前言:
汇编语言是个直接操作CPU的语言,有些 app 开发里的非常重要的部分都用汇编开发,这就是所谓的内联汇编。能够使用内联汇编开发的都是让我膜拜的大神。
一. 8080地址寻址的相关知识
今天让我们来学习一下8086CPU的一些相关知识吧。
CPU访问内存单元的时候,要给出内存单元的地址。所有的内存单元都有一个唯一的地址,叫做物理地址。
8086 呢 是个很奇葩的 CPU ,它的地址总线有 20 根,,可以传送 20 位的地址,也就是 2^20 = 1M 的寻址能力。
但是呢,8086 又是 16 位结构的CPU,一次发电只能使用 16 根地址总线,所以它内部能够一次性处理,传输的暂时存储的地址为 16 位。
所以如果只是简单的将地址从内部发出到内存寻址,那么他就只能发出16位的地址表现出来的寻址能力只有 2^16 = 64K。1M的地址空间,最后只能 64K 寻址,那么就会造成很大的内存浪费。
所以 8086 通过地址加法器将两个 16 位地址相加进行地址合成 , 合成20位的物理地址,那么就能够访问所有的内存空间了,是不是很牛逼,哈哈。
如下图,地址加法器的相关流程:

地址合成
所以物理地址就通过 物理地址 = 段地址(基地址) * 16 + 偏移地址 的方式将段地址和偏移地址合成一个物理地址。
那么具体的相加就如同如下图一样的流程

-
观察一下下图的地址,看看有什么发现?
 地址
地址
没错,只要段地址和偏移地址相加的结果是相同的,那么就可以使用在范围内的不同的16位段地址和偏移地址进行相加。
比如:CPU要访问 21F60H 的物理地址,则给出的段地址 SA 和 偏移地址 EA 满足 SA*16+EA = 21F60H 即可。
内存分配管理
8086是用“基础地址(段地址×16) + 偏移地址 = 物理地址”的方式给出物理地址。
-
为了开发方便,我们可以采取分段的方法来管理内存,比如:
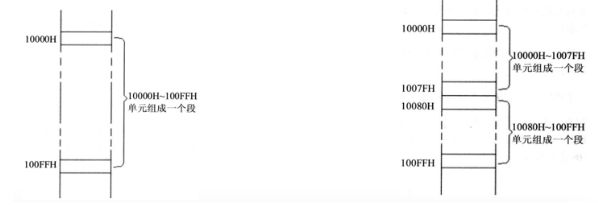 地址分段
地址分段- 地址10000H~100FFH的内存单元组成一个段,该段的起始地址(基础地址)为10000H,段地址为1000H,大小为100H
- 地址10000H1007FH、10080H100FFH的内存单元组成2个段,它们的起始地址(基础地址)为:10000H和10080H,段地址为1000H和1008H,大小都为80H
-
在编程时可以根据需要,将若干连续地址的内存单元看做一个段,用段地址×16定为段的起始地址(基础地址),用偏移地址定位段中的内存单元
- 段地址×16必然是16的倍数,所以一个段的起始地址(基础地址)也一定是16的倍数
- 偏移地址为16位,16位地址的寻址能力为64KB,所以一个段的长度最大为64KB
-
如果说给定一个段地址,只通过变化偏移地址来进行寻址,那么最多可以定位多少个内存单元呢?
- 结论 偏移地址16 位变化范围0~FFFFH,仅用偏移地址来寻址最多可寻 64K 的内存单位。
在8086PC机中,存储单元的地址用两个元素描述,即段地址和偏移地址。“数据在21F60H内存单元中”,这句话对于8086PC 一般不这样讲。取而代之的是两种类似的说法:a. 数据存储在 2000:1F60单元中。b:数据存储在内存的2000H段中的1F60H单元中。这两种都表示“数据在21F60H内存单元中”。