synchronized
synchronized主要是用于解决线程安全问题的,而线程安全问题的主要诱因有如下两点:
- 存在共享数据(也称临界资源)
- 存在多条线程共同操作这些共享数据
解决线程安全问题的根本方法:
- 同一时刻有且只有一个线程在操作共享数据,其他线程必须等到该线程处理完数据后再对共享数据进行操作
所以互斥锁是解决问题的办法之一,互斥锁的特性如下:
互斥性:即在同一时间只允许一个线程持有某个对象锁,通过这种特性来实现多线程的协调机制,这样在同一时间只有一个线程对需要同步的代码块(复合操作)进行访问。互斥性也称为操作的原子性
可见性:必须确保在锁被释放之前,对共享变量所做的修改,对于随后获得该锁的另一个线程是可见的(即在获得锁时应获得最新共享变量的值),否则另一个线程可能是在本地缓存的某个副本上继续操作,从而引起数据不一致问题
而synchronized就可以实现互斥锁的特性,不过需要注意的是synchronized锁的不是代码,而是对象。
根据获取的锁可以分为两类:
- 对象锁:获取对象锁有两种用法
- 同步代码块(synchronized(this),synchronized(类实例对象)),锁是小括号()中的实例对象
- 同步非静态方法(synchronized method),锁是当前的实例对象,即this
- 类锁:获取类锁也有两种用法
- 同步代码块(synchronized(类.class)),锁是小括号()中的类对象(Class对象)
- 同步静态方法(synchronized static method),锁是当前对象的类对象(Class对象)
对象锁和类锁的总结:
- 有线程访问对象的同步块代码时,另外的线程可以访问该对象的非同步代码块
- 若锁住的是同一个对象,一个线程在访问对象的同步代码块时,另一个访问对象的同步代码块的线程会被阻塞
- 若锁住的是同一个对象,一个线程在访问对象的同步方法时,另一个访问对象同步方法的线程会被阻塞
- 若锁住的是同一个对象,一个线程在访问对象的同步块时,另一个访问对象同步方法的线程会被阻塞,反之亦然
- 同一个类的不同对象的对象锁互不干扰
- 类锁由于也是一把特殊的对象锁,因此表现与上述1,2,3,4一致,而由于一个类只有一把对象锁,所以同一个类的不同对象使用类锁将会是同步的
- 类锁和对象锁互补干扰,因为类对象和实例对象不是同一个对象
synchronized底层实现原理
实现synchronized需要依赖两个基础概念:
- Java对象头
- Monitor
Java对象在内存中的布局主要分为三块区域:
- 对象头
- 实例数据
- 对齐填充
synchronized使用的锁对象是存储在Java对象头里的,对象头结构如下:
由于对象头信息是与对象自身定义的数据没有关系的额外存储成本,考虑到JVM的空间效率,Mark Word被设计为非固定的数据结构以便存储更多有效的数据,它会根据对象自身的状态赋予自己的存储空间: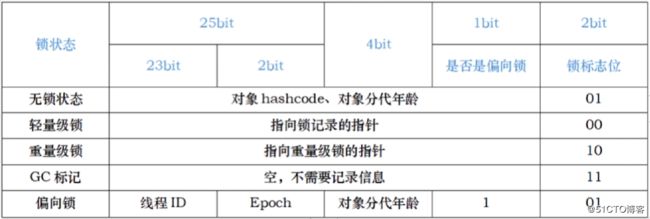
简单介绍了对象头,接着我们来了解一下Monitor,每个Java对象天生自带了一把看不见的锁,它叫做内部锁或Monitor锁。Monitor的主要实现代码在ObjectMonitor.hpp中: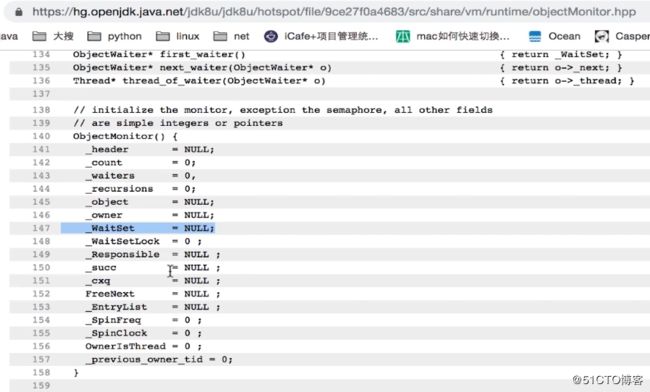
Monitor锁的竞争、获取与释放:
然后我们从字节码层面上看一下synchronized,将如下代码通过javac编译成class文件:
package com.example.demo.thread;
/**
* @author 01
* @date 2019-07-20
**/
public class SyncBlockAndMethod {
public void syncsTask() {
synchronized (this) {
System.out.println("Hello syncsTask");
}
}
public synchronized void syncTask() {
System.out.println("Hello syncTask");
}
}然后通过 javap -verbose 将class文件反编译成可阅读的字节码内容,如下:
Classfile /E:/Java_IDEA/demo/src/main/java/com/example/demo/thread/SyncBlockAndMethod.class
Last modified 2019年7月20日; size 637 bytes
MD5 checksum 7600723349daa088a5353acd84c80fa5
Compiled from "SyncBlockAndMethod.java"
public class com.example.demo.thread.SyncBlockAndMethod
minor version: 0
major version: 55
flags: (0x0021) ACC_PUBLIC, ACC_SUPER
this_class: #6 // com/example/demo/thread/SyncBlockAndMethod
super_class: #7 // java/lang/Object
interfaces: 0, fields: 0, methods: 3, attributes: 1
Constant pool:
#1 = Methodref #7.#18 // java/lang/Object."":()V
#2 = Fieldref #19.#20 // java/lang/System.out:Ljava/io/PrintStream;
#3 = String #21 // Hello syncsTask
#4 = Methodref #22.#23 // java/io/PrintStream.println:(Ljava/lang/String;)V
#5 = String #24 // Hello syncTask
#6 = Class #25 // com/example/demo/thread/SyncBlockAndMethod
#7 = Class #26 // java/lang/Object
#8 = Utf8
#9 = Utf8 ()V
#10 = Utf8 Code
#11 = Utf8 LineNumberTable
#12 = Utf8 syncsTask
#13 = Utf8 StackMapTable
#14 = Class #27 // java/lang/Throwable
#15 = Utf8 syncTask
#16 = Utf8 SourceFile
#17 = Utf8 SyncBlockAndMethod.java
#18 = NameAndType #8:#9 // "":()V
#19 = Class #28 // java/lang/System
#20 = NameAndType #29:#30 // out:Ljava/io/PrintStream;
#21 = Utf8 Hello syncsTask
#22 = Class #31 // java/io/PrintStream
#23 = NameAndType #32:#33 // println:(Ljava/lang/String;)V
#24 = Utf8 Hello syncTask
#25 = Utf8 com/example/demo/thread/SyncBlockAndMethod
#26 = Utf8 java/lang/Object
#27 = Utf8 java/lang/Throwable
#28 = Utf8 java/lang/System
#29 = Utf8 out
#30 = Utf8 Ljava/io/PrintStream;
#31 = Utf8 java/io/PrintStream
#32 = Utf8 println
#33 = Utf8 (Ljava/lang/String;)V
{
public com.example.demo.thread.SyncBlockAndMethod();
descriptor: ()V
flags: (0x0001) ACC_PUBLIC
Code:
stack=1, locals=1, args_size=1
0: aload_0
1: invokespecial #1 // Method java/lang/Object."":()V
4: return
LineNumberTable:
line 7: 0
public void syncsTask();
descriptor: ()V
flags: (0x0001) ACC_PUBLIC
Code:
stack=2, locals=3, args_size=1
0: aload_0
1: dup
2: astore_1
3: monitorenter // 指向同步代码块的开始位置
4: getstatic #2 // Field java/lang/System.out:Ljava/io/PrintStream;
7: ldc #3 // String Hello syncsTask
9: invokevirtual #4 // Method java/io/PrintStream.println:(Ljava/lang/String;)V
12: aload_1
13: monitorexit // 指向同步代码块的结束位置,monitorenter和monitorexit之间就是同步代码块
14: goto 22
17: astore_2
18: aload_1
19: monitorexit // 若代码发生异常时就会执行这句指令释放锁
20: aload_2
21: athrow
22: return
Exception table:
from to target type
4 14 17 any
17 20 17 any
LineNumberTable:
line 10: 0
line 11: 4
line 12: 12
line 13: 22
StackMapTable: number_of_entries = 2
frame_type = 255 /* full_frame */
offset_delta = 17
locals = [ class com/example/demo/thread/SyncBlockAndMethod, class java/lang/Object ]
stack = [ class java/lang/Throwable ]
frame_type = 250 /* chop */
offset_delta = 4
public synchronized void syncTask();
descriptor: ()V
flags: (0x0021) ACC_PUBLIC, ACC_SYNCHRONIZED // 用于标识是一个同步方法,不需要像同步块那样需要通过显式的字节码指令去标识哪里需要获取锁,哪里需要释放锁。同步方法无论是正常执行还是发生异常都会释放锁
Code:
stack=2, locals=1, args_size=1
0: getstatic #2 // Field java/lang/System.out:Ljava/io/PrintStream;
3: ldc #5 // String Hello syncTask
5: invokevirtual #4 // Method java/io/PrintStream.println:(Ljava/lang/String;)V
8: return
LineNumberTable:
line 16: 0
line 17: 8
}
SourceFile: "SyncBlockAndMethod.java" 什么是重入:
从互斥锁的设计上来说,当一个线程试图操作一个由其他线程持有的对象锁的临界资源时,将会处于阻塞状态,但当一个线程再次请求自己持有对象锁的临界资源时,这种情况属于重入
为什么会对synchronized嗤之以鼻:
- 在早期版本中,synchronized属于重量级锁效率低下,因为依赖于Mutex Lock实现,因为线程之间的切换需要从用户态转换到核心态,开销较大。不过在Java6以后引入了许多锁优化机制,synchronized性能已经得到了很大的提升
锁优化之自旋锁:
许多情况下,共享数据的锁定状态持续时间较短,切换线程不值得。于是自旋锁应运而生,所谓自旋就是通过让线程执行忙循环等待锁的释放,从而不让出CPU时间片,例如while某个标识变量
缺点:若锁被其他线程长时间占用,将会带来许多性能上的开销,所以一般超过指定的自旋次数就会将线程挂起处于阻塞状态
锁优化之自适应自旋锁:
自适应自旋锁与普通自旋锁不同的就是可以自适应自旋次数,即自旋次数不再固定。而是由前一次在同一个锁上的自旋时间及锁的拥有者的状态来决定
锁优化之锁消除,锁消除是JVM另一种锁优化,这种优化更彻底:
在JIT编译时,对运行上下文进行扫描,去除不可能存在资源竞争的锁。这种方式可以消除不必要的锁,可以减少毫无意义的请求锁时间
关于锁消除,我们可以看一个例子,代码如下:
public class StringBufferWithoutSync {
public void add(String str1, String str2) {
//StringBuffer是线程安全,由于sb只会在append方法中使用,不可能被其他线程引用
//因此sb属于不可能共享的资源,JVM会自动消除内部的锁
StringBuffer sb = new StringBuffer();
sb.append(str1).append(str2);
}
public static void main(String[] args) {
StringBufferWithoutSync withoutSync = new StringBufferWithoutSync();
for (int i = 0; i < 1000; i++) {
withoutSync.add("aaa", "bbb");
}
}
}锁优化之锁粗化,我们再来了解锁粗化的概念,有些情况下可能会需要频繁且重复进行加锁和解锁操作,例如同步代码写在循环语句里,此时JVM会有锁粗化的机制,即通过扩大加锁的范围,以避免反复加锁和解锁操作。代码示例:
public class CoarseSync {
public static String copyString100Times(String target){
int i = 0;
// JVM会将锁粗化到外部,使得重复的加解锁操作只需要进行一次
StringBuffer sb = new StringBuffer();
while (i < 100){
sb.append(target);
}
return sb.toString();
}
}synchronized锁存在四种状态:
- 无锁、偏向锁、轻量级锁、重量级锁
- 锁膨胀的方向:无锁 -> 偏向锁 -> 轻量级锁 -> 重量级锁
- 锁膨胀存在跨级现象,例如直接从无锁膨胀到重量级锁
偏向锁:
大多数情况下,锁不存在多线程竞争,总是由同一线程多次获得,为了减少同一线程获取锁的代价,就会使用偏向锁
核心思想:
如果一个线程获得了锁,那么锁就进入偏向模式,此时Mark Word的结构也变为偏向锁结构,当该线程再次请求锁时,无需再做任何同步操作,即获取锁的过程只需要检查Mark Word的锁标记位为偏向锁以及当前线程id等于Mark Word的ThreadID即可,这样就省去了大量有关锁申请的操作,那么这个锁也就偏向于该线程了偏向锁不适用于锁竞争比较激烈的多线程场合
轻量级锁:
轻量级锁是由偏向锁升级而来,偏向锁运行在一个线程进入同步块的情况下,当有第二个线程加入锁竞争时,偏向锁就会升级为轻量级锁
适用场景:线程交替执行同步块
若存在线程同一时间访问同一锁的情况,就会导致轻量级锁膨胀为重量级锁
轻量级锁的加锁过程:
-
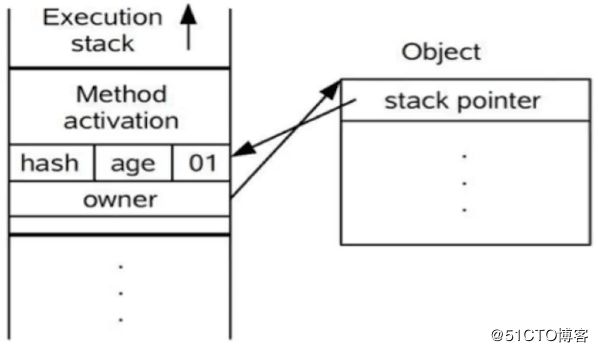
在代码进入同步块的时候,如果同步对象锁状态为无锁状态(锁标志位为“01”状态),虚拟机首先将在当前线程的栈帧中建立一个名为锁记录(LockRecord)的空间,用于存储锁对象目前的Mark Word的拷贝,官方称之为Displaced Mark Word。这时候线程堆栈与对象头的状态如下图所示:

- 拷贝对象头中的Mark Word复制到锁记录中
- 拷贝成功后,虚拟机将使用CAS操作尝试将对象的Mark Word更新为指向Lock Record的指针,并将Lock record里的owner指针指向object mark word。如果更新成功,则执行步骤4,否则执行步骤5
-
如果这个更新动作成功了,那么这个线程就拥有了该对象的锁,并且对象Mark Word的锁标志位设置为“00",即表示此对象处于轻量级锁定状态,这时候线程堆栈与对象头的状态如下图所示:
- 如果这个更新操作失败了,虚拟机首先会检查对象的Mark Word是否指向当前线程的栈帧,如果是就说明当前线程已经拥有了这个对象的锁,那就可以直接进入同步块继续执行。否则说明多个线程竞争锁,轻量级锁就要膨胀为重量级锁,锁标志的状态值变为“10",Mark Word中存储的就是指向重量级锁(互斥量)的指针,后面等待锁的线程也要进入阻塞状态。而当前线程便尝试使用自旋来获取锁,自旋咱们前面讲过,就是为了不让线程阻塞,而采用循环去获取锁的过程
轻量级锁的解锁过程:
- 通过CAS操作尝试把线程中复制的Displaced Mark Word对象替换当前的Mark Word
- 如果替换成功,整个同步过程就完成了
- 如果替换失败,说明有其他线程尝试过获取该锁(此时锁己膨胀),那就要在释放锁的同时,唤醒被挂起的线程
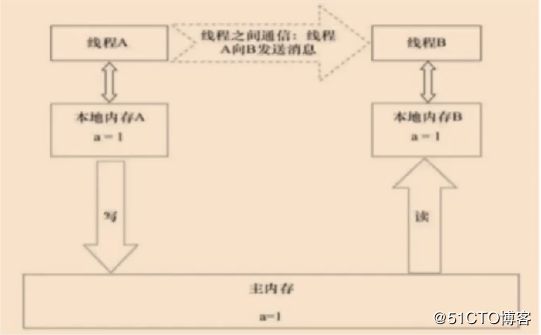
锁的内存语义:
当线程释放锁时,Java内存模型会把该线程对应的本地内存中的共享变量刷新到主内存中;而当线程获取锁时,Java内存模型会把该线程对应的本地内存置为无效,从而使得被监视器保护的临界区代码必须从主内存中读取共享变量
偏向锁、轻量级锁、重量级锁的汇总:
synchronized和ReentrantLock的区别
在JDK1.5之前,synchronized是Java唯一的同步手段,而在1.5之后则有了ReentrantLock类(重入锁):
- 位于java.util.concurrent.locks包
- 和CountDownLatch、FuturaTask、Semaphore一样基于AQS框架实现
- 能够实现比synchronized更细粒度的控制,如控制fairness
- 调用lock之后,必须调用unlock释放锁
- 在JDK6之后性能未必比synchronized高,并且也是可重入的
ReentrantLock公平性的设置:
ReentrantLock fairLock = new ReentrantLock(true);- 参数为true时,倾向于将锁赋予等待时间最久的线程,即设置为所谓的公平锁,公平性是减少线程饥饿的一个办法
- 公平锁:获取锁的顺序按先后调用lock方法的顺序,公平锁需慎用,因为会影响性能
- 非公平锁:线程抢占锁的顺序不一定,与调用顺序无关,看运气
- synchronized是非公平锁
ReentrantLock的好处在于将锁对象化了,因此可以实现synchronized难以实现的逻辑,例如:
- 判断是否有线程,或者某个特定线程,在排队等待获取锁
- 带超时的获取锁的尝试
- 感知有没有成功获取锁
如果说ReentrantLock将synchronized转变为了可控的对象,那么是否能将wait、notify及notifyall等方法对象化,答案是有的,即Condition:
- 位于java.util.concurrent.locks包
- 可以通过ReentrantLock的newCondition方法获取该Condition对象实例
synchronized和ReentrantLock的区别:
- synchronized是关键字,ReentrantLock是类
- ReentrantLock可以对获取锁的等待时间进行设置,避免死锁
- ReentrantLock可以获取各种锁的信息
- ReentrantLock可以灵活地实现多路通知
- 内部机制:synchronized操作的是Mark Word,而ReentrantLock底层是调用Unsafe类的park方法来加锁
jmm的内存可见性
Java内存模型(JMM):
Java内存模型(Java Memory Model,简称JMM)本身是一种抽象的概念,并不真实存在,它描述的是一组规则或规范,通过这组规范定义了程序中各个变量(包括实例字段,静态字段和构成数组对象的元素)的访问方式
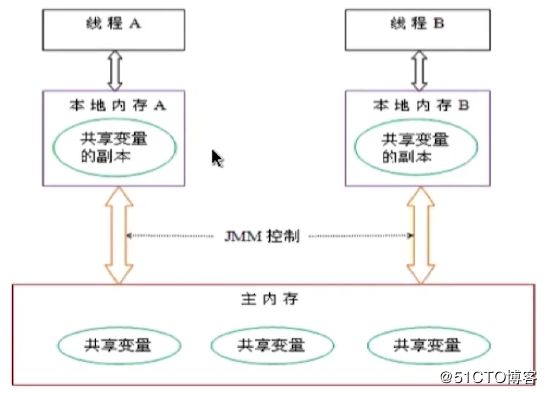
JMM中的主内存(即堆空间):
- 存储Java实例对象
- 包括成员变量、类信息、常量、静态变量等
- 属于数据共享的区域,多线程并发操作时会引发线程安全问题
JMM中的工作内存(即本地内存,或线程栈):
- 存储当前方法的所有本地变量信息,本地变量对其他线程不可见
- 字节码行号指示器、Native方法信息
- 属于线程私有数据区域,不存在线程安全问题
JMM与Java内存区域划分(即Java内存结构)是不同的概念层次:
- JMM描述的是一组规则,通过这组控制程序中各个变量在共享数据区域和私有数据区域的访问方式,JMM是围绕原子性、有序性及可见性展开的
- 两者相似点:存在共享数据区域和私有数据区域
主内存与工作内存的数据存储类型以及操作方式归纳:
- 方法里的基本数据类型本地变量将直接存储在工作内存的栈帧结构中
- 引用类型的本地变量,则是其引用存储在工作内存中,而具体的实例存储在主内存中
- 对象的成员变量、static变量、类信息均会被存储在主内存中
- 主内存共享的方式是线程各拷贝一份数据到工作内存,操作完成后刷新回主内存
JMM如何解决可见性问题: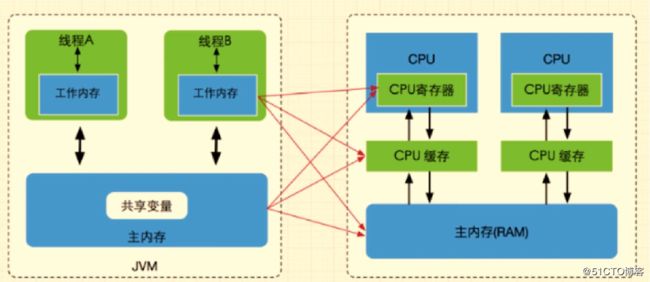
指令重排序需要满足的条件:
- 在单线程环境下不能改变程序运行的结果
- 存在数据依赖关系的不允许重排序
- 以上两点可以归结为:无法通过happens-before原则推导出来的,才能进行指令的重排序
什么是Java内存模型中的happens-before:
- 如果两个操作不满足下述任意一个happens-before原则,那么这两个操作就没有顺序的保障,JVM可以对这两个操作进行重排序
- 如果操作A happens-before 操作B,那么操作A在内存上所做的操作对操作B都是可见的
- 若A操作的结果需要对B操作可见,则A与B存在happens-before关系
happens-before的八大原则:
- 程序次序规则:一个线程内,按照代码顺序,书写在前面的操作先行发生于书写在后面的操作
- 锁定规则:一个unLock操作先行发生于后面对同一个锁的lock操作
- volatile变量规则:对一个变量的写操作先行发生于后面对这个变量的读操作(保证了可见性)
- 传递规则:如果操作A先行发生于操作B,而操作B又先行发生于操作C,则可以得出操作A先行发生于操作C
- 线程启动规则:Thread对象的start()方法先行发生于此线程的每一个动作
- 线程中断规则:对线程interrupt()方法的调用先行发生于被中断线程的代码检测到中断事件的发生
- 线程终结规则:线程中所有的操作都先行发生于线程的终止检测,我们可以通过Thread.join()方法结束、Thread.isAlive()的返回值手段检测到线程已经终止执行
- 对象终结规则:一个对象的初始化完成先行发生于他的finalize()方法的开始
volatile:
- 是JVM提供的轻量级同步机制
- JVM保证被volatile修饰的共享变量对所有线程总是可见的
- 禁止指令的重排序优化
- 使用volatile不能保证线程安全,需要变量的操作满足原子性
volatile变量为何立即可见?简单来说:
- 当写一个volatile变量时,JMM会把该线程对应的工作内存中的共享变量值刷新到主内存中
- 当读取一个volatile变量时,JMM会把该线程对应的工作内存置为无效,那么就需要从主内存中重新读取该变量
volatile变量如何禁止重排序优化:
- 对此我们需要先了解内存屏障(Memory Barrier),其作用有二:
- 保证特定操作的执行顺序
- 保证某些变量的内存可见性
- 通过插入内存屏障指令来禁止对内存屏障前后的指令执行重排序优化
- 强制刷出各种CPU的缓存数据,因此任何CPU上的线程都能读取到这些数据的最新版本
volatile和synchronized的区别:
- volatile本质是在告诉JVM当前变量在寄存器(工作内存)中的值是不确定的,需要从主存中读取;synchronized则是锁定当前变量,只有当前线程可以访问该变量,其他线程被阻塞住直到该线程完成变量操作为止
- volatile仅能使用在变量级别;synchronized则可以使用在变量、方法和类级别
- volatile仅能实现变量的修改可见性,不能保证原子性;而synchronized则可以保证变量修改的可见性和原子性
- volatile不会造成线程的阻塞;synchronized可能会造成线程的阻塞
- volatile标记的变量不会被编译器优化;synchronized标记的变量可以被编译器优化
CAS
CAS(Compare and Swap)是一种线程安全性的方法:
- 支持原子更新操作,适用于计数器,序列发生器等场景
- 属于乐观锁机制,号称lock-free
- CAS操作失败时由开发者决定是继续尝试,还是执行别的操作
CAS思想:
- 包含三个操作数:内存位置(V)、预期原值(A)和新值(B)
CAS多数情况下对开发者来说是透明的:
- J.U.C的atomic包提供了常用的原子性数据类型以及引用、数组等相关原子类型和更新操作工作,是很多线程安全程序的首选
- Unsafe类虽然提供CAS服务,但因能够操纵任意内存地址读写而有隐患
- Java9以后,可以使用Variable Handle API来代替Unsafe
缺点:
- 若循环时间长,则开销很大
- 只能保证一个共享变量的原子操作
- 存在ABA问题,可以通过使用AtomicStampedReference来解决,但由于是通过版本标记来解决所以存在一定程度的性能损耗
Java线程池
利用Executors创建不同的线程池满足不同场景的需求:
- newFixedThreadPool(int nThreads):指定工作线程数量的线程池
- newCachedThreadPool():处理大量短时间工作任务的线程池,特点:
- 试图缓存线程并重用,当无缓存线程可用时,就会创建新的工作线程
- 如果线程闲置的时间超过阈值,则会被终止并移出缓存
- 系统长时间闲置的时候,不会消耗什么资源
- newSingleThreadExecutor():创建唯一的工作者线程来执行任务,如果线程异常结束,会有另一个线程取代它
- newSingleThreadScheduledExecutor()与newScheduledThreadPool(int corePoolSize):定时或者周期性的工作调度,两者的区别在于单一工作线程还是多个线程
- JDK8新增的newWorkStealingPool():内部会构建ForkJoinPool ,利用working-stealing算法,并行地处理任务,不保证处理顺序
- working-stealing算法:某个线程从其他线程的任务队列里窃取任务来执行
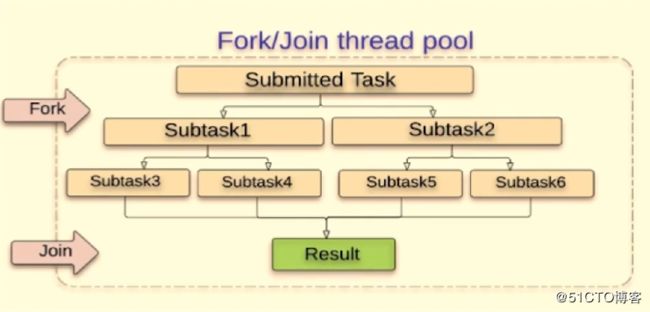
Fork/Join框架(JDK7提供):
- 是一个可以把大任务分割成若干个小任务并行执行,最终汇总每个小任务结果后得到大任务结果的框架
为什么要使用线程池:
- 减低资源消耗,避免频繁地创建和销毁线程
- 提高线程的可管理性,例如可控的线程数量,线程状态的监控和统一创建/销毁线程
Executor的框架: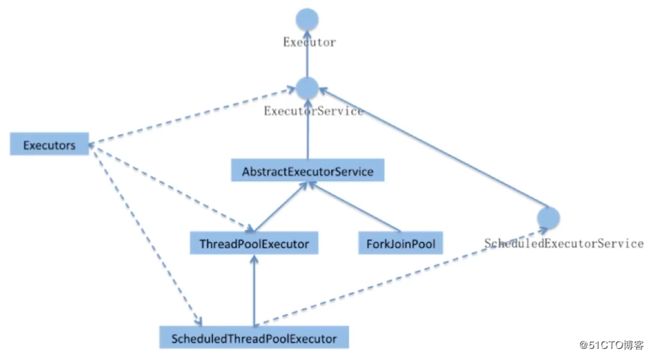
J.U.C的三个Executor接口:
- Executor:运行新任务的简单接口,将任务提交和任务执行细节解耦
- ExecutorService:具备管理执行器和任务生命周期的方法,提交任务机制更完善
- ScheduleExecutorService:支持Future和定期执行任务
线程池执行任务流程图: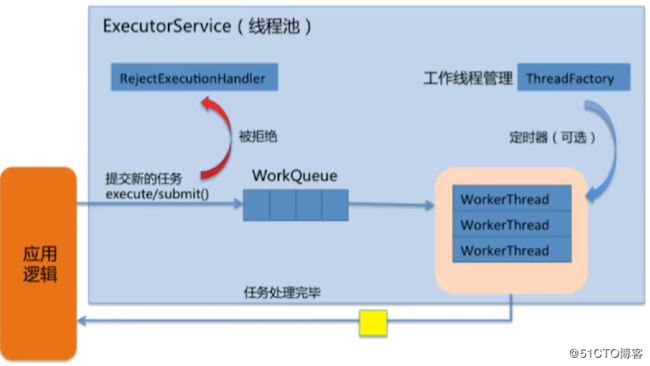
ThreadPoolExecutor的七个构造器参数:
int corePoolSize:核心线程数int maximumPoolSize:最大线程数long keepAliveTime:线程空闲存活时间TimeUnit unit:存活时间的单位BlockingQueue<Runnable> workQueue:任务等待队列ThreadFactory threadFactory:线程创建工厂,用于创建新线程RejectedExecutionHandler handler:任务拒绝策略- AbortPolicy:直接抛出异常,这是默认策略
- CallerRunsPolicy:使用调用者所在的线程来执行任务
- DiscardOldestPolicy:丢弃队列中最靠前的任务,并执行当前任务
- DiscardPolicy:直接丢弃提交的任务
- 另外可以实现RejectedExecutionHandler接口来自定义handler
新任务提交execute执行后的判断:
- 如果运行的线程少于corePoolSize ,则创建新线程来处理任务,即使线程池中的其他线程是空闲的;
- 如果线程池中的线程数量大于等于corePoolSize且小于maximumPoolSize,则只有当workQueue满时才创建新的线程去处理任务;
- 如果设置的corePoolSize和maximumPoolSize相同,则创建的线程池的大小是固定的,这时如果有新任务提交,若workQueue未满,则将请求放入workQueue中,等待有空闲的线程去从workQueue中取任务并处理;
- 如果运行的线程数量大于等于maximumPoolSize,这时如果workQueue已经满了,则通过handler所指定的策略来处理任务;
execute执行流程图: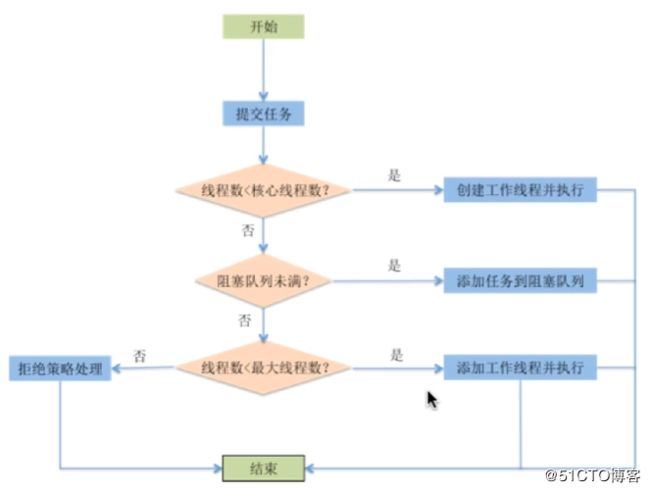
线程池的状态:
- RUNNING:能接受新提交的任务,并且也能处理阻塞队列中的任务
- SHUTDOWN:不再接受新提交的任务,但可以处理存量任务(调用shutdown方法)
- STOP:不再接受新提交的任务,也不处理存量任务(调用shutdownNow方法)
- TIDYING:所有的任务都已终止
- TERMINATED:terminated() 方法执行完后进入该状态
线程池状态转换图: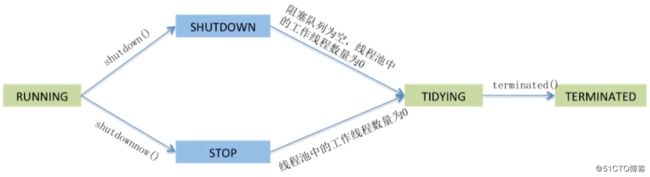
线程池中工作线程的生命周期: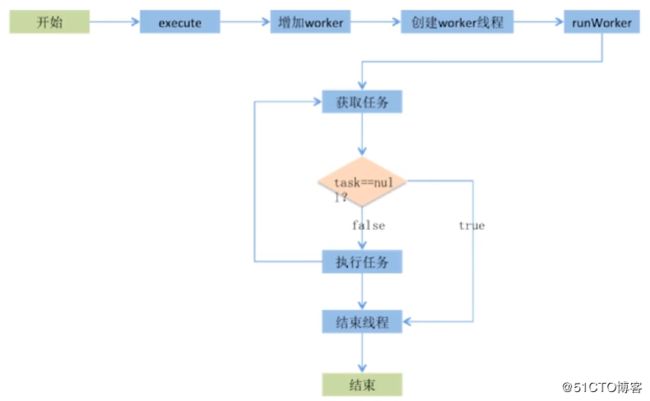
关于线程池大小如何选定参考:
- CPU密集型任务:线程数 = 按照CPU核心数或者CPU核心数 + 1设定
- I/O密集型任务:线程数 = CPU核心数 * (1 + 平均等待时间 / 平均工作时间)