XXC是一个高读高写的系统,它在双十一期间将肩负起8w的手淘峰值查询流量,以及7w的均值物流详情回传流量,而换算到db层面预期则有20w的读,27w的写流量,在db资源上则是8主8备的混合部署方式。双十一前XXC系统面临着比较大的数据库压力,如何提升db性能、降低对db的依赖、提升系统的稳定性则是需要解决的问题。
从优化的结果上看,同等压测场景下数据库读写rt整体降低约60%,从2ms+下降到0.8ms,DB磁盘ioUtil从90%下降的50%,数据库存储能力扩充一倍,系统层DB单机读写从3w提升到5w+,争取双十一期间不扩容。整个过程中采用的优化手段有流量均衡、数据表动静数据分离、字段清理、冷热数据精细划分、索引的重用和清理、多种缓存(redis、mdb)的使用、mysql最新技术的引入(memcache plugin)。
由于业务数据保密的原因,本文不仔细讨论优化的细节,只讨论DB性能优化和保障过程中的一些理论知识、优化手段的选择原因、系统保障上的思考积累。
主要内容:
- 索引:三星索引、索引的代价、读/写性能的取舍、主键的作用
- SQL:代价模型、抵抗IO、性能漏斗
- 设计:范式 or 反范式、读写分离、缓存和缓存的代价、业务模型和存储模型、银弹、技术的视野
1、索引
1.1 三星索引
在解决查询性能时首先想到是添加索引,在XXC应用设计之初就考虑到了,根据索引的设计原则、业务的查询特性、压测的结果多次进行尝试。
-
ONE-STAR INDEX
查询条件都包含在索引列中,所需要扫描的索引区间尽可能的少。
-
TWO-STAR INDEX
在one star index的基础上,利用索引能消除排序, 排序是很消耗内存和CPU的,尤其是数据量大的情况下。
-
THREE-STAR INDEX
在two star index的基础上,能够利用索引覆盖,来消除回表,即能够在索引中完成所有的操作。
经过多次的修改、尝试和压测之后,设置的了多条二级索引,在平时的业务请求中运行良好,最终设置索引主要有如下:
idx_mailno(mail_no)
idx_ordercode_key(order_code)
idx_status_arrive_key(uid,biz_status,arrive_time)
idx_status_modify_key(uid,biz_status,gmt_modify)
idx_status_close_tao_arrive_key(uid,biz_status,trade_close,is_tao,arrive_time)
uk_pkg_unique_key(pkg_unique)
但是过多的索引带来的负面影响在618大促中展现出来。
1.2 越多越好? —— 索引的代价
一般在讲索引的优化时,都在考虑如何根据业务情况设计出性能最优的索引,但是很少有考虑到索引带来的代价,特别索引设置很多的情况下。
索引带来的性能的负面影响主要有两条:
-
过多的索引会占据大量存储空间和BP空间,导致BP中有效数据占比变小,查询时可能需要更多的IO操作。
下图是DBA给出的XXC应用DB的BP中索引空间容量占比,其中第一列是索引名,第二列是记录数,第 三列是有效记录使用内存,第四列是实际使用内存。
从统计中可以看到在BP中,primary的占比大概只有47%,primary占比过低带来的后果是在查询的时候缓存命中率偏低,需要付出更多的IO来完成。
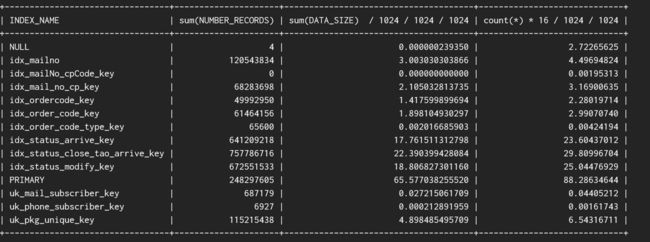 image
image 每次进行更新操作时,需要同步进行索引更新,特别是频繁被更新的字段作为索引时,也会频繁更新索引,过多的索引会带来附加的写入压力。
而具体的表现是db单机写入能力不足,ioUtil时常飙升到90%,写入rt最高达到100ms,严重影响业务保障。
因此对于索引的必要性,在添加索引和后期业务发生变更的时候都需要再三的进行review,一个索引在添加的时候是否是必要的、添加完之后带来的后果和影响是否是如期望中的、业务发生变更后的索引是否还是必要的,这些都需要时时审视。
1.3 主键的作用
期间DBA提到了XXX应用DB一次小但是卓有成效的优化,从优化的思路和结果来看很有价值,也让我重新思考在对DB性能进行优化时,其他需要关注的指标和可能着手的途径。
XXX应用DB联合主键优化的方案简单介绍如下:
XXX应用为用户提供最多120件关注的商品,最后添加/修改的商品需要被优先展示,同一个店铺的商品需要聚合展示,在业务高峰期其db的IO吞吐非常高,BP命中率比较低,导致其查询性能不足。
先看看表设计如下(非关键字段隐除),db采用分库分表,其主键xxx_id由TDDL SEQUENCE生成的全局连续唯一值。
CREATE TABLE `xxx_table_0000` (
`xxx_id` bigint(20) NOT NULL COMMENT '主键id',
`user_id` bigint(20) NOT NULL COMMENT '用户id',
`status` tinyint(4) NOT NULL COMMENT '状态1:正常-1:删除',
`type` tinyint(4) NOT NULL DEFAULT '0' COMMENT '',
`sub_type` bigint(20) NOT NULL DEFAULT '0' COMMENT '类型',
`gmt_create` datetime NOT NULL COMMENT '属性创建时间',
`gmt_modified` datetime NOT NULL COMMENT '属性修改时间',
`xxx` varchar(2048) DEFAULT NULL COMMENT '',
`xxx1` int(11) NOT NULL DEFAULT '0' COMMENT '',
`xxx2` int(11) DEFAULT NULL COMMENT '',
`xxx3` bigint(20) DEFAULT NULL COMMENT '保留字段',
`xxx4` varchar(500) DEFAULT NULL COMMENT '保留字段',
`xxx5` bigint(20) NOT NULL DEFAULT '0',
`xxx6` tinyint(4) NOT NULL DEFAULT '0' COMMENT '',
`xxx7` bigint(20) NOT NULL DEFAULT '0' COMMENT '',
`xxx8` bigint(20) NOT NULL COMMENT '',
`xxx9` bigint(20) NOT NULL COMMENT '',
PRIMARY KEY (`xxx_id`),
KEY `ind_member_cart_userid ` (`user_id`, `status`, `type`, `sub_type`),
KEY `ind_member_cart_gmtm`(`gmt_modified `)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='xxx'
其主要查询SQL如下:
SELECT `xxx_table`.`xxx_id`,
`xxx_table`.`USER_ID`,
`xxx_table`.`STATUS`,
`xxx_table`.`TYPE`,
`xxx_table`.`SUB_TYPE`,
`xxx_table`.`GMT_CREATE`,
`xxx_table`.`GMT_MODIFIED`,
`xxx_table`.`XXX`,
`xxx_table`.`XXX1`,
`xxx_table`.`XXX2`,
`xxx_table`.`XXX3`,
`xxx_table`.`XXX4`,
`xxx_table`.`XXX5`,
`xxx_table`.`XXX6`,
`xxx_table`.`XXX7`,
`xxx_table`.`XXX8`,
`xxx_table`.`XXX9`
FROM xxx_tabile `xxx_tabile`
WHERE `xxx_table`.`USER_ID`= ’123xxxx789‘
AND(`xxx_table`.`STATUS`= 1
AND `xxx_table`.`TYPE` IN(0,5,10)) LIMIT 0, 120
其执行计划如下:
id: 1
select_type: SIMPLE
table: xxx_table_0289
type: range
possible_keys: ind_member_cart_userid
key: ind_member_cart_userid
key_len: 10
ref: NULL
rows: 3
Extra: Using index condition
真实执行耗时如下:
query_time:0.000996
lock_time:0.000202
rows_sent:75
rows_examined:75
rows_affected:0
innodb_pages_read:329
innodb_pages_io_read:0
从执行耗时来看一次查询过程中需要扫描329个page,返回了75条记录,这329个page都需要从磁盘读取到内存,但是只有很少的有效数据被使用,而page中的其他数据对本次访问无效,有效的IO比例很低,而且过多的无效数据,还会污染BP,导致BP的命中率下跌。
为什么一次查询需要扫描这么多page,能否提升page的有效使用率?先来分析下InnoDB中page和索引的结构以及查询的具体过程。
在InnoDB引擎内部,InnoDB表其类型是索引组织表(IOT),数据文件就是主键的聚簇索引,每一行数据都存放在聚簇索引的叶子节点上。二级索引是非聚簇索引,叶子节点上保存了相应记录的主键信息。当请求通过二级索引扫描记录时,若其内容未在二级索引上覆盖,则需要通过主键回查主键索引得到相应的内容。一个完整的表空间会被划分成多层逻辑结构,其中最小单位是page,每个page为16K;64个连续的page组成一个extent;多个extent和page构成一个segment。

一次查询中,如:select * from xxx_tabile where user_id = 1,数据库会根据二级索引定位到user_id=1的记录,其主键xxx_id分别为15、20、49,在通过主键索引回表查询到具体的记录返回给业务。
索引的定位过程如下:
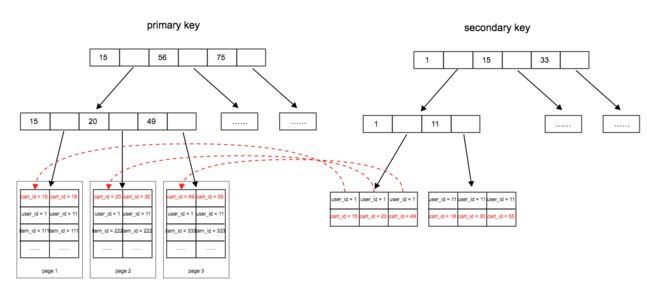
一次查询的开销为:
一次查询page数 = 二级索引page数 + 主键查询page数 + 系统额外page数
真实查询中的329个page是如何产生的,是否是因为由于业务需要访问的数据存放不连续,导致每个page的有效数据很少,所以总page数偏多?
在这样的思考下,通过修改xxx_tabile的主键和删除二级索引来进行验证。
- 删除二级索引ind_member_cart_userid和ind_member_cart_gmtm
- 主键从(xxx_id)调整为(user_id,xxx_id)
调整后的数据存储格式如下:
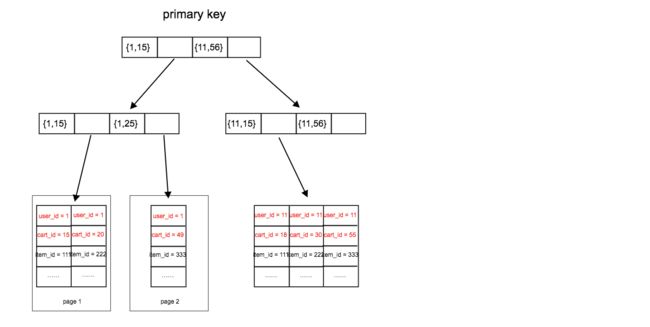
调整后的查询sql和结果如下:
query_time:0.000576
lock_time:0.000172
rows_sent:75
rows_examined:75
rows_affected:0
innodb_pages_read:19
调整后的查询开销为:
一次查询page数 = 主键查询page数 + 系统额外page数
其节省的开销为:
节省page数 = 二级索引page数 + 两者存储相差page数
当一个用户的记录越多,其数据分布的page数相差更大,为了进一步验证结果,通过dump出一个page的内存部分进行优化前后对比。
-
优化前,连续的数据空间存放了三位不同的用户数据,用户ID分别是89760032,198165792,90746656。
 优化前
优化前 -
优化后,连续的数据空间存放了用户ID为1312的用户数据。
 优化后
优化后
效果
优化后,XXX整个集群数据库读性能提升600%,平均逻辑读降低83.8%,缓存命中率提升1.3%,rt降低17.6%,从优化的过程和结果来看,最终的效果还是非常明显的。
1.4 读性能 or 写性能?—— 读写比
对于通过联合主键来提升db的性能这一方案,在最开始的阶段还是非常期待的,修改幅度不大但是效果明显,可以说收益比很高。
在XXC的包裹表中采用uid作为分表字段,也存在着大量的根据uid查询列表的复杂查询,因此在XXC的db优化中也准备引入这一方案,通过uid + pkgId(pkgId包裹id,原主键id)来作为新的联合主键,使得同一uid的数据排列更紧密。但是分析之后还是有一丝隐忧在里面,联合主键必然会导致主键的离散度加大,对db的写入性能会有一定的影响。
采用联合主键之后,实际测试的效果如下图,其中0512、0513、0514表采用联合主键,0515、0516表采用原有主键,db的读性能确实有一定的提升(rt降低19%),但是写性能上有一定的下降(rt升高16%)。
然而XXC是一个高读高写的应用,特别是在大促的高峰期,写甚至比读还要频繁,db的主要压力在写性能上,所以这种对写性能有损的方案暂时不会被采用。
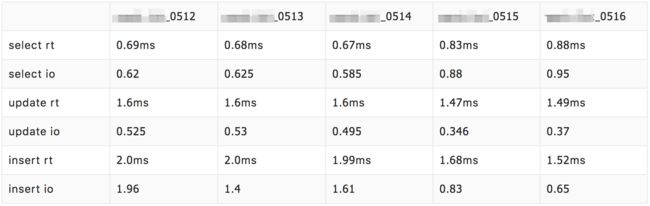
why
现在分析下为什么联合主键会导致写性能下降?
常规情况下包裹表的主键id采用的是tddl是自增squence生成器来生成的,每个分表的主键id虽然不是连续自增,但是也是单调自增,在新增记录的时候聚簇索引是的随机性很小,在不发生索引分裂的情况下,聚簇索引的查找基本是顺序的。
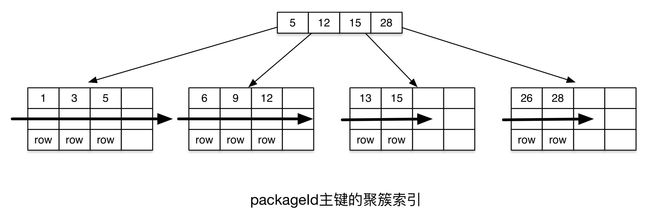
但是联合索引情况下,为了保证同uid下记录排列更紧密,聚簇索引先以uid排序再以packageId排序,如下图:
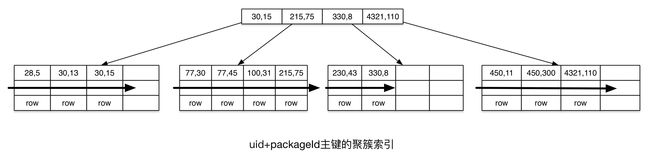
在新增记录的时候,则需要新按照uid查找,再按照packageId查找,则会导致聚簇索引的随机性变大,更有可能插入到原来已经排列满的page中,从而导致页分裂。

读写比
回过头去看看联合主键在XXX中应用的场景,发现这是一个读多写少的场景,用户的商品信息一经修改之后再修改的可能性就非常低,大量的是用户在手淘去查询自己的商品信息,所以联合主键来提升查询性能是可行的,少量修改带来的写入性能下降也在可接受的范围内。
至此,我们回过头来看一个储系统设计中非常重要的概念——读写比,它直接决定到存储系统的选型和优化方案的选择。
XXC场景中,过低的读写比不仅是弃用联合主键的关键原因,也影响到对索引和缓存的使用以及表结构的修改。可以说XXC在创建之初,没有正确的估计读写比对存储系统的影响,上线前也没有对应场景的压测,导致了短时间内出现比较严重的性能问题。因此后期对DB的优化也基本上围绕这点进行,在不推倒重建的前提下,尽可能在DB层面提升写性能,而读的问题则在应用系统层面通过复杂缓存系统去解决(2.3 缓存和缓存的代价中会介绍)。
2、SQL
2.1 sql的代价模型
SQL的每一种执行路径,均可以计算为一个对应的执行代价,代价越小,执行效率越高;代价越大,执行效率越高。
关于sql的代价模型,这里简单介绍下mysql中Range Query Optimizer分析的代价模型,详细内容可以查看下网易何登成对mysql查询优化的详细分析。
总的代价模型: SQL COST = IO Cost + CPU Cost
CPU Cost: Mysql服务处理sql返回所有的cpu计算时间,包括:sql解析、优化、排序、查找等
IO Cost: 存储引擎层面读写页面的开销,以Innodb为例,包括:聚簇索引、二级索引页面读写。
其中聚簇索引扫描代价为索引页面总数量;二级索引覆盖扫描是顺序IO代价较小;二级索引非覆盖扫描由于需要回表,其代价巨大,因为回表会产生大量的聚簇索引的随机IO读取。
2.2 IO —— 性能的敌人
sql代价模型可以进一步的细分为以下公式:
SQL COST = Random IO(RO) + Sequence IO(SO) + CPU

从上图可以看出,内存计算的操作耗时要比磁盘的操作耗时低好几个数量级,所以要降低SQL执行的代价,最重要的就是降低IO的操作,而且对于IO的操作在无法避免的情况下,需要尽可能的将SO转化为RO,RO相比于SO会有更少的IO操作次数,所以降低IO操作就成为存储系统中性能提升的关键手段。
XXC中核心包裹表在设计之初基本是一张大宽表,有将近40个字段属性,部分属性是静态的,在包裹从创建到签收的生命周期中基本不会变的,(如:商品名称、商品图 地址、签收 地址、签收 机号、签收人名称等)。属性过多带来的直接问题是单条记录太大,平均下来每条记录在1k字节左右(json格式化下),静态数据则会占据400字节左右,静态数据占约40%,而且由于业务的特殊性还会存在多条记录几乎95%相同的情况(仅uid不同),反应在db上则会有以下影响:
mysql binlog的row模式,现在集团对mysql的binlog都是row模式,也就是说针对单条记录的更新即使只新其中的一个属性,在做binlog的时候也是全字段记录,大量的静态数据也会被频繁的的写入文件中,导致db io居高不下,单机。
静态数据占据bp空间,同样的bp,如果单条记录越小,bp中能存储的记录条数就越多,在查询时需要的物 读就会更少,io压力相应就会减少。
XXC中包裹表主要采用以下手段来降低io操作的压力:
动静数据分离,包裹表的每条记录在生命周期内平均会被更新10多次,但基本都是状态变更,其中有大量的静态数据是不会被更新,因此需要把这些静态字段单独存储,多表之间通过包裹id关联。
清理垃圾字段,由于历史和业务原因,包裹表中遗留了一些不再使用的字段,通过在业务上的排查,清理这些垃圾字段。
降低字段长度,业务上在使用包裹表的feature字段过于随意,feature中定义的key很长,无形中会增加feature的长度,通过压缩feature平均可以降低100个字节左右。
合理利用索引,索引设置过于随意,往往是由于满足特定查询业务的需要而添加,没有考虑索引导致的副作用。优化过程中在业务上重新梳理索引的使用场景,通过redis缓存的使用、索引的重用等手段来去除非必要或者是可替代的索引。
整体操作下来,单体记录的长度可以降低约45%,这相当于提升了一本的存储能力,而且写入性能也大幅提升。
2.3 性能漏斗
在DB的性能优化中有一个漏斗法则,在漏斗法则中,从上到下代表所采取的优化收到带来的效果从大到小,而当所有优化手段都用完之后,最后只能通过增加资源来解决。
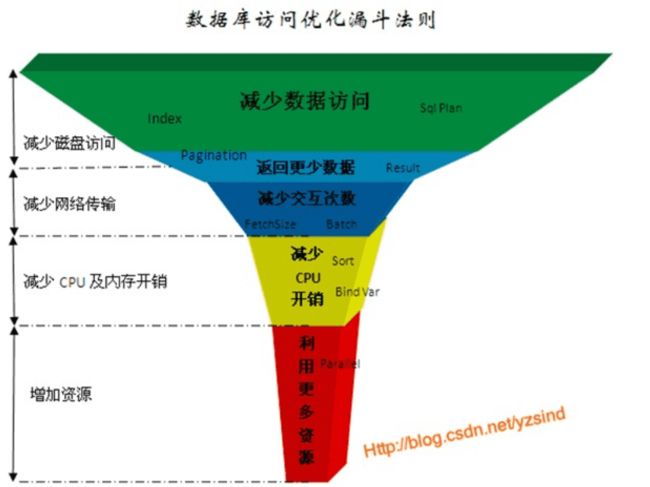
这张图所展示的漏斗法则,个人感觉并不是非常完备,但是依然可以结合漏斗法则来分析下XXC所采用的优化手段所处的位置以及带来的效果,以期望能找到一套db设计和性能优化的方法论。
-
减少数据访问:
减少数据访问的目的是带来更少的磁盘访问,这是收益很大的一项优化,因为磁盘的开销非常大。在db性能优化的过程中,我们一方面要结合Explain来观察sql的执行计划,设置合适的索引,所以索引的设置就非常重要。
然而就如我们之前讨论的,索引的设置也需要根据实际情况的考虑和review,更新频繁的情况下(特别是索引字段更新频繁),过多的索引往往会适得其反,这会带来写入性能的下降。
再者,如果我们把存储性能的指标提高到应用系统层面上来看,如果有更高效的数据访问途径,如:缓存,那就可以不从db中获取数据,那是否也就意味着更少的磁盘访问,所以缓存的合理利用是一项重要的手段,但凡事有利有弊,缓存的使用也会有代价,具体见后面的分析。
-
返回更少数据:
更少的数据代表着更少的数据读取,更少的数据处理,更少的数据传输,在XXC的优化中通过清理垃圾字段、压缩扩展字段、动静数据的分离,使得每次获取的数据量下降了45%。
-
减少交互次数:
这也是一个很好理解的方法,将多次类似查询改为批量查询,节省应用服务器和db服务的交互,充分利用每次链接的能力。
-
减少cpu开销:
引入memcache plugin,memcache plugin的原理和使用效果见后面的讨论,memcache plugin的引入使得主键查询更为高效。
XXC中使用redis的zset来保存最高频的手淘包裹列表id,通过zset的自动排序特性来解决列表查询时的排序和分页问题,从而将以前在db中的耗时的复杂排序转移到redis中来,在通过ids去获取具体的包裹信息,由于有mdb(mget完全命中率40%,get命中率70%)和memcache plugin的存在,真正走sql查询的包裹占比极其少,整体上大大降低对db的压力。
3、设计
最后对整个优化过程中其他一些关于设计的思考进行一个总结。
3.1 范式&反范式
在我之前做过的绝大多数应用系统中,很少会去考虑范式和反范式的设计,一方面是因为业务的前期基本都是以快速满足需求推进为主,过于严苛的范式设计往往会拖延项目的速度;另一方面是因为集团的基础设已经非常完善,性能也足够强大,基本的分库分表加缓存就可以支持了绝大部分业务的性能需求。又快又傻瓜的环境下,容易让人产生思维上的惰性,有一次一个刚毕业的同学在质问我的设计为什么没有按照范式规则时,我也一时无法回答,甚至连一二三范式的定义都忘记了。
什么时候需要考虑范式,范式规则的价值到底是什么,互联网环境下的开发过程中反范式为什么大行其道,其实并没有思考的很清楚。
首先讨论下为什么互联网环境中反范式大行其道,互联网中的业务基本都是短平快,主要以满足业务的快速推进为主,绝大多数的应用能活多久,能到多大的量都是一个未知数,所以过于复杂的设计往往是没有必要的,一张大宽表搞定所有场景,快速出活是关键。
然而随着时间的推进,有的业务发展的很好,早期大宽表的设计可能渐渐不再满足需求,这个时候就需要回过头来重新审视下之前的方案。所以什么时候需要考虑范式是一个很模糊的问题,是在方案一开始设计就考虑,还是在预感到有问题时考虑,还是在问题爆发的时候再去考虑?
我的答案是对于架构师来说不应该是什么时候考虑,而应该是时时考虑,只是考虑的度如何把握。一个好的架构师思考的问题,不应该仅仅只是把眼前的问题给解决掉,需要了解业务发展的方向和速度,还需要有足够深厚的技术积累和技术广度,丰富的实际经验为未来做提前准备。
XXC的早期设计中,如果对业务特性更有深入了解,对写入性能和缓存使用足够重视,开发排期上从容点,在模型设计上可能会有另一种考虑。
3.2 读写分离
在优化过程中也对读写分离的方案进行过考虑,主要包括两点:
-
业务应用读写分离
业务应用的读写分离是指根据业务的特性将读业务和写业务分成两个应用,一般常见于读写请求qps都很高的业务或者读写都很复杂的业务,类似的业务可能是核心应用。业务上读写分离之后的好处是维护上更加专注,可靠性更高,业务开发维护上也更清晰。XXC应用的业务上还没有复杂到需要进行切分的地步,应用维护上也没有太大的问题,所以业务层面上的读写分离没有考虑过。
-
mysql读写分离
mysql读写分离是指将db分为读和写两个集群,读写集群中采用mysql的数据同步机制来保证数据一致性。在读写压力都很高的应用场景下,存储的读写分离可以避免读写情况的压力共振,稳定性得以保证。但是由于数据的一致性依靠同步机制来保证,读写集群下数据有可能不一致,特别是大促期间同步的延迟会很长,所以对数据实时性要求很高的应用不是很适合。
3.3 缓存和缓存的代价
缓存是大流量系统中常用的提升系统性能和稳定性的方案,XXC系统中也大量使用到了缓存,包括:使用redis的zset来存储包裹的id用以减少对db的复杂排序sql的查询,把复杂排序sql的查询转换成对主键id的查询;使用mdb来缓存包裹对象,减少主键id查询时到达db的流量。从而在db层面上,把复杂耗时的查询,转化成少量的简单查询。
然而缓存的引入是有代价的,对应用的性能和维护性都有侵害。
- 应用性能:缓存的引入必然会带来大量的rpc调用以及额外rt的消耗,虽然现在的缓存系统在性能上都足够强悍,rt都基本在0.5ms下,但是大量的rpc调用还是会对应用系统的性能带来负面的影响,同时在使用缓存时也会有频繁的序列化操作,这些都是需要仔细考虑的,选择高效的序列化方式非常重要。
- 维护性:系统的简单和可维护性非常重要,三行代码带来的性能消耗和出问题的几率绝对比十行代码要低。缓存的引入会提升设计开发实现的复杂度,缓存系统自身的稳定性也需要维护,同时也带来一致性的问题,特别是多套缓存系统并存的情况下,所以一套高效的缓存框架就非常重要。
做任何一种选择都会带来正面和负面的影响,只是两个方面对系统的影响程度不同,所以解决问题的度也需要好好的把握。比如一个性能问题,花费10%的代价可以提升80%的性能,而在现有方案继续再往上提升5%的性能需要花费30%甚至50%的代价时,就需要好好考虑是否是值得的,没有一个方法和方案可以解决100%的问题,甚至90%都解决不了。
3.4 银弹 —— 是否有银弹?
银弹是中世纪传说中杀死狼人的最好的方法,它可以很简单又永久的解决狼人带来的威胁。
在现代软件工程中,银弹被比喻为解决复杂项目的最优手段。面对大型复杂变化频繁的系统,系统开发和维护人员希望能有一种技术或者手段来一劳永逸的解决所有问题,甚至解决以后可能发生的问题。
在XXC的存储优化过程中,面对已存在的设计和性能问题,以及未来的容量性能目标,需要思考的是采用什么样的方法来达到目标,是否有一种推倒重来一劳永逸的解决方案,还是在现有方案的基础上渐渐式修改,而且在渐渐式修改的过程中,是否也有一种可以极大提升性能(2倍3倍甚至10倍)的方法?
也就是复杂大型系统中是否有银弹来解决所有问题?
至少在XXC的存储优化过程中,我们没有采用推倒重建的方案(时间、成本、业务、风险上不允许),也没有找到一种可以极大提升性能的方法,更多的是从当前系统所处的业务场景的实际情况(稳定性、容量、qps、读写比、表和索引的设计)以及对于未来业务发展的预测,通过业务上的流量均衡、数据表动静数据分离、冷热数据精细划分、索引的重用和清理、多种缓存(redis、mdb)的使用、mysql最新技术的引入(memcache plugin)来优化和提升系统的整体性能。
这其中每一个修改点都不足以对整体的系统产生质的改变,然而每一个修改点都会系统产生正面的影响,在动态中推动系统性能整体向前进。
系统的维护和优化是一个长期的过程,也是一个痛苦的过程,业务在快速变化,人员水平也参次不齐,时时刻刻都在对系统进行腐朽。这就对架构师提出了更高的要求:
- 架构师要有清晰的理论知识和丰富的业务实践经验,能够针对不同的业务场景对症下药,有取有舍,设计合适的解决方案
- 架构师要有足够的预见性以及对业务的全局把控力和反向影响力,尽可能的使系统在全局层面能快速合理的支持业务的发展
- 架构师要有深厚的技术功底和思考积累,能指导和影响团队成员按照一致的方案、架构、规范、风格来完成编码
如果说代码世界中有银弹的话,那么应该是不断的提升自己的思考的深度、技术积累深度以及解决问题的能力,在面对不同问题时的判别和取舍能力。
3.5 技术的视野
在mysql 5.7中引入了memcache plugin特性,提升主键查询的性能。其简单原理是client通过memcache协议,直接查询innodb的缓存,省去了复杂的sql解析、优化的过程,而且memcache协议相对于sql协议也轻便许多,由于是基于innodb的缓存也保证了数据的一致性,但带来的局限是只能通过主键查询。
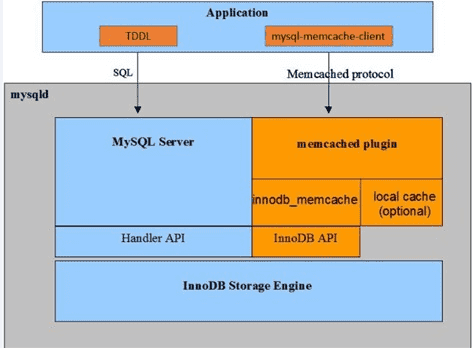
集团DBA团队也针对这个特性开发出了相应的工具包(XKV),使用在业务上效果非常明显。同等条件下压力测试,开启memcache plugin的库的主键读rt要比单纯的sql查询要降低50%(0.82ms->0.39ms)左右。


新技术的引入带来的性能收益是巨大的,做为开发人员还是需要能紧跟技术发展的趋势,而做为架构师更需要在开阔视野的同时,对技术发展的方向和趋势有所判别,对新技术的使用场景、特性和风险有充分的了解,把新技术的红利真正使用到实际场景中。