* Flume框架基础
框架简介:
** Flume提供一个分布式的,可靠的,对大数据量的日志进行高效收集、聚集、移动的服务,Flume只能在Unix环境下运行。
** Flume基于流式架构,容错性强,也很灵活简单,主要用于在线实时的引用分析。
宏观认知:
** Flume、Kafka用来实时进行数据收集,Spark、Storm用来实时处理数据,impala用来实时查询。
Flume架构图:
如果所示,Flume架构只有一个Agent角色节点,该角色节点由Source、Channel、Sink组成。
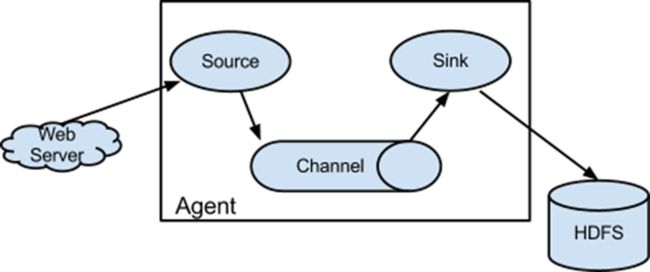
简单介绍一下各个组成部分的功能:
Source:Source用于采集数据,Source是产生数据流的地方,同时Source会将产生的数据流传输到Channel,这个有点类似于Java IO部分的Channel。
Channel:用于桥接Sources和Sinks,类似于一个队列。
Sink:从Channel收集数据,将数据写到目标源(可以是下一个Source,也可以是HDFS或者HBase)
数据传输单元:Event
** Event是Flume数据传输的基本单元
** Flume以事件的形式将数据从源头送至目的地
** Envent由可选的header和载有数据的一个byte array构成,载有的数据对于flume是不透明的,header容纳了key-value键值对的无需集合,key在某个集合内唯一,header还可以在上下文路由中拓展使用。
Flume传输过程:
如下图所示,source监控某个文件,文件产生新的数据,拿到该数据后,将数据封装在一个Event中,并put到channel后commit提交,channel队列先进先出,sink去channel队列中拉取数据,然后写入到hdfs或者HBase中。
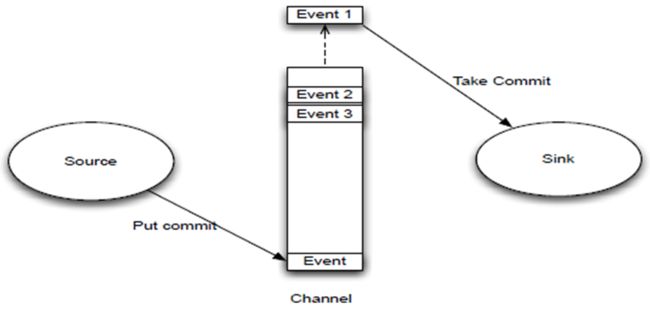
* 安装Flume
** 下载地址传送门:链接:http://pan.baidu.com/s/1eSOOKam 密码:ll6r
** 拷贝,解压,不赘述了
** 配置文件
将conf目录下的flume-env.sh(重命名template文件就行了)文件的JAVA_HOME配置一下,依然不赘述了
** 命令使用
$ bin/flume-ng,出现如下图所示内容:
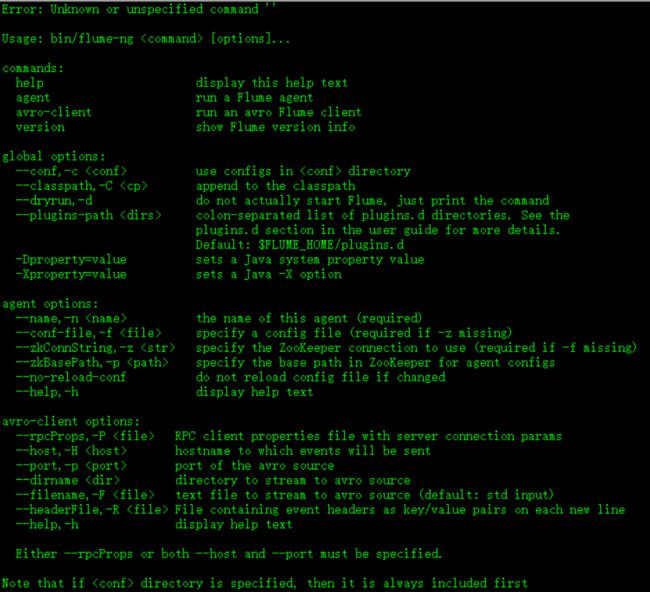
解释:
--conf:指定配置目录
--name:指定Agent名称
--conf-file:指定具体的配置文件
* 案例
例1:使用flume监听某个端口,将端口写入的数据输出
Step1、修改配置文件
$ cp -a conf/flume-conf.properties.template conf/flume-telnet.conf,变更为如下内容:

解释:
r1:即源,监控的数据源,resource的缩写
k1:即 sink缩写
c1:即channel缩写
Step2、安装telnet命令
由于默认没有该命令,我们来使用yum命令安装一下,注意进入root用户
# yum -y install telnet
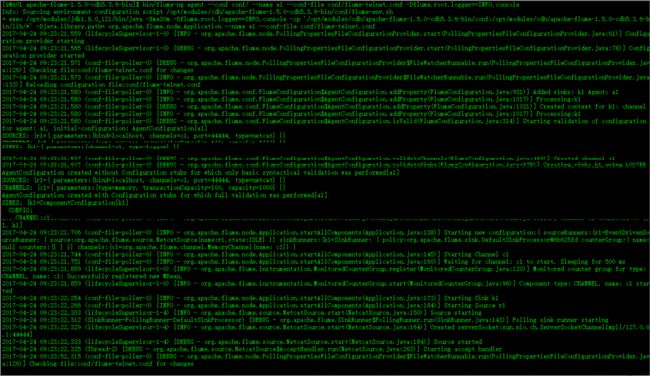
Step3、运行flume端口监控
$ bin/flume-ng agent --conf conf/ --name a1 --conf-file conf/flume-telnet.conf -Dflume.root.logger==INFO,console
分别指定name,配置文件目录,配置文件,以及输出类型和位置。
运行如图:
Step4、测试
另开一个CRT到z01的界面
执行命令:
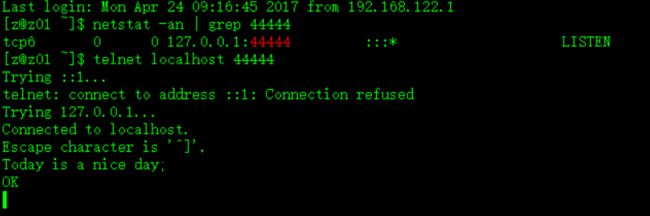
$ netstat -an | grep 44444,用于检查44444端口是否已经被flume成功监听,如图:

$ telnet localhost 44444,用于连接本机44444端口,进行数据发送(此处也可是使用其他命令,比如netcat等),此处在另一个窗口中进行telnet命令,原来执行flume的那个窗口查看数据是否成功监听到,测试如图:
发送端:
监听端:
如图所示,测试成功。如果需要退出telnet,使用ctrl+]键,再输入quit即可。
例2:某个系统框架的日志文件到HDFS
Step1、修改配置文件
更多参数配置的含义,请参看官文:http://flume.apache.org/FlumeUserGuide.html#hdfs-sink
$ cp -a conf/flume-telnet.conf conf/flume-apache-log.conf,变更为如下内容:
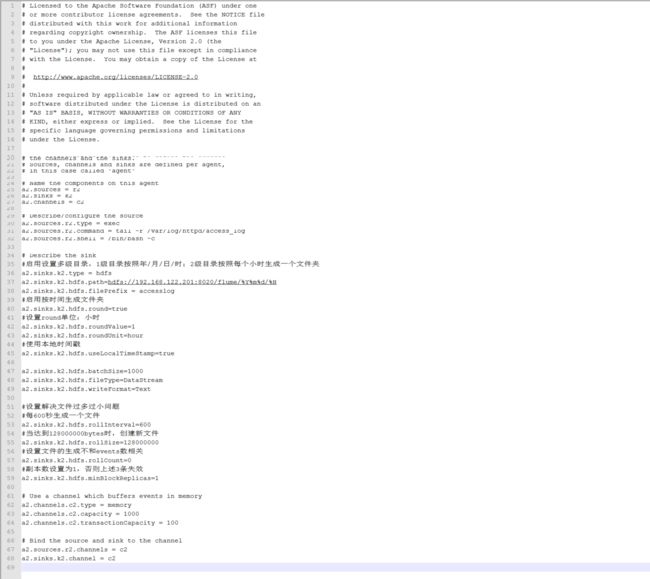
知识补充:

Step2、安装httpd
# yum -y install httpd
(注:httpd是Apache HTTP服务器的主程序。被设计为一个独立运行的后台进程,它会建立一个处理请求的子进程或线程的池)
Step3、启动httpd服务
centOS 7:
# systemctl start httpd.service
centOS 6:
# service httpd start
Step4、修改/var/log目录下的httpd文件夹的权限,以便于访问
# chmod 755 /var/log/httpd/
# vi /var/www/html/index.html,随便写点什么,如图:

Step5、执行如下 命令后,使用浏览器访问网页,查看产生的日志
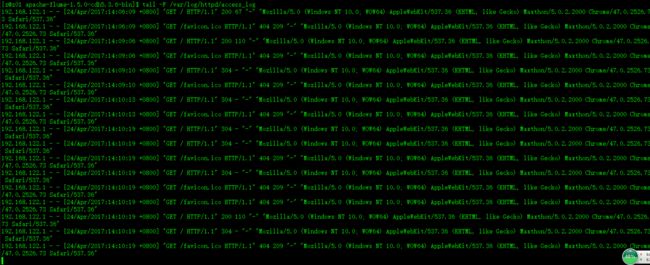
$ tail -f /var/log/httpd/access_log,多次访问后,如图所示:
(浏览器打开:192.168.122.200,根据自己的配置IP访问即可。)
Step6、拷贝Flume所依赖的Hadoop的jar到自己的lib目录
cp /opt/modules/cdh/hadoop-2.5.0-cdh5.3.6/share/hadoop/common/lib/hadoop-auth-2.5.0-cdh5.3.6.jar /opt/modules/cdh/apache-flume-1.5.0-cdh5.3.6-bin/lib
cp /opt/modules/cdh/hadoop-2.5.0-cdh5.3.6/share/hadoop/common/lib/commons-configuration-1.6.jar /opt/modules/cdh/apache-flume-1.5.0-cdh5.3.6-bin/lib
cp /opt/modules/cdh/hadoop-2.5.0-cdh5.3.6/share/hadoop/mapreduce1/lib/hadoop-hdfs-2.5.0-cdh5.3.6.jar /opt/modules/cdh/apache-flume-1.5.0-cdh5.3.6-bin/lib
cp /opt/modules/cdh/hadoop-2.5.0-cdh5.3.6/share/hadoop/common/hadoop-common-2.5.0-cdh5.3.6.jar /opt/modules/cdh/apache-flume-1.5.0-cdh5.3.6-bin/lib
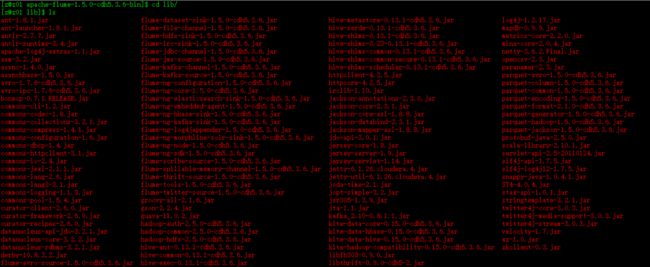
拷贝完成后,flume的lib目录如下:
Step7、启动Hadoop相关服务后,执行flume-ng命令
$ bin/flume-ng agent --conf conf/ --name a2 --conf-file conf/flume-apache-log.conf
(尖叫提示:如果想让flume-ng命令在后台运行,不持续占用终端的操作,可以在命令的末尾加上&符号,即:
$ bin/flume-ng agent --conf conf/ --name a2 --conf-file conf/flume-apache-log.conf &)
检查flume的log日志,没有确认没有ERROR或者WARN错误后,刷新index.html页面,即可看到日志已经迁移至HDFS集群,如图:
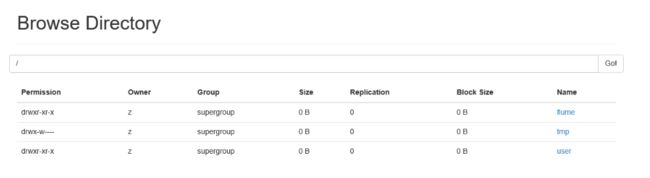
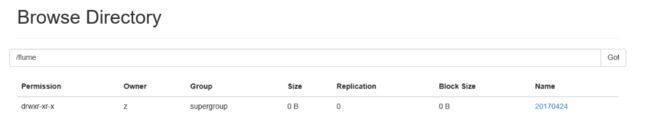
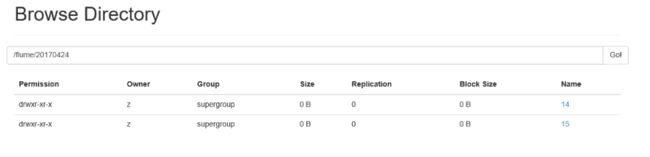
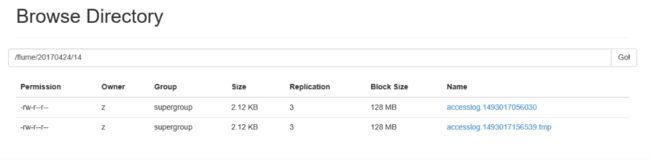
以上便实现了Flume的日志收集,其他收集大同小异,大家可自行参照官方文档中的参数设置。
* 总结
flume就是一个流式的,日志采集框架,就像是一个挂在后台的收集器一样,实时监听你需要收集的文件或者目录。
IT全栈公众号:

QQ大数据技术交流群(广告勿入):476966007

下一节:Oozie框架基础