我最近在学习python爬虫,然后正好碰上数据库课设,我就选了一个连锁药店的,所以就把网上的药品信息爬取了下来。
1,首先分析网页
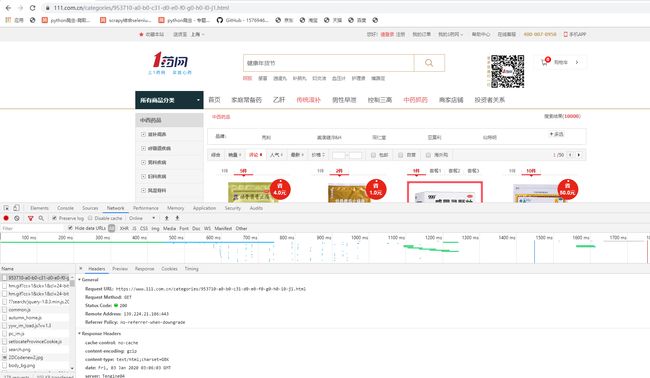
2,我想要的是评论数比较多的,毕竟好东西大概是买的人多才好。然后你会发现它的url地址是有规律的里面的j1是指第一页,j2第二页,这样构建一个url_list。
1 url_list = 'https://www.111.com.cn/categories/953710-a0-b0-c31-d0-e0-f0-g0-h0-i0-j%s.html'#然后循环获取响应 2 3 for i in range(1, 30): 4 5 response = requests.get(url_list % i, headers=headers)
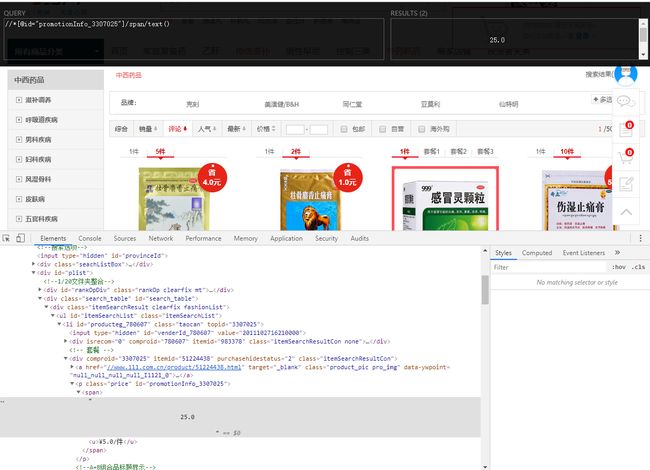
3,然后就可以进行数据的提取,我是利用Chrome的xpath插件,不过一定要注意有时候你复制的xpath不一定准确需要自己分析
我这里是演示提取价格,定位到价格选中后在Element里找到后点鼠标右键找到copy然后选择copy xpath,上面那个黑框就是xpath插件
4,连接数据库,我的数据库是mysql的
连接数据库的代码一般是这样
#!/usr/bin/python # -*- coding: UTF-8 -*- import MySQLdb # 打开数据库连接 db = MySQLdb.connect("localhost", "root", "123", "lianxi", charset='utf8' ) # 使用cursor()方法获取操作游标 cursor = db.cursor() # 如果数据表已经存在使用 execute() 方法删除表。 cursor.execute("DROP TABLE IF EXISTS EMPLOYEE") # 创建数据表SQL语句 sql = """CREATE TABLE EMPLOYEE ( FIRST_NAME CHAR(20) NOT NULL, LAST_NAME CHAR(20), AGE INT, SEX CHAR(1), INCOME FLOAT )DEFAULT CHARSET =utf8""" cursor.execute(sql) #!/usr/bin/python # -*- coding: UTF-8 -*- # 打开数据库连接 db = MySQLdb.connect("localhost", "root", "123", "lianxi", charset='utf8' ) # 使用cursor()方法获取操作游标 cursor = db.cursor() # SQL 插入语句 sql = """INSERT INTO EMPLOYEE(FIRST_NAME, LAST_NAME, AGE, SEX, INCOME) VALUES ('王', 'Mohan', 20, 'M', 2000)""" try: # 执行sql语句 cursor.execute(sql) # 提交到数据库执行 db.commit() except: # Rollback in case there is any error db.rollback() print("a") # 关闭数据库连接 db.close()
这个我是参照菜鸟教程的https://www.runoob.com/python/python-mysql.html
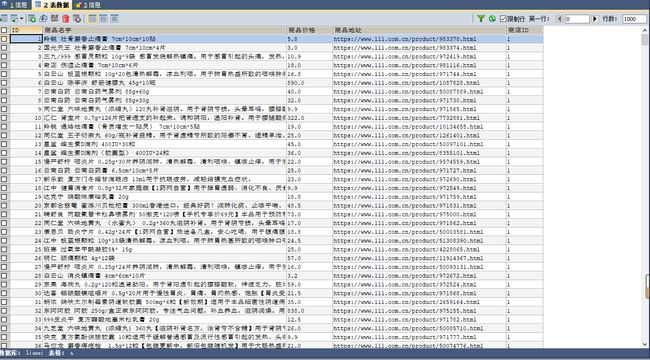
5,最后把源码附上,还有数据库里爬取的数据
import requests from lxml import etree import pymysql def get_text(text): if text: return text[0] return '' def create(): db = pymysql.connect("localhost", "root", "123", "lianxi",charset='utf8') # 连接数据库 cursor = db.cursor() cursor.execute("DROP TABLE IF EXISTS a") sql = """CREATE TABLE a ( ID INT PRIMARY KEY AUTO_INCREMENT, 药物名字 char (255), 药物价格 char (7), 药物网址 CHAR(255), 药店ID char (6) )DEFAULT CHARSET =utf8""" cursor.execute(sql) db.close() db = pymysql.connect("localhost", "root", "123", "lianxi",charset='utf8') cursor = db.cursor() url_list = 'https://www.111.com.cn/categories/953710-a0-b0-c31-d0-e0-f0-g0-h0-i0-j%s.html' headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.87 Safari/537.36"} for i in range(1, 30): response = requests.get(url_list % i, headers=headers) re=response.text content = etree.HTML(re) li_list = content.xpath('//ul[@id="itemSearchList"]/li') ##单价,描述,详情页链接 for li in li_list: # print(li) price = get_text(li.xpath( './/div[@isrecom="0"]/p[1]/textarea/span/text()|.//div[@isrecom="0"]/p[1]/span/text()|.//div[@isrecom="0"]/p[1]/span/u/text()')).strip() name = li.xpath('.//div[@isrecom="0"]/p[2]/a/text()')[1].strip() url = get_text(li.xpath('.//div[@class="itemSearchResultCon"]/a[1]/@href')).strip() infos = [] item = {} item['价格'] = price item['名字'] = name item['地址'] = 'https:' + url infos.append(item) print(item['价格']) print(item['地址']) print(item['名字']) a=1 insert_sql = 'INSERT INTO a (药物价格,药物名字,药物网址,药店ID) VALUES (%s,%s,%s,%s)' cursor.execute(insert_sql, (item['价格'],item['名字'] ,item['地址'],a)) try: db.commit() print('插入数据成功') except: db.rollback() print("插入数据失败") db.close() if __name__ == '__main__': create()
总结:第一次写博客,写的很粗糙,代码部分可能不是写的很美,毕竟我也是个小白,希望大家多多留言,提提意见,一同进步。