本文已经投稿其他地方,本处拒绝转载!
1. 背景
提到混音很多想到的是玩音乐的人用一些专业的设备做一些很炫但是看不懂的事情...

在移动直播场景中, 混音可以是用于主播一边播放音乐, 一边直播, 也就是一般说的背景音乐功能. 或者是直播连麦中, 将辅播的声音和主播的声音混合. 还有在画中画等功能中将,视频的声音和主播的声音混合等等. 总之将多路声音叠加, 对丰富移动直播的内容起到了很重要的作用, 是现在移动直播APP必备的基础功能之一了。
最初的时候, 一般是用其他APP将音乐播放出来, 再通过麦克风采集, 利用声音在空气中自然的叠加完成混合。这种做法有如下缺点:
- 主播需要在其他音乐播放器APP中操作,比较繁琐;
- 音乐的声音也会因为采集而产生损耗;
- 而且主播带上耳机的话,自然混音就无效了;
其实所谓混音就是将不同来源的声音混合在一起, 变成一路音频信号。移动直播显然无法使用专门的高大上设备来做,那只能在APP内来完成。下面我们来看看如何实现移动平台上的混音功能。
2. 方案选择
在没有混音的场景下, 我们之前的音频通路是,音频采集模块将采集到的PCM音频数据送入到音频编码器编码为AAC进行直播。当加入混音后,我们面对的是多路音频输入,经过混合后得到一路音频送入音频编码器进行编码。
要在iOS上实现以上功能, 有好几种方法可以实现:
- 系统API来做混音, iOS系统提供了多个层次的音频处理接口:AudioUnit、AudioToolBox、AVFoundation等,从最底层开始就提供了混音模块, 理论上都能能够实现声音混合功能。
- 使用第三方或自己实现的音频混合算法。
使用系统API的方案网上的例子比较多, 参考Apple的示例代码和文档就好, 这里不详细写。我们主要通过自己实现的混音模块来看看混音具体需要做些啥,并且这种方案对输入和输出数据的要求最低,和其他模块的集成方式最灵活,可以直接以PCM数据的形式输入和输出。按照相同的实现思路,也可以跨平台使用。
3. 音频数据
音频数据有两种存在形式, 一种是压缩后的, 比如MP3、AAC等格式的录音或音乐文件; 另一种是未压缩的PCM数据,也就是我们用数字的形式对自然界中声音的表示。声音的波形非常复杂,为了描述和记录声音,通常我们采用脉冲代码调制编码(PCM编码). PCM编码通过抽样,量化等步骤将连续的模拟信号转换为离散的数字信号。
简单来讲PCM数据的格式信息包括如下三个:
- 采样率;
- 每个sample的数据类型;
- 通道数和通道排列方式;
采样率说的是每秒钟采样多少个sample, 也就是一秒钟的声音有多少数据来描述。采样率越高表明对声音的还原度越高,声音质量就越好,但是相应的数据量也越大。常见的采样率是16KHz、44.1KHz、48KHz等。
每个sample的数据类型, 比如是否有符号,整数还是浮点数, 几个bit表示等. 通常我们在iOS上处理的都是16bit的无符号整数的音频。
通道数主要为了产生立体声, 现实中人能够听声辩位主要是靠声音到达左右耳的时间差, 在听音乐时候,如果能够还原出这种差异,就能有身临其境的感觉.所以就有了双通道甚至多通道的音频数据. 通道的排列方式主要是说多通道的数据是说每个sample交织着放在一起, 还是不同通道的数据分块存放。
混音算法的处理对象就是这些PCM音频数据。
4. 混音算法
其实混音的核心部分本来是音频的叠加, 这一块的算法和论文都蛮多的, 要实现好确实比较难。但是在直播场景中, 需要混合的声音路数比较少, 每一路的音量电平都不太高, 可以直接使用每路音频的PCM数据求和就可以了。
为了调整每一路声音在最后声音中的音量大小,给每个sample乘以一个系数,再做求和.这样最后采样的混音算法其实就是加权求和。
5. 混音模块
在选定了混音算法之后, 就需要将该算法封装为模块, 集成到直播SDK中. 当考虑到实际的场景的时候, 就面临了新的问题, 比如声音格式输入格式的多样性. 当两路声音的格式不同时, 我们就需要对数据进行转换,得到相同的格式才能最终进行PCM的加权求和. 比如采样率不同, 那每一秒的数据的长度都不一样, 无法进行处理. 当两路声音产生的频率不同时,也就是每次送入的sample数量不同,我们就需要增加buffer来对输入的数据进行缓存,比如有的33毫秒一次, 有的50毫秒一次, 那一次就只能处理33毫秒的数据,50毫秒的数据就需要缓存一段, 等下次再处理。
当将以上提到的差异进行了处理就得到了如下的模块结构。
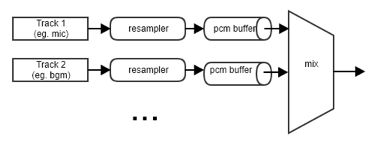
每一路音频, 送入混音模块时,先按照输出的的格式要求进行格式转化(resample), 然后送入pcm buffer中, 输出模块, 对每个buffer的长度进行监控, 当满足输出条件时, 从每个buffer中取出相同长度的数据, 进行混合,最后输出。
其中resampler 可以直接使用ffmpeg中的swresample库来完成, PCM buffer可以使用循环buffer或者fifo来实现.
6. 遇到的坑
- 输出的声音有周期性咔咔声
在实现混音模块中,当输入和输出的每次处理的sample数不同时,需要考虑多种组合的情况,当时漏掉了, 输入比输出慢的情况, 导致出现buffer常满,数据溢出丢弃,最后观众端声音总是会周期性的咔咔声. 主要要考虑以下三种情况:
- 输入和输出数据的采样率相同,此时送入数据和回调数据的频率基本一致;
- 输入数据采样率低于输出数据,此时输入数据频率比回调数据的频率低;
- 输入数据采样率高于输出数据,此时输入数据频率比回调数据的频率高;
要能够兼容前两种情形,我们只需在每次输入数据时检查buffer中是否有足够输出的数据量,而要兼容第三种情形,则需要内部按照buffer中剩余数据的长度,定时向外刷回调数据。当前的逻辑是两者同时存在,每次数据输入时检查,并且当buffer中剩余数据足够一次输出时也定时回调。
2.只要在xcode中打断点,命中后继续执行就会出现崩溃
我们模块中的PCMbuffer是采用的 TPCircularBuffer, 原本我们对buffer进行写入操作时, 只是通过 TPCircularBufferHead接口判断还有多少空间, 而没有检查返回的header指针的有效性。
当命中断点的时候,偶现字节数正确,而header失效的情况,导致在调试阶段出现崩溃,而实际运行过程中没问题的情况。该问题只影响了debug,但是具体原因未知。
7. 展望
这里采用的混音算法是简单粗暴的加权求和, 当路数增加或者其中某一路的音量很高时, 直接求和就会出现超过每个sample所能表示的范围而溢出,造成爆音,如果要应付更丰富的场景,可能需要更强的算法来支持。
也欢迎大家使用我们的直播、短视频SDK。金山云SDK仓库地址:
https://github.com/ksvc
金山云SDK相关的QQ交流群:
- 视频云技术交流群:574179720
- 视频云iOS技术交流:621137661