概念
生物标志物,即传说中的biomarker,是一类可测量的,用来表征疾病状态的物质,通常用于表征:
- 疾病的状态(是否为某种疾病/某种亚型);
- 药物敏感性,用于用药指导;
- 生理状态监测。
类型
- 预后指标
预测疾病的预后效果(独立于治疗),如AB1-42可用于诊断老年痴呆预后。 预测型标志物
预测疾病类型/针对某种治疗的响应,如HER2、EGFR、 K-RAS等突变可用于预测肿瘤发生的几率。药物监测标志物
对某治疗的实时评价,如血液中的CRP、 IL-6、TNFa 浓度可监控炎症的进展。
效果评价
受试者工作特征曲线(Receiver Operating Characteristic,ROC)是评估一个生物标志物的预测性能的有用的图形工具,指示一个生物标志物组区分两个群组(如实验组和对照组,疾病和健康)的能力。
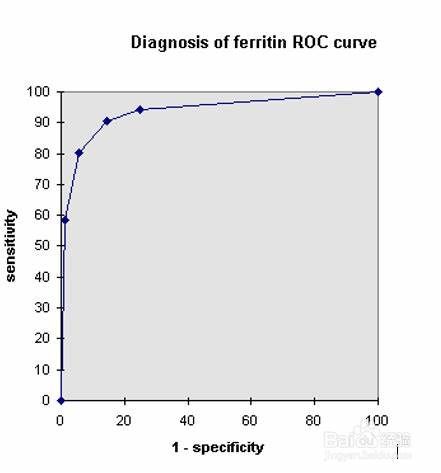
如果把患病视为阳性,把健康视为阴性。敏感性(sensitivity)表示真阳性除以真阳性与假阴性之和,又称为真阳性率,如下图所示:

特异性(specificity)表示真阴性除以真阴性与假阳性之和,又称为真阴性率,如下图所示:

1-真阴性率=假阳性率,所以ROC曲线横轴是假阳性率,纵轴是真阳性率,曲线下的面积为AUC值,通常介于0.5-1之间,面积越大预测效果越好。

上图是单变量的ROC分析,针对单个代谢组分子或单组学数据。实际上,可以将多个代谢物或多个组学数据作为组合来进行预测,称之为多变量ROC分析。不同模型预测的结果也可以同时在一张图中比较。

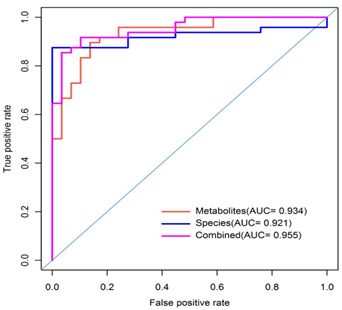
多变量ROC分析
多变量ROC分析主要是用于探寻最佳的生物标志物组。通过选择RandomForest,SVM和PLS-DA 等多元统计分类算法,选择不同的代谢物排序组合,反复抽样的构建分类模型,获得最佳的生物标志物组。
在多元ROC分析中,选择最佳的变量组合主要是通过重复随机抽样交叉验证(CV)的算法来识别变量重要性。在每次验证中,三分之二(2/3)的样本根据VIP评分(PLSDA)、精度下降(随机森林)或加权系数(线性支持向量机)来评价每个特征的重要性。选择排名前2,3,5,10,100(Max)重要特征用来建立分类/回归模型,并在1/3的剩余样本上进行验证。
如下图:

上图是基于PLS-DA 分类方法,变量重要性依据PLS-DA分析的VIP值排序,分别选择前2个,前3个,前5个,前10个,前20个和全部变量的模型的ROC曲线和AUC值。可以看出,图中最佳的生物标志物组是基于PLS-DA分析VIP值排序的前2个代谢物组成的生物标志物组。
验证
验证上述筛选出的生物标志物组,或选择特定的生物标志物组,计算区分效果(AUC)值。可以从构建的最佳生物标志物组中进一步选择样本进行验证,也可以手动选择生物标志物组进行分析。
如上例中筛选出的2个代谢物的为最佳生物标志物组进行验证下。
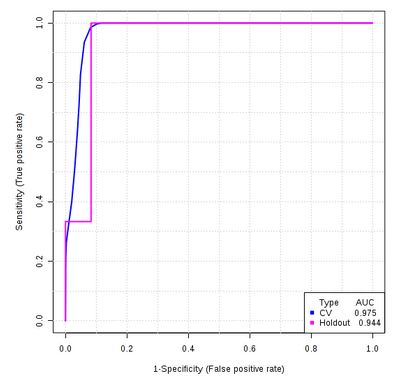
图中CV表示经过100次交互验证后的ROC曲线;Holdout 表示手动选择测试集后计算得到的ROC曲线,说明该生物标志物组预测效果良好。
关于单变量和多变量ROC曲线分析的比较
多变量ROC曲线是基于多元统计(SVM、PLS-DA或随机森林)的交叉验证结果。而经典的单变量ROC曲线是基于测试集中所有数据点内所有可能的截断点的综合效果。因此由交叉验证的ROC曲线得到的AUC更适合预测,而单变量ROC计算的AUC往往容易过拟合。换句话说,单变量ROC可以被看作是特征的区分“潜力”的一个指标,而不是它的实际表现。
分析工具
几个可以进行ROC分析的R包。

MetaboAnalyst也具有相应的分析模块。
Ref:
http://interact.majorbio.com/article/view/talk_id/345