1.前言
本文讲述如何使用IDEA远程调试spark,这里所说的调试spark包括:
- 调试spark应用程序,也就是使用spark算子编写的driver application
- spark自身,包括master,worker,所以这个主要针对的是standalone模式下的,使用yarn提交时不存在master和worker这两个角色。
在开始之前会介绍一下如何使用idea远程debug普通的jar应用,然后远程debug spark原理是一样的。
2. 远程debug 普通的jar应用
先假设远程debug的适用场景是:我将应用程序打成jar包,让它运行在服务器上,然后在本地idea里以debug模式去运行这个jar包,希望达到的效果就像在idea里debug本地代码一样:可以断点,可以查看变量值等等。
下文将这个运行在服务器上的jar包称为被调试对象(debuggee)。 本地idea称为调试者(debugger).
远程调试有两种模式,或者说有两种方式可选:
- attach模式, 运行debuggee,让其监听某个ip:port,然后等待debugger启动并连接这个端口,然后就可以在debugger上断点调试。
- listen模式,让debugger监听某个ip:port, 然后启动debugee连接这个端口,接下来在debugger上断点调试。
以"HelloWorld" 程序为例:
package me.test.helloworld;
public class HelloWorld {
public static void main(String[] args){
System.out.println("hello world");
for(String arg : args){
System.out.println(arg);
}
}
}
-----------
使用mvn打包,然后可以通过如下命令运行:
> java -cp helloworld-1.0-SNAPSHOT.jar me.test.helloworld.HelloWorld arg1 arg2
2.1 远程调试模式-1 attach模式
在这种模式下让debuggee监听端口等待debugger连接.
IDEA里操作如下图:

按照上图复制-agentlib:jdwp=transport=dt_socket,server=y,suspend=y,address=5005,这个是给debuggee的jvm参数。
- 这里将suspend=n, 改成了suspend=y, 这样debuggee启动后会阻塞住直到debugger连接它
- address=5005,表示debuggee监听这个端口,也可以指定成address=
: 的形式,这里ip是debuggee运行所在的机器的ip - 上图中Host, Port应该和上面address中的ip,port一样,debugger会连接这个ip:port
- transport=dt_socket是debugger和debuggee之间传输协议
- server=y, 在模式1下这样指定, 表示debuggee作为server等待debugger连接
在idea(debugger)里指定好这些以后, 接下来就是先 运行debuggee了,如下:
java -cp helloworld-1.0-SNAPSHOT.jar -agentlib:jdwp=transport=dt_socket,server=y,suspend=y,address=192.168.1.102:5005 me.test.helloworld.HelloWorld arg1 arg2
运行后出现下面信息:
Listening for transport dt_socket at address: 5005
表示debuggee等待连接。
接下来的过程就是在idea里,设置断点,然后像本地debug一样了。
2.2 远程调试模式-2 listen模式
即让debugger监听端口等待debuggee的连接, 因此先启动debugger。
IDEA里操作如下:
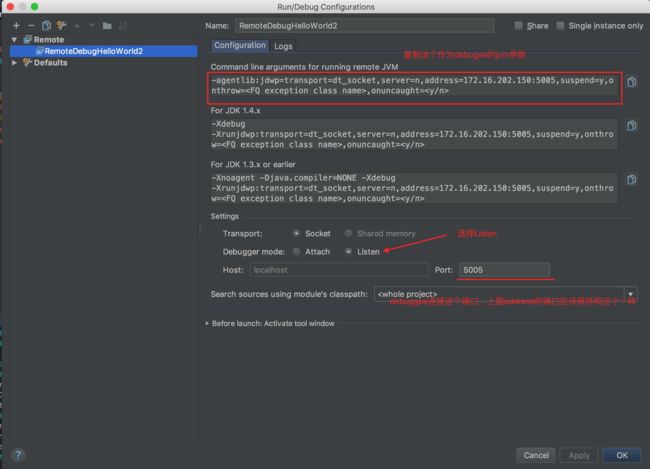
该模式下先启动debugger,也就是启动idea调试,debugger会监听端口等待debuggee连接。
按照上图复制给debuggee的jvm参数:
-agentlib:jdwp=transport=dt_socket,server=n,address=172.16.202.150:5005,suspend=y
- 这里去掉了
onthrow=不知道是干什么的,onuncaught= - address==172.16.202.150:5005, debuggee连接该ip:port
- suspend=y, listen模式下可以去掉
- server=n, 表示由debuggee发起连接到debugger。
此时debugger先运行并监听端口,接下来运行debuggee就可以了,如下:
java -cp helloworld-1.0-SNAPSHOT.jar -agentlib:jdwp=transport=dt_socket,server=n,address=172.16.202.150:5005 me.test.helloworld.HelloWorld
本章参考使用 Eclipse 远程调试 Java 应用程序
3. 调试Spark
Spark按照角色可以分为Master、 Worker、Driver、Executor。其中Master, Worker只有在Standalone部署模式下才有,使用Yarn提交时只有Driver可Executor。使用Spark算子开发的应用提交执行后会都一个Driver和至少一个Executor,Driver充当job manager的角色,executor作为task executor执行算子。
下文先按照Master,Worker,Driver,Executor的顺序介绍如何远程调试。
3.1 调试Master
Master的main 方法入口在org.apache.spark.deploy.master.Master中。
通过spark源码包中的sbin/start-master.sh运行Master,源码包中查找的jar包的路径是assembly/target/scala-, 修改了源码后可以通过运行mvn install -DskipTests重新生成jar包到该路径下。
想要远程调试Master主要就是怎么将-agentlib:jdwp=transport=dt_socket,server=y,suspend=y,address=5005这种参数设置为启动Master的jvm参数了。
这里涉及到了启动Master的过程,不讲了,直接说方法。Master启动时会接收:SPARK_MASTER_OPTS和SPARK_DAEMON_JAVA_OPTS这两个环境变量的值作为master启动的jvm参数,其中:
- SPARK_MASTER_OPTS仅仅被Master使用
- SPARK_DAEMON_JAVA_OPTS,会被Master和Worker使用
因此可以在start-master.sh中设置环境变量如下:
export SPARK_MASTER_OPTS=-agentlib:jdwp=transport=dt_socket,server=y,suspend=y,address=5005
这样运行start-master.sh, 随后就能在${SPARK_HOME}/logs路径下生成的日志文件里看到
Listening for transport dt_socket at address: 5005
这样一条日志信息,表示Master的jvm阻塞并监听端口等待debugger连接,结下来就是在idea里建立远程连接。
还可以在${SPARK_HOME}/conf下面新建一个文件名为java-opts, 在这个文件里放jvm参数,一个参数一行,如下所示:
-agentlib:jdwp=transport=dt_socket,server=y,suspend=y,address=5005
-Xmn2G
但是这个文件内容会被Master,Worker启动时作为jvm参数使用。
注:不要通过以上在几种方式里加-Xmx指定最大堆内存,可以通过设置环境变量SPARK_DAEMON_MEMORY为1G等等这种方式设置-Xmx的值。对于Worker也是同样的。
3.2 调试Worker
Worker的main方法在org.apache.spark.deploy.worker.Worker中。
通过sbin/start-worker.sh启动worker。
和Master不同的是Worker的jvm启动参数的值是从环境变量SPARK_WORKER_OPTS读取的。
可以在start-worker.sh中通过
export SPARK_WORKER_OPTS=-agentlib:jdwp=transport=dt_socket,server=y,suspend=y,address=5006
设置。其他和Master一样。
3.3 调试Driver
用户自己使用Spark算子开发应用,然后使用spark-submit.sh提交应用去集群作为一个job运行,job运行起来后会有一个driver和若干executor,driver相当于这个运行中的job的JobManager,负责将RDD DAG划分为stage,创建task,调度task去executor执行等等。
从运行spark-submit脚本,到用户打包的jar被提交的集群运行,中间经历好几个过程。最终是由org.apache.spark.deploy.SparkSubmit,SparkSubmit自身的启动命令是由 org.apache.spark.launcher.Main创建的,创建时会从环境变量SPARK_SUBMIT_OPTS获取值作为SparkSubmit的jvm参数,所以可用export SPARK_SUBMIT_OPTS=-agentlib:jdwp=transport=dt_socket,server=y,suspend=y,address=来调试SparkSubmit。
说回Driver,可以在${SPARK_HOME}/conf/下创建spark-defaults.conf文件,加入下面一行:
spark.driver.extraJavaOptions -agentlib:jdwp=transport=dt_socket,server=y,suspend=y,address=5009
spark.driver.extraJavaOptions后面的配置都会作为driver的jvm启动参数,后面就是在idea里断点调试driver了
3.4 调试Executor
driver只是一个job manager的角色,任务的执行(也就是那些spark 算子map, filter...的执行是在executor上执行的)。
executor对应的main方法所在类是org.apache.spark.executor.CoarseGrainedExecutorBackend。
由于一个job 可能有多个executor,不是很好调试,不过测试环境下应该可以设置一个executor,executor的jvm启动参数可以通过在${SPARK_HOME/conf/spark-defaults.conf}文件中加入:
spark.executor.extraJavaOptions your-executor-jvm-params
传递。 比如:
spark.executor.extraJavaOptions -agentlib:jdwp=transport=dt_socket,server=y,suspend=y,address=5005
设置按照这种方式设置好后,使用spark-submit.sh提交任务,假设是在standalone模式的集群,那么提交运行后Driver会先运行起来, 然后Driver申请在某个Worker上运行org.apache.spark.executor.CoarseGrainedExecutorBackend, 这个会单独起一个jvm,使用spark.executor.extraJavaOptions参数,如果使用模式1 attach模式,你就可以在CoarseGrainedExecutorBackend里断点调试了。
CoarseGrainedExecutorBackend运行起来不代表运行spark 算子的任务运行起来了,Driver会将任务序列化发送给CoarseGrainedExecutorBackend去执行,CoarseGrainedExecutorBackend创建Executor(包org.apache.spark.executor.Executor)去执行task,可以在Executor的run方法断点去调试任务。