今晚又轮到我做报告了,在此记录一下发言稿。
作 者: 月牙眼的楼下小黑
联 系: zhanglf_tmac (Wechat)
声 明: 欢迎转载本文中的图片或文字,请说明出处

大家晚上好啊,我是研一的张立峰。
感谢小嫚和小强在前面的出色铺垫, 他们介绍了基于region-proposal (/prə'pəʊz(ə)l/)的4种经典强监督目标检测网络(R-CNN,SPP-Net, Fast-RCNN, Faster-RCNN)。小强挺好的,有自己的想法。

接下来我们上主菜,介绍一种基于 协同训练 的 弱监督 目标检测算法。所谓 “弱监督目标检测算法”,旨在实现这样一个任务: 我们只提供图像的类别标注(也称作 image-level /‘lev(ə)l/ annotation /ænə’teɪʃ(ə)n/),然后用这些弱标注的样本训练深度网络模型。训练完成后,给定待测试图像,输出以包围框(也即bounding box)为形式的预测结果。
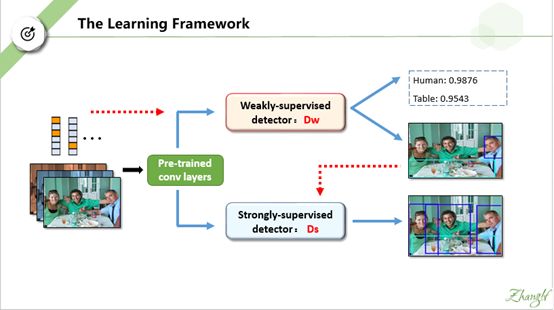
这是作者提出的整个网络框架。注意这张图不是作者的原图。作者的原图画得不够简洁清晰,这是我在原来基础上重新作图画的。为了更好的演示和讲解,我后面也做了很多图,“捏造了”很多假数据。但是我保证在誊写这些文字和制作图片时,已经尽可能地做到遵循文章原意。如果有疏漏和错误,请以原文为准。
网络的输入是一堆只带类别标签的图片。注意一张图片可以带多个 class-label。 一个label-vector可以有多个置 1 的位,我们用亮黄色表示。看第一张图片,我们可以把它标注为 {human , table}, 那么它的 lable-vector 就有两个高亮的位。
输入图片经过 pre-trained 的卷积网络提取特征后,分为上下支路。上支路为一个弱监督目标检测网络,用 Dw表示, 脚标w表示 “weakly”, 下支路为一个强监督目标检测网络,用Ds 表示, 脚标 s表示 “strongly” . 我们先暂时不管这两个网络的结构细节和训练方法,我后面会做详细讲解。
我们先看上支路 Dw 的输出是什么。首先它会输出对这幅图片的类别预测结果。请注意,是针对 整幅图片 (whole-iamge)的类别预测结果。因为这幅图片的真实标签是{人,桌子},如果网络训练得合适,在“ 人 ”和 “桌子 ”这两位上的值应该接近 1,我在 PPT中用 0.9876 和 0.9543 表示,这两个数据是我捏造的。
最骚的是,Dw 还会输出粗糙的目标检测结果,也即 bounding box –level 的预测结果。输出的每个bounding box 不仅有位置信息(矩形框左上角顶点坐标(x,y)以及 长(height)、宽(width)),也有类别信息(即 bounding box框住的内容属于各类的概率) 。
相信你们现在最大的疑问就是:Dw 是怎么仅仅根据image-level的 信息就能获得这两方面的预测输出呢?我们后面会详细解释。
既然 Dw已经输出了粗糙的目标检测结果,那么我们就可以把这些预测结果作为伪标签。此时图片就有了 bounding box –level的 标注信息。然后我们就可去 train 一个常见的强监督网络,比如 faster-rcnn. 强监督网络Ds只输出 bounding box-level 的预测结果,但是从图中我们可以看出,显然比 Dw的输出结果要好。
我们可以串行训练这两个网络,就是先单独训好 Dw, 获得伪标签(bounding box -level)后,再去train DS. 但是作者采用并行训练的方法: 在每一轮,Dw 和Ds相互协同,共同提高检测性能。
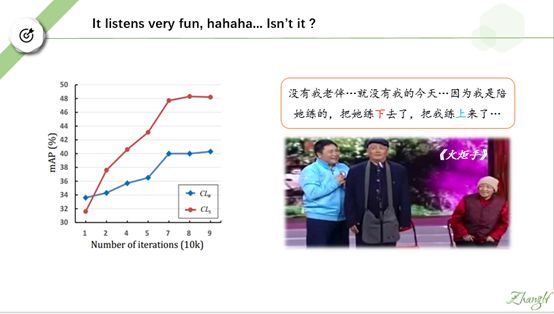
由图可以看出,在训练的初始阶段,弱监督检测网络(蓝线)准确率高于强监督检测网络(红线)。随着协同训练轮次的增多,两者的准确率均逐渐上升,但强监督检测网络提升的速度更快,并很快超越弱监督检测网络。
看到这一现象,我想起 2008 年的赵本山的小品《火炬手》。老太婆为当火炬手,又是练跑步又是练其他杂七杂八的,老头子是陪着练的,结果最后反而是他被选为火炬手。他的获选感言就很符合我们今天讲的这个现象。
他说:没有我老伴…就没有我的今天…因为我是陪她练的,把她练下去了,把我练上来了…
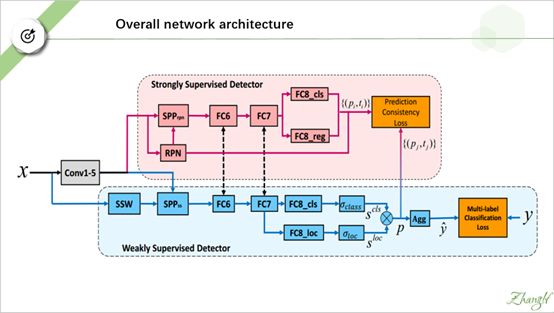
我们来看具体的网络结构。整个网络被分为两大块,上面的是强监督检测器 Ds,下面是弱监督检测器 Dw,还是挺复杂的,不要慌,我们一步步来拆解分析它。
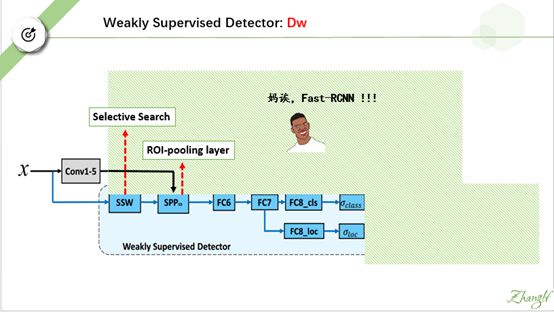
我们先分析弱监督检测器 Dw。 我们把强监督监督器 Ds 遮掉, 然后把 Dw的后端遮掉。(注意这里的SSW 是 selective search 的意思, SPP 是 ROI-pooling layer的意思。)
我们看看剩下的这个结构像什么?小嫚,你说说看。
对,它像fast-rcnn.但是它有一个地方跟 fast-rcnn 不一样。到底是哪里呢?
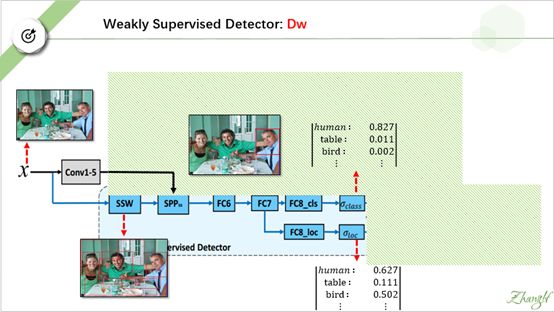
我们输入一张图片,SSW 产生大量 region proposal 。 对每一个region proposal, fast-rcnn 会输出类别预测和位置预测。比方说我们取右边这个包含衬衫男人的 proposal。
与fast-rcnn 一样,在第一个支路我们会输出这个proposal属于各个类别的概率,如它属于human 的 概率为0.827, 属于table的概率为0.011…..
Fast-rcnn 在第二个支路会输出这个region proposal 对应每一类 的更精确的位置预测。 如对 human,它会输出一个位置预测 pair: (x,y, w, h) , 对 table, 它也会输出一个位置预测 pair: (x’,y’,w’,h’ ).
这里就是我刚刚讲的不同了,我们的Dw不输出位置预测,而是输出类似 YOLO的位置置信度。
这里比较费解,我说一下自己的直观理解: 上支路是根据这个 region proposal 的 图片内容 预测出 这个region proposal 属于各个类的概率,下支路是根据 这个 region proposal的位置信息预测出这个region proposal属于各个类的概率。
好,接下来我们看看这个网络的后端部分。

后面是一个相乘操作。我们把这两个预测结果做同类项相乘。最终得到这个 region proposal属于每一个类的概率分数。
我们发现 human项的预测值最高,所以这个 region proposal 属于 human。 此时这个region proposal 就可以做为一个 bounding box –level的标注了。注意,在fast RCNN中,预测输出的 bounding box的位置和 region proposal 的位置是不一致的(原因如前所述,有一条支路会输出更精确的位置预测),而这里的bounging box的位置信息由region proposal 的 位置信息直接决定.它并没有做进一步的修正。

那么关键问题来了,我们如何去训练这个 Dw? 好,我们这个网络的最后端暴露出来。 这里 有一个 AGG 操作,还有 一个multi-lable classification loss,它们是什么意思呢?

这个AGG 操作十分简单,我们把所有region proposal的 类别预测结果相加,作为整张图片的类别预测结果,记为y’.
从直觉上来讲,y’ 和y (图片的真实类别标签)应该是接近的。
根据y’ 和y 我们定义二值交叉熵。如过了解过 逻辑回归,应该对二值交叉熵不陌生。 不了解也没关系,你们的峰哥哥在 PPT中举了一个例子,look !

好,我们前面已经分析完了Dw, 接下来我们分析强监督检测器 Ds。
同样地我们把另外一个检测器遮掉,并且把两者之间某些层与层的联系也先暂时抹掉。
这里的RPN 是 region proposal network 的意思。
现在应该很清晰了,我们看出来这个强监督分类器是什么了吗?小强,你说这个是什么?
对,它就是 Faster-RCNN.
我们可以像训练 faster RCNN 一样去train 这个网络,包括采用同样形式的 loss函数 啊,同样种类和大小的超参啊。
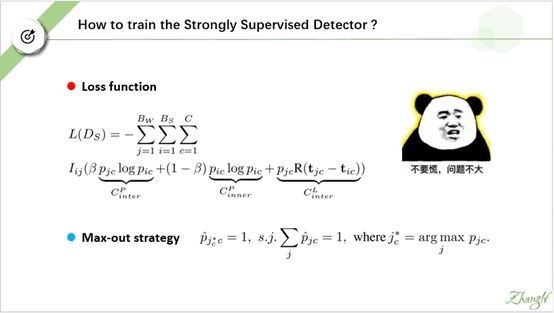
但是,作者采用了一个精心设计的 loss 函数, 以及使用了一种l类似于非极大值抑制的称为“ Max-out”的 trick.
这两个式子挺复杂。不要慌,我做了不少图来讲解这两步。希望你们认真听,我超级走心的。这个PPT我花了三天时间准备和制作(这次算快的了,第一次大例会我准备了两个星期)。

所谓max-out 就是这样一种策略:
假设 Dw 的输出为图中所示。图像的真实标签为 {人,桌子}。 OK, 我们只保留 在human 项上值最高的region proposal, 以及在 table项上值最高的 region proposal 。

所以最终我们只保留了两个最“confident "的 bounding box。 并且我们对这两个 bounding box 的类别预测做了修正。
包含人 的 box 在 human这一项的预测值最大化为 1; 同理,包含桌子的 box在 table 这一项的预测值最大化为 1 .
Dw的预测输出经过这样的滤除处理后,才做为 伪标签 馈入 强监督检测器中。

我们假设Dw 的预测输出如左图所示,pw 和 tw 分别为这个 bounding box 的类别信息和位置信息。 右侧为 Ds针对某一region proposal 做出的预测,ps 和ts分别为 类别预测结果 和 位置预测 结果。
根据faster-rcnn 的损失函数形式,我猜测Ds的损失函数应该长这个样子。第一项是交叉熵损失,惩罚类别预测误差。第二项是L1-损失函数,惩罚位置回归误差。两者用超参landa平衡。

但是事情不是我们想的那样,首先作者没有引入超参 landa, 然后他在损失函数后面加了一项函数熵,并且将新添项和第一项用超参β平衡。

作者设计的损失函数就如PPT 中所示。 为了更好地理解作者的意图,我把他设计的损失函数的前两项提取公因子,做了合并。合并后,我们再做仔细对比。我们圈出两者差异最大的部分。
我们把pw 视作训练 Ds时的 “ground truth” , 可是作者发现训练初期,pw噪声极大。Ds自己输出的预测 ps可能比 pw 还要靠谱。于是作者引入超参β, 其值越大, “ground truth”更倾向于相信Dw, 其值越小,就更倾向于相信Ds.
用简单的话来说,我们想用 Dw的预测输出指导 Ds的训练, 但是呢----- “我的Ds 可能有它自己的想法”

最后是层参数共享。作者提出,因为两个网络的任务相似,所以特征提取层和底端全连接层可以共享。Emmm…..符合直觉,而且这样做可以减少网络参数,减轻过拟合的影响。
网络按照这样的方式的训练:
两个检测器的独有层只根据各自损失函数的回传梯度更新参数
共享层则加和两个损失函数的回传梯度进行更新。

这是实验结果:
第一行是 Dw 单独训练的结果。
第三行是 Dw 和 Ds 串行训练后,Ds的检测结果
第二行和第四行是 Dw和 Ds 协同训练后各自的检测结果。
可以看到最后一行的检测结果是最好的。
然而。。。。

我们看一下具体指标。在两个经典数据集上达到的准确率才百分之四十左右,跟现在的强监督网络的性能相差甚远。
给人一种“一顿操作猛如虎,一看结果二百五”的感觉。但是相比其他弱监督方法,本文提出的方法还是非常 nice 的。

OK 谢谢大家,谢谢小嫚和小强。火箭总冠军。
