)
.setScheduler(scheduler)
.addPipeline(new JsonFilePipeline(output))
.addPipeline(new ConsolePipeline());
for (int i = 1; i < 140; i++) {
Request request = new Request();
request.setUrl(url_pattern + i);
scheduler.push(request, spider);
}
spider.thread(50).run();
}
爬虫运行结束后,会在 /data/edu1/tmp/stock.finance.sina.com.cn 下面生成许多 json 文件,查看某一个文件,可以看到里面的 json 字符串。
接下来我们把这些文件上传到 hdfs 上面,然后开始编写 MapReduce 程序清洗脏数据
hadoop fs -put /data/edu1/tmp/stock.finance.sina.com.cn/* /mystock/in
MapReduce清洗
数据清洗从名字上也看的出就是把“脏”的数据“洗掉”,指发现并纠正数据文件中可识别的错误的最后一道程序,包括检查数据一致性,处理无效值和缺失值等。
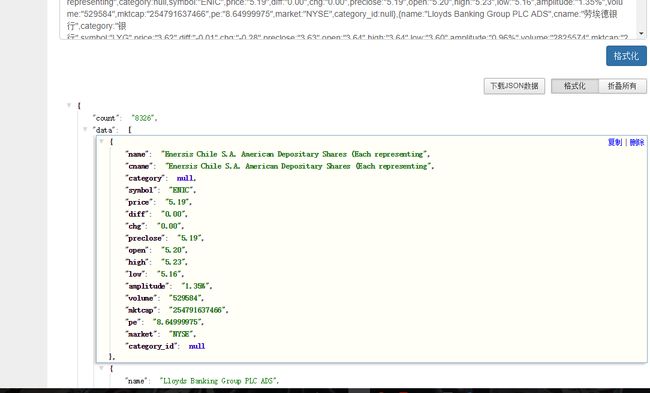
这里我们把 json 格式的数据最终洗成可以直接导入 hive 的以 '\t' 为分隔符文本格式。而且 json 数据中有的字段会有缺失的现象出现,所以我们还要填补空值,保持数据的一致性
这里我们用到了阿里的 fastjson 库来解析 json
map 代码:
@Override
protected void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
String initJsonString = value.toString();
JSONObject initJson = JSONObject.parseObject(initJsonString);
if (!initJsonString.contains("data")) {
return;
}
JSONObject myjson = initJson.getJSONObject("sixty");
JSONArray data = myjson.getJSONArray("data");
for (int i = 0; i < data.size(); i++) {
JSONObject stock = data.getJSONObject(i);
String name = stock.getString("name").trim().equals("")?"null":stock.getString("name").trim().replaceAll("\r|\n|\t", "");
String cname = stock.getString("cname").trim().equals("")?"null":stock.getString("cname").trim().replaceAll("\r|\n|\t", "");
String category = stock.getString("category");
if (category == null || category.equals("")) {
category = "null";
} else {
category = category.toString().trim().replaceAll("\r|\n|\t", "");
}
System.out.println(category);
String symbol = stock.getString("symbol").trim().equals("")?"null":stock.getString("symbol").trim().replaceAll("\r|\n|\t", "");
String price = stock.getString("price").trim().equals("")?"null":stock.getString("price").trim().replaceAll("\r|\n|\t", "");
String diff = stock.getString("diff").trim().equals("")?"null":stock.getString("diff").trim().replaceAll("\r|\n|\t", "");
String chg = stock.getString("chg").trim().equals("")?"null":stock.getString("chg").trim().replaceAll("\r|\n|\t", "");
String preclose = stock.getString("preclose").equals("")?"null":stock.getString("preclose").trim().replaceAll("\r|\n|\t", "");
String open = stock.getString("open").trim().equals("")?"null":stock.getString("open").trim().replaceAll("\r|\n|\t", "");
String high = stock.getString("high").trim().equals("")?"null":stock.getString("high").trim().replaceAll("\r|\n|\t", "");
String low = stock.getString("low").trim().equals("")?"null":stock.getString("low").trim().replaceAll("\r|\n|\t", "");
String amplitude = stock.getString("amplitude").trim().equals("")?"null":stock.getString("amplitude").trim().replaceAll("\r|\n|\t", "");
String volume = stock.getString("volume").trim().equals("")?"null":stock.getString("volume").trim().replaceAll("\r|\n|\t", "");
String mktcap = stock.getString("mktcap").trim().equals("")?"null":stock.getString("mktcap").trim().replaceAll("\r|\n|\t", "");
String pe = stock.getString("pe");
if (pe == null || pe.equals("")) {
pe = "null";
} else {
pe = pe.trim().replaceAll("\r|\n|\t", "");
}
String market = stock.getString("market").trim().equals("")?"null":stock.getString("market").trim().replaceAll("\r|\n|\t", "");
String category_id = stock.getString("category_id");
if (category_id == null || category_id.equals("")) {
category_id = "null";
} else {
category_id = category_id.toString().trim().replaceAll("\r|\n|\t", "");
}
StringBuffer sb = new StringBuffer();
sb.append(name); sb.append("\t");
sb.append(cname); sb.append("\t");
sb.append(category); sb.append("\t");
sb.append(symbol); sb.append("\t");
sb.append(price); sb.append("\t");
sb.append(diff); sb.append("\t");
sb.append(chg); sb.append("\t");
sb.append(preclose); sb.append("\t");
sb.append(open); sb.append("\t");
sb.append(high); sb.append("\t");
sb.append(low); sb.append("\t");
sb.append(amplitude); sb.append("\t");
sb.append(volume); sb.append("\t");
sb.append(mktcap); sb.append("\t");
sb.append(pe); sb.append("\t");
sb.append(market); sb.append("\t");
sb.append(category_id);
String result = sb.toString();
context.write(new Text(result), new Text());
}
}
这里解释一下每个字段的含义
| 字段 | 含义 |
|---|---|
| name | # 英文名称 |
| cname | # 中文名称 |
| category | # 行业板块 |
| symbol | # 代码 |
| price | # 最新价 |
| diff | # 涨跌额 |
| chg | # 涨跌幅 |
| preclose | # 昨收 |
| open | # 今开盘 |
| high | # 最高价 |
| low | # 最低价 |
| amplitude | # 振幅 |
| volume | # 成交量 |
| mktcap | # 市值(亿) |
| pe | # 市盈率 |
| market | # 上市地 |
| category_id | # 板块ID |
main 方法:
public static void main(String[] args) throws IOException,ClassNotFoundException, InterruptedException {
Job job = Job.getInstance();
job.setJobName("QingXiStock");
job.setJarByClass(QingXiStock.class);
job.setMapperClass(doMapper.class);
//job.setReducerClass(doReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
Path in = new Path("hdfs://localhost:9000//mystock/in");
Path out = new Path("hdfs://localhost:9000//mystock/out");
FileInputFormat.addInputPath(job, in);
FileOutputFormat.setOutputPath(job, out);
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
清洗结束后,会在 hdfs 的 /mystock/out 目录下生成新文件

导入 Hive ,进行分析
数据已经没问题了,接下来可以直接导入 hive 来进行分析
首先进入 hive ,新建一个数据库
create database sina;
然后新建一个外部表 stock ,之所以新建一个外部表,是因为外部表不会移动数据,它只是存放元数据,当外部表删除后,只是删除了元数据,而数据不会被删掉,所以相对更安全
create external table if not exists stock (
> name string,
> cname string,
> category string,
> symbol string,
> price float,
> diff float,
> chg float,
> preclose float,
> open float,
> high float,
> low float,
> amplitude string,
> volume bigint,
> mktcap bigint,
> pe float,
> market string,
> category_id int
> ) row format delimited
> fields terminated by '\t'
> lines terminated by '\n'
> stored as textfile
> location '/mystock/out/';
接下来查看一下前十条数据
select * form stock limit 10;

查看一下各个板块包含的股票数量
select category,count(category) as num from stock group by category order by num desc;
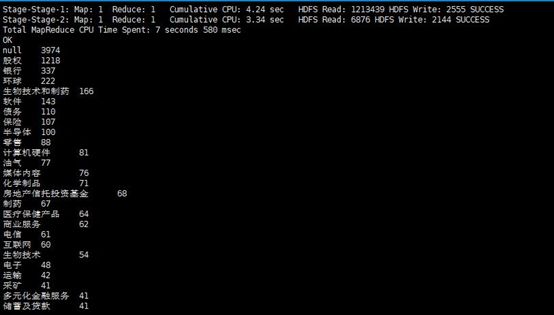
查看市值最高的十支股票
select cname,mktcap from stock order by mktcap desc limit 10;

查看各个上市地区的股票数量
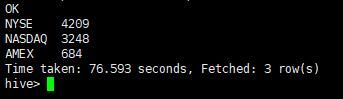
select market,count(market) as num from stock group by market order by num desc;
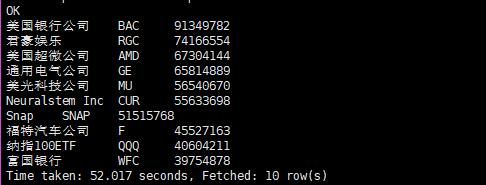
查看成交量最高的十支股票
select cname,symbol,volume from stock order by volume desc limit 10;
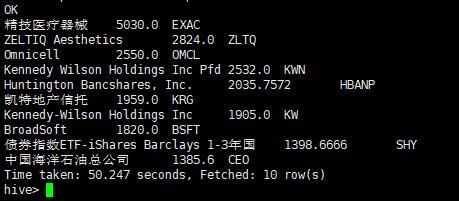
查看市盈率最高的十支股票
select cname,pe,symbol from stock order by pe desc limit 10;
涨跌幅最高的十支股票
select cname,symbol,chg from stock order by chg desc limit 10;
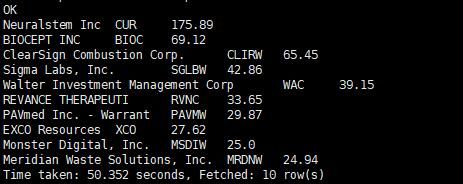
查看数据的总量一共有多少
select count(*) from stock;
Sqoop 导出至 MySQL
hive 分析完之后,接下来使用 sqoop 将 hive 中的数据导出到 mysql ,因为我们的数据量只有 8000 多条,所以这里直接导出整个表。
首先在 mysql 里面新建一个数据库 sina
create database if not exists sina default charset utf8 collate utf8_general_ci;
进入数据库后新建一个表
create table if not exists stock (
-> name varchar(100),
-> cname varchar(100),
-> category varchar(100),
-> symbol varchar(50),
-> price float,
-> diff float,
-> chg float,
-> preclose float,
-> open float,
-> high float,
-> low float,
-> amplitude varchar(50),
-> volume bigint,
-> mktcap bigint,
-> pe float,
-> market varchar(10),
-> category_id int(10)
-> ) default charset=utf8;
然后执行 sqoop 导出命令
sqoop export \
> --connect jdbc:mysql://localhost:3306/sina?characterEncoding=UTF-8 \
> --username root \
> --password strongs \
> --table stock \
> --export-dir /user/hive/warehouse/sina.db/stock/part-r-00000 \
> --input-fields-terminated-by '\t'
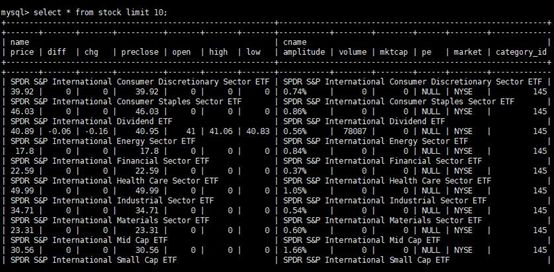
导出过程执行完毕后,查看一下 mysql 中的数据
select * from stock limit 10;
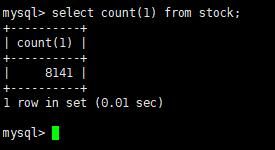
查看一下数据总量,可以看到和 hive 中的一样,是 8141 条
数据可视化
可视化过程我之前写过一篇博客 利用ECharts可视化mysql数据库中的数据 和这次的道理差不多,只不过这次的 echarts 用到了 ajax 动态加载,而且所有的请求都归到了一个 servlet ,所以这里只贴一下 echarts 和 servlet 的代码
工程目录
ServletBase.java 是一个 servlet 抽象类,我们的 servlet 需要继承它,然后实现里面的方法
package my.servlet;
import javax.servlet.ServletException;
import javax.servlet.annotation.WebServlet;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import java.io.IOException;
import java.lang.reflect.Method;
/**
* Created by teaGod on 2017/12/7.
*/
@WebServlet(name = "ServletBase")
public abstract class ServletBase extends HttpServlet {
private static final long serialVersionUID = 1L;
@Override
public void service(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
String methodName = request.getParameter("cmd");
if(methodName==null || methodName.trim().equals("")){
methodName="execute";
}
try{
Method method = this.getClass()
.getMethod(methodName,
HttpServletRequest.class,
HttpServletResponse.class);
method.invoke(this,request,response);
}catch(Exception e){
throw new RuntimeException(e);
}
}
public abstract void execute(HttpServletRequest request, HttpServletResponse response)
throws Exception;
}
ServletStock.java 根据各个 jsp 传过来的 opt 参数来确定执行哪些逻辑
package my.servlet;
import my.entity.*;
import my.manager.StockManager;
import net.sf.json.JSONArray;
import org.apache.log4j.Logger;
import javax.servlet.ServletException;
import javax.servlet.annotation.WebServlet;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import java.io.IOException;
import java.io.PrintWriter;
import java.util.List;
/**
* Created by teaGod on 2017/12/7.
*/
@WebServlet(name = "ServletStock", value = "/ServletStock")
public class ServletStock extends ServletBase {
private static final long serialVersionUID = 1L;
public static Logger logger = Logger.getLogger(ServletStock.class);
@Override
public void execute(HttpServletRequest request, HttpServletResponse response) throws Exception {
response.setContentType("text/html;charset=utf-8");
String opt = request.getParameter("opt");
StockManager stockManager = new StockManager();
if (opt.equals("marketCount")) {
List list;
list = stockManager.getMarketCountList();
writeJson(list, response);
} else if (opt.equals("categoryCount")) {
List list;
list = stockManager.getCategoryCountList();
writeJson(list, response);
} else if (opt.equals("cnameMktnum")) {
List list;
list = stockManager.getCnameMktnumList();
writeJson(list, response);
} else if (opt.equals("marketSumchg")) {
List list;
list = stockManager.getMarketSumchgList();
writeJson(list, response);
} else if (opt.equals("cnameVolume")) {
List list;
list = stockManager.getCnameVolumeList();
writeJson(list, response);
} else if (opt.equals("cnameHigh")) {
List list;
list = stockManager.getCnameHighList();
writeJson(list, response);
}
}
private void writeJson(List list, HttpServletResponse response) throws IOException {
JSONArray jsonArray = JSONArray.fromObject(list);
//System.err.println(jsonArray);
PrintWriter out = response.getWriter();
out.print(jsonArray);
out.flush();
out.close();
}
}
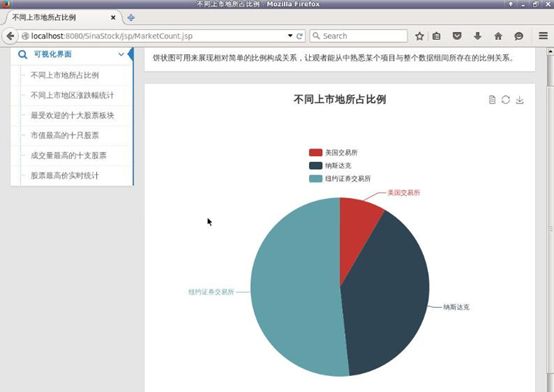
不同的上市地所占比例,可以看到选择纽约证券交易所上市的股票已经占了一半以上
echarts 代码
<%@ page language="java" import="java.util.*" pageEncoding="UTF-8"%>
不同上市地所占比例
<%@include file="../basic/cssjs.jsp"%>
<%@include file="../basic/top.jsp"%>
<%@include file="../basic/left.jsp"%>
饼状图可用来展现相对简单的比例构成关系,让观者能从中熟悉某个项目与整个数据组间所存在的比例关系。
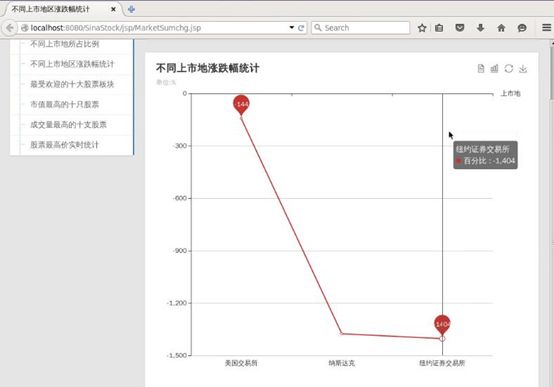
不同上市地的涨跌幅统计,可以看到纽约证券交易所的涨跌幅总量最大,但这也和在这里上市的股票最多有关系,不过每个上市地都是跌幅大于涨幅的,所以你可以看到股票并不是很容易就可以玩的溜的
echarts 代码:
<%@ page language="java" import="java.util.*" pageEncoding="UTF-8"%>
不同上市地区涨跌幅统计
<%@include file="../basic/cssjs.jsp"%>
<%@include file="../basic/top.jsp"%>
<%@include file="../basic/left.jsp"%>
折线图适合用来展现某个项目的发展趋势,或展现并比较多个项目的发展趋势。
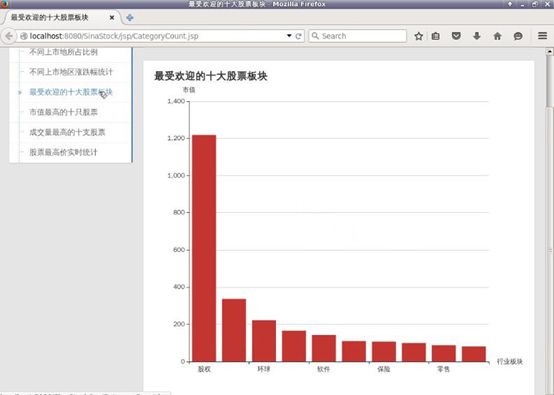
最受欢迎的十大股票板块,可以看到股权是排在第一的,排在第二的是银行,软件排在第五
echarts 代码:
<%@ page language="java" import="java.util.*" pageEncoding="UTF-8"%>
最受欢迎的十大股票板块
<%@include file="../basic/cssjs.jsp"%>
<%@include file="../basic/top.jsp"%>
<%@include file="../basic/left.jsp"%>
柱状图以坐标轴上的长方形元素作为变量,以此来达到展现并比较数据情况的目的
市值最高的十支股票,可以看到苹果公司以超过 8000 亿的数量领先,有个股票的名字 “HSBC Holdings, plc. Perpetual Sub Cap Secs” 比较长,把别的股票名字都盖住了,阿里巴巴排在第十

成交量最高的十支股票
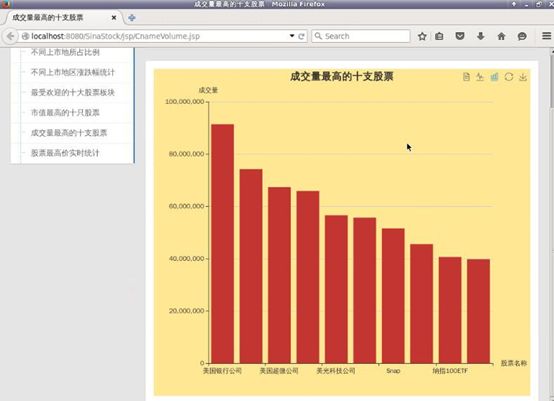
到这里离线分析的流程就告一段落了,hadoop 适用于对时延要求不高的离线处理,而当我们需要实时处理的时候,就需要用到 Storm 或者 Spark Streaming 了
实时流程
再放一遍前面的实时处理流程图
这次我们要实时爬取各只股票的最高价,然后以 echarts 动态图的形式展现出来,所以这次需要修改一下爬虫
爬取最高价
首先我们定义一个实体类,来封装各只股票的名称与最高价
CnameHigh.java:
package my.webmagic;
public class CnameHigh {
private String cname;
private Float high;
public CnameHigh() {
super();
}
public CnameHigh(String cname, Float high) {
super();
this.cname = cname;
this.high = high;
}
public String getCname() {
return cname;
}
public void setCname(String cname) {
this.cname = cname;
}
public Float getHigh() {
return high;
}
public void setHigh(Float high) {
this.high = high;
}
@Override
public String toString() {
return cname + ":" + high;
}
}
这里我们设置了爬虫每爬一次就睡 1500 毫秒,比之前的爬虫少睡了 500 毫秒,因为我设置的 echarts 动态图是每 2000 毫秒刷新一次,所以至少要保证数据更新的速度要比显示的速度快。
private Site site = Site.me().setDomain("stock.finance.sina.com.cn").setSleepTime(1500)
.setUserAgent("Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:39.0) Gecko/20100101 Firefox/39.0");
在 process 方法中修改爬虫的逻辑,这次我们不需要全部的 json 数据,只需要其中的 cname(股票名称) 和 high(最高价) 字段,所以需要在爬虫代码中解析 json 数据,将这两个字段取出来
public void process(Page page) {
// page.putField("sixty", regexJson(page.getJson().toString()));
String stockJson = regexJson(page.getJson().toString());
if (!stockJson.contains("data") || !stockJson.contains("high")) {
return;
}
JSONObject myjson = JSON.parseObject(stockJson);
JSONArray dataArray = myjson.getJSONArray("data");
ArrayList highList = new ArrayList<>();
String cname;
Float high;
for (int i = 0; i < dataArray.size(); i++) {
JSONObject jsonObject = dataArray.getJSONObject(i);
cname = jsonObject.getString("cname");
high = jsonObject.getFloatValue("high");
CnameHigh cnameHigh = new CnameHigh(cname, high);
highList.add(cnameHigh);
}
page.putField("high", highList);
}
在 main 方法里我们修改了 url 里的 num 参数,由原来的每次爬 60 条数据改成每次爬 20 条数据,这是为了让爬虫跑的时间长一点,以使动态图可以显示的久一点。此外,我们还修改了输出目录,然后我们将原来的 JsonFilePipeline 改成了 FilePipeline ,这样可以减少 Spark Streaming 中的实时处理代码量
public static void main(String[] args) {
String url_init = "http://stock.finance.sina.com.cn/usstock/api/jsonp.php/" +
"/US_CategoryService.getList?num=20&sort=&asc=0&page=1";
String url_pattern = "http://stock.finance.sina.com.cn/usstock/api/jsonp.php/" +
"/US_CategoryService.getList?num=20&sort=&asc=0&page=";
String output = "/data/edu6/tmp/";
QueueScheduler scheduler = new QueueScheduler();
Spider spider = Spider.create(new GetStockHigh())
.addUrl(url_init)
.setScheduler(scheduler)
.addPipeline(new FilePipeline(output))
.addPipeline(new ConsolePipeline());
for (int i = 1; i < 418; i++) {
Request request = new Request();
request.setUrl(url_pattern + i);
scheduler.push(request, spider);
}
spider.thread(1).run();
}
先让爬虫跑一下看看得到的数据是什么样子
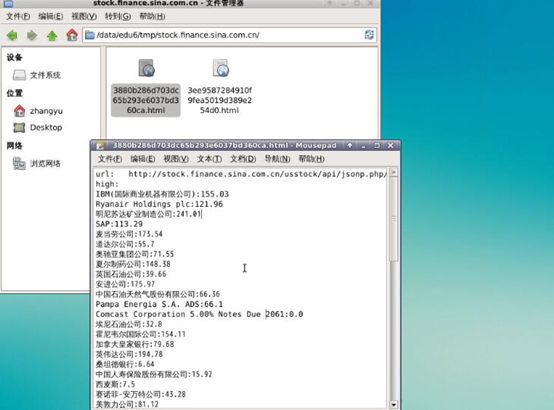
可以看到我们爬到的文件最前面两行不是我们需要的,所以我们需要在 Spark Streaming 中过滤掉,然后将剩下的股票名称和最高价存到数据库里面,同时用 echarts 实时展示
为了过滤掉前两行,我们发现了一个规律,如果以 ":" 将每行文本分割,第一行被分成三段,第二行被分成一段,而其余我们需要的数据都被分成了两段。以这个规律,在 Spark Streaming 中编写代码来过滤出我们需要的数据。
编写 Spark Streaming
在 Spark Streaming 中我们要做的工作就是不断地读取 kafka 传送过来的数据,过滤后存到 mysql 里面
首先定义 kafka 的配置
val sparkConf = new SparkConf().setAppName("StockMonitor").setMaster("local[2]")
val ssc = new StreamingContext(sparkConf, Seconds(5))
ssc.checkpoint("checkpoint")
val topics = Set("flumesendkafka")
val brokers = "localhost:9092"
val zkQuorum = "localhost:2181"
val kafkaParams = Map[String, String](
"metadata.broker.list" -> brokers,
"serializer.class" -> "kafka.serializer.StringEncoder")
然后定义数据库的连接配置
val db_host = "localhost"
val db_name = "sina"
val db_user = "root"
val db_passwd = "strongs"
val db_connection_str = "jdbc:mysql://" + db_host + ":3306/" + db_name + "?user=" + db_user + "&password=" + db_passwd
然后定义 Dstream
val dstream = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder](ssc, kafkaParams, topics).map(_._2)
最后对 Dstream 执行计算,这里注意一点,我们是对每个 RDD 分区建立一个数据库连接。因为如果对每一行建立一个连接的话,频繁的新建和关闭数据库连接对系统开销很大,影响实时处理的速度;而对直接每个 RDD 建立一个连接的话又会报不能序列化的异常。
dstream.foreachRDD {rdd =>
rdd.foreachPartition {partitionOfRdd =>
var conn: Connection = DriverManager.getConnection(db_connection_str)
val lines = partitionOfRdd.filter(_.split(':').length == 2) //过滤出我们需要的数据
try {
lines.foreach ( line => {
var strs = line.mkString.split(':')
if (strs.length == 2) {
var ps: PreparedStatement = null
val sql = "insert into cnamehigh (cname, high) values (?, ?)"
val cname = strs(0)
val high = strs(1).toFloat
println("cname:" + cname + ",high:" + high)
ps = conn.prepareStatement(sql)
ps.setString(1, cname)
ps.setFloat(2, high)
ps.execute()
if (ps != null) {
ps.close()
}
}
})
} catch {
case e: Exception => println("MySQL Exception")// todo: handle error
} finally {
if (conn != null) {
conn.close()
}
}
}
}
完整代码 StockMonitor.scala:
package my.streaming
import org.apache.spark.SparkConf
import org.apache.spark.streaming.StreamingContext
import org.apache.spark.streaming.Seconds
import org.apache.spark.streaming.kafka.KafkaUtils
import kafka.serializer.StringDecoder
import java.sql.Connection
import java.sql.PreparedStatement
import java.sql.DriverManager
object StockMonitor {
def main(args: Array[String]) {
val sparkConf = new SparkConf().setAppName("StockMonitor").setMaster("local[2]")
val ssc = new StreamingContext(sparkConf, Seconds(5))
ssc.checkpoint("checkpoint")
val topics = Set("flumesendkafka")
val brokers = "localhost:9092"
val zkQuorum = "localhost:2181"
val kafkaParams = Map[String, String](
"metadata.broker.list" -> brokers,
"serializer.class" -> "kafka.serializer.StringEncoder")
val dstream = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder](ssc, kafkaParams, topics).map(_._2)
val db_host = "localhost"
val db_name = "sina"
val db_user = "root"
val db_passwd = "strongs"
val db_connection_str = "jdbc:mysql://" + db_host + ":3306/" + db_name + "?user=" + db_user + "&password=" + db_passwd
dstream.foreachRDD {rdd =>
rdd.foreachPartition {partitionOfRdd =>
var conn: Connection = DriverManager.getConnection(db_connection_str)
val lines = partitionOfRdd.filter(_.split(':').length == 2) //过滤出我们需要的数据
try {
lines.foreach ( line => {
var strs = line.mkString.split(':')
if (strs.length == 2) {
var ps: PreparedStatement = null
val sql = "insert into cnamehigh (cname, high) values (?, ?)"
val cname = strs(0)
val high = strs(1).toFloat
println("cname:" + cname + ",high:" + high)
ps = conn.prepareStatement(sql)
ps.setString(1, cname)
ps.setFloat(2, high)
ps.execute()
if (ps != null) {
ps.close()
}
}
})
} catch {
case e: Exception => println("MySQL Exception")// todo: handle error
} finally {
if (conn != null) {
conn.close()
}
}
}
}
ssc.start()
ssc.awaitTermination()
ssc.stop()
}
}
使用 Kafka 对 SparkStreaming 进行测试
开启 kafka 之前要先开启 zookeeper
/apps/zookeeper/bin/zkServer.sh start
开启 kafka
/apps/kafka/bin/kafka-server-start.sh /apps/kafka/config/server.properties
然后另开一个终端在 kafka 中新建一个 topic
/apps/kafka/bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --topic flumesendkafka --partitions 1
查看刚才新建的 topic
/apps/kafka/bin/kafka-topics.sh --list --zookeeper localhost:2181
然后打开 mysql 切换到 sina 数据库,新建一个表,这里我们新增了一个自增的 id 字段,因为在做可视化的时候,要一直显示最新的数据,这时我们就可以按照 id 来降序查找,以保证每次查到的数据都不同
create table cnamehigh (id int not null auto_increment, cname varchar(100), high float, primary key(id));
查看一下数据库,可以看到里面还没有数据
select * from cnamehigh;

我们先用控制台来当 kafka 的 producer,模拟输入一些数据,看看能不能正确的插入到 mysql 中
运行 spark streaming
另开一个终端,新建一个 console producer
/apps/kafka/bin/kafka-console-producer.sh --broker-list localhost:9092 --topic flumesendkafka
然后输入一些模拟数据

在 spark streaming 的控制台中看到,只输出了第一行数据
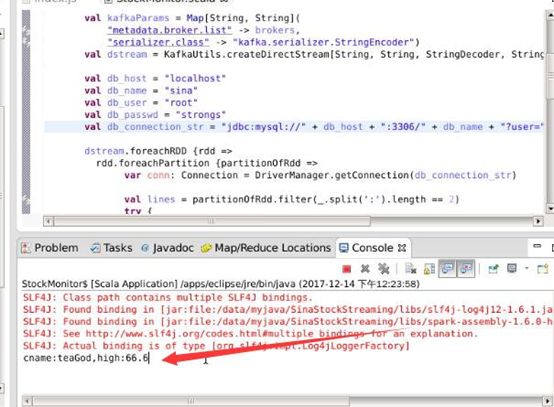
而且在 mysql 中也可以看到新增进来的数据
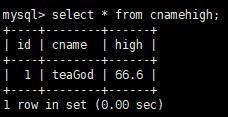
好了,因为刚才的表插入了新的数据,所以我们把刚才的表删掉,重新创建一个相同的表备用
create table cnamehigh1 like cnamehigh;
drop table cnamehigh;
alter table cnamehigh1 rename cnamehigh;
接下来我们配置 flume
Flume 配置
在 /data/edu1 目录下新建一个 flume 配置文件
vim /data/edu1/spooldir_mem_kafka.conf
将下列配置填写进去
agent1.sources = src
agent1.channels = ch
agent1.sinks = des
agent1.sources.src.type = spooldir
agent1.sources.src.restart = true
agent1.sources.src.spoolDir = /data/edu6/tmp/stock.finance.sina.com.cn
agent1.channels.ch.type = memory
agent1.sinks.des.type = org.apache.flume.sink.kafka.KafkaSink
agent1.sinks.des.brokerList = localhost:9092
agent1.sinks.des.topic = flumesendkafka
agent1.sinks.des.batchSize = 1
agent1.sinks.des.requiredAcks = 1
agent1.sources.src.channels = ch
agent1.sinks.des.channel = ch
这里我们设置 flume 监控的目录为新爬虫的输出目录
然后设置 batchSize = 1 是为了让数据库更新的及时一点,以便我们可以观测到动态图的变化
最后一点工作就是 echarts 动态图的完成
echarts 动态图
可视化的部分已经花了很大的篇幅讲过了,这里就不啰嗦了,直接贴上 echarts 动态图的代码
<%@ page language="java" import="java.util.*" pageEncoding="UTF-8"%>
股票最高价实时统计
<%@include file="../basic/cssjs.jsp" %>
<%@include file="../basic/top.jsp" %>
不过有一点需要注意, dao 层的 sql 我是这么写的,以保证每次查到的数据都不同
select cname,high from cnamehigh order by id desc limit 1;
但是因为数据库更新的比较快,所以我们每查一次可能 id 已经涨了几十上百了,所以严格来说这也不太算实时,不过道理还是一样的
所有准备工作都做完后,最后就是让工程跑起来,终于到了激动人心的时刻!
工程执行的顺序依次为:开启可视化=>开启kafka=>开启spark streaming=>开启flume=>开启爬虫程序
开启可视化
可以看到动态图还没有变化
开启 kafka
/apps/kafka/bin/kafka-server-start.sh /apps/kafka/config/server.properties
开启 spark streaming

开启 flume
flume-ng agent -c /data/edu1/ -f /data/edu1/spooldir_mem_kafka.conf -n agent1 -Dflume.root.logger=DEBUG,console
最后开启爬虫
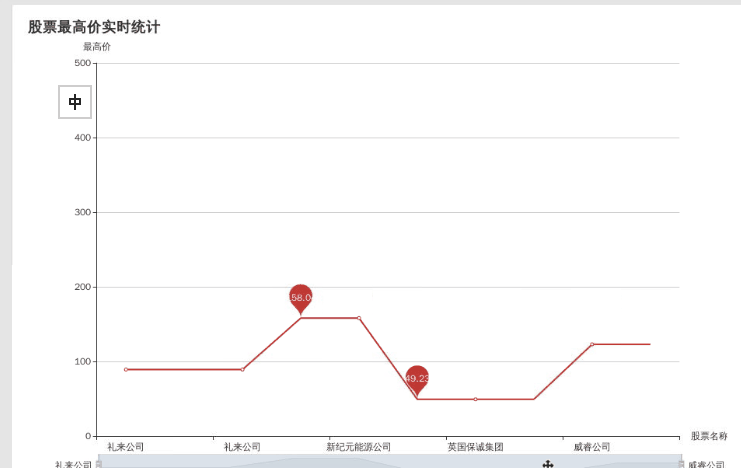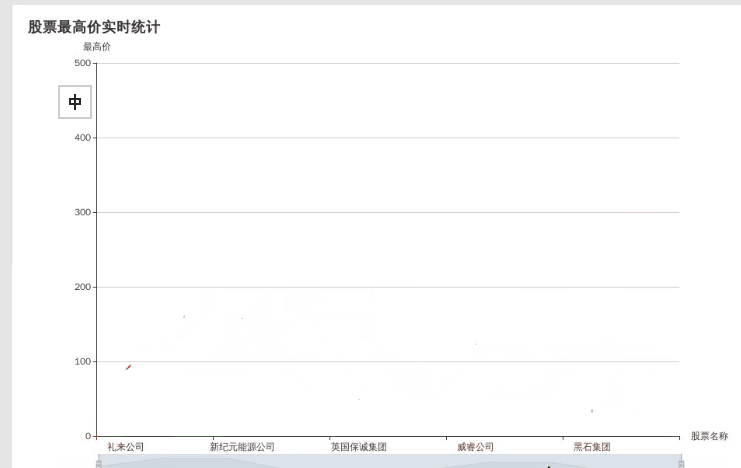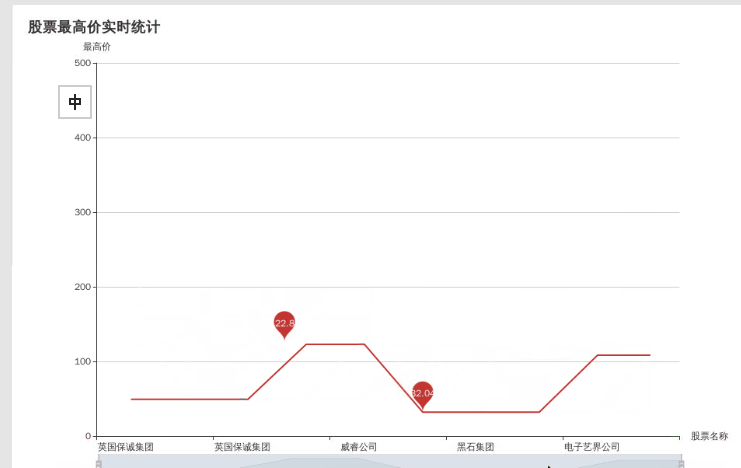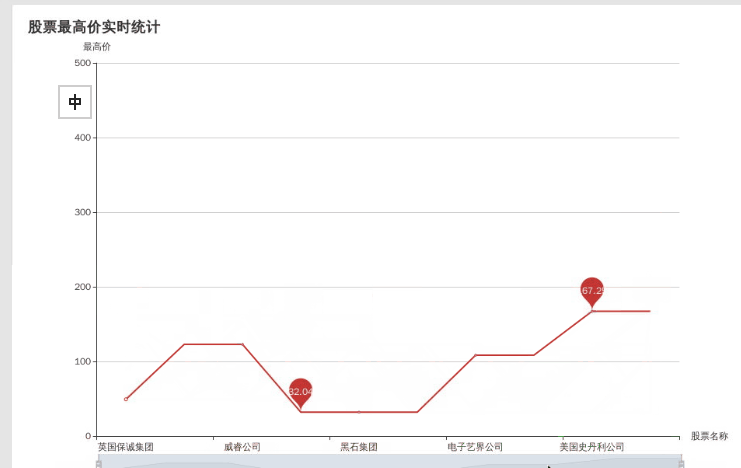
实时的动态图
总结
经历了四个月的大数据学习,我学到了很多有趣的东西,其中既有对已有知识的巩固,也领略到了大数据这个新兴行业的魅力。感谢各位老师的悉心指导,还有各位小伙伴的互相交流,希望大家一直保持着旺盛的好奇心与求知欲,永远年轻。