信息的表示
信息就是位+上下文,系统中的所有信息,包括磁盘文件,程序,存储器中数据以及网路传输的数据,都是一串位表示的.区分不同数据对象的唯一方法就是判断其上下文.
比如11011101这串二进制,可以表示221,在java的class文件里可能就代表一个JVM指令.
程序的编译
一个简单的C语言程序来说,一般要经过预处理器、编译器、汇编器和链接器的处理,才能被翻译成一段可执行的二进制文件。例如一段c语言helloworld程序.

程序的运行
hello.c已经被编译成可执行文件hello.如果在Unix系统中运行,需要一个叫sheel(外壳)的命令行解释器加载运行.
unix> ./hello
hello, world
unix>
-
系统硬件
我们首先需要了解系统的硬件.
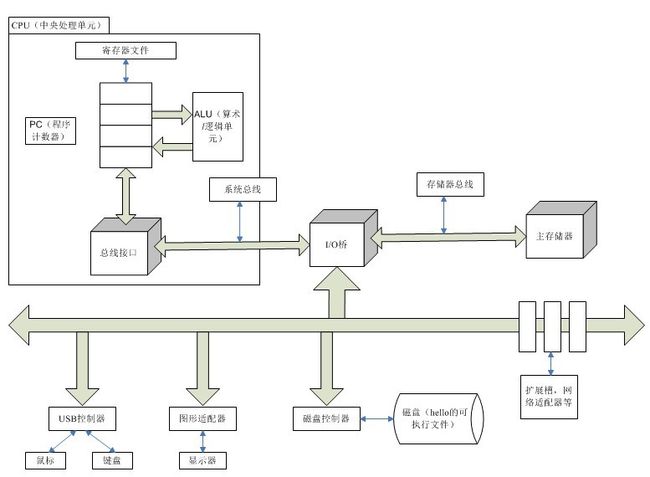
总线:贯穿整个系统的是一组电子管道,也就是总线。总线传送的是字,字中的字节数字长与系统相关,比如在32位操作系统当中,一个字是4个字节,而在64位则是8个字节。
I/O设备:I/O设备是系统与外部联系的通道.I/O设备(键盘、鼠标、显示器等)由控制器(USB控制器)或者适配器(图形适配器)与I/O总线相连,两者的区别在于一个是主板上的芯片组,一个是主板插槽上的卡。
主存:它是计算机中的一个临时存储设备,在处理器执行程序的时候,主存就是临时存放数据的地方。物理上来说,它是由动态随即存取存储器芯片DRAM组成,逻辑上来说,它是一组连续的字节数组,每一个字节都有唯一的地址,地址从0开始。
处理器:中央处理单元,是解释存储在主存中指令的引擎.处理器的核心是一个程序计数器(PC),它在整个计算机运行的期间都会指向一个主存中的一个内存地址,而地址当中则是一个计算机指令。处理器所做的,就是不停的执行程序计数器所指向的每一条指令。处理器所做的操作是围绕主存、寄存器文件以及算术/逻辑单元(ALU)进行的,这里面处理器做的最多的动作就是加载(从主存将数据复制到寄存器)、存储(从寄存器将数据复制到主存)、操作(将两个寄存器的内容复制到算术/逻辑单元进行操作,结果会再次复制到寄存器)以及跳转(改变程序计数器当中的内容)。
处理器当中提到的是指令集结构,不过实际当中指令集的实现是非常复杂的,这么做的目的是为了加速CPU的运算速度。我们可以这样去区分指令集机构以及微体系结构, 指令集结构是指令集的抽象描述,而微体系结构则是这个抽象描述的某一个具体实现,类似于JAVA虚拟机与JAVA虚拟机实现的关系。
-
运行过程
扫描:当我们在键盘输入./hello时,linux的外壳程序(也就是命令行)会扫描我们输入的字符,将这些字符读入到寄存器当中,然后再放入主存。换句话说,./hello这几个字符是经过了CPU中的寄存器从而到达了主存。

加载:好了外壳程序知道我们要执行hello这个程序了,开始加载,此过程会利用一种叫做存储器存取的技术,使得数据不通过寄存器直接到达主存
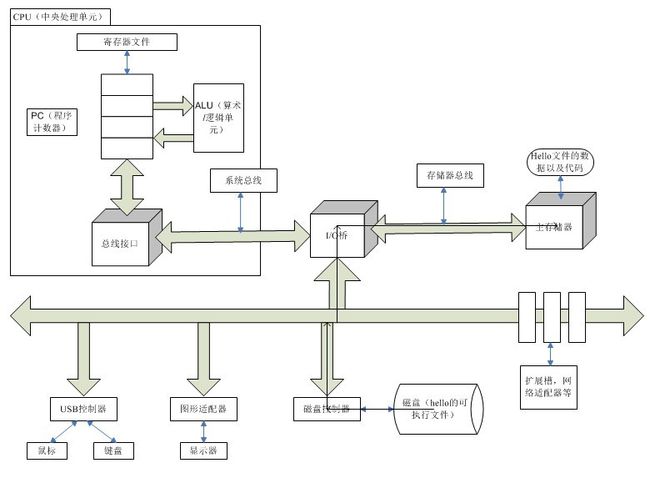
运行并输出:代码以及程序所需要的数据加载到主存后,CPU就开始从main函数的起始位置,依次执行程序中的机器语言指令。这些指令将"hello,world"这个字符串依次加载到寄存器,然后传输到显示器终端显示.
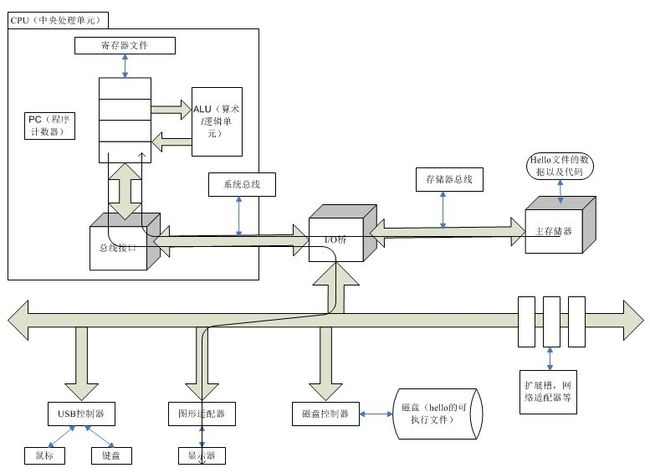
高速缓存
系统在数据的传输上花费了大量的时间。硬件开发商为了减少这种数据传输的时间成本,采用一种高速缓存的技术去减少这种时间成本.
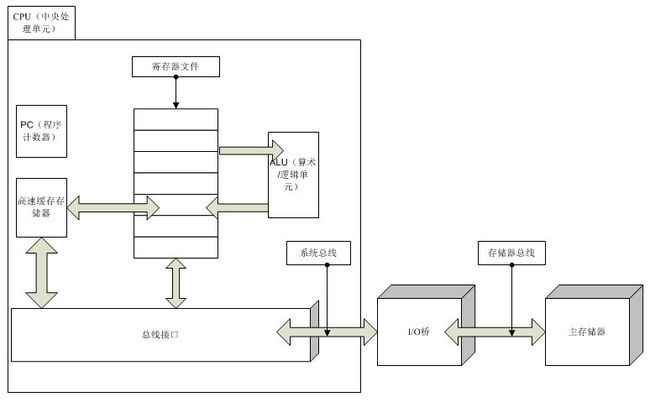
位于处理器芯片上的L1高速缓存速度和寄存器几乎一样,容量更大的L2告诉缓存则通过一条特殊总线连接到处理器,速度慢一些,但仍比主存快.它们采用静态随机访问存储器(SRAM)实现,有些系统甚至有L3告诉缓存.
设备层次
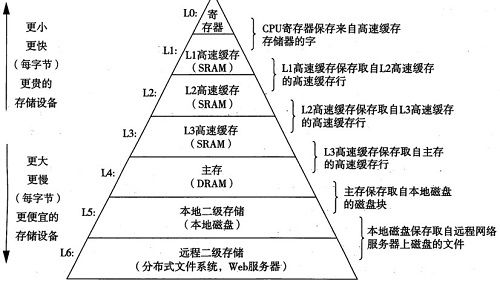
每一层上的存储器都可以作为低一层存储器的高速缓存.
进程与线程
进程是操作系统对一个正在运行的程序的抽象。并发运行,指的是进程交错执行.操作系统会记录每一个进程的状态,这些状态就称作进程的上下文。这些状态主要包括了PC,寄存器以及主存的当前内容。当操作系统在进程间切换的时候,也会切换相应的上下文,从而保证进程恢复到之前的状态.
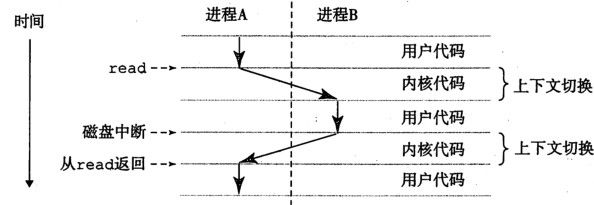
现代系统中,一个进程可以由多个称为 线程的执行单元组成,线程运行在进程的上下文,共享相同的代码和数据.由于共享数据更容易,所以线程更高效.
虚拟存储器
虚拟存储器是一种抽象概念,为每个进程提供了一个假象,即每个进程看到的都是一致的存储器.从物理上讲,它包含了I/O设备以及主存。在逻辑上讲,虚拟存储器被描述为虚拟地址空间.
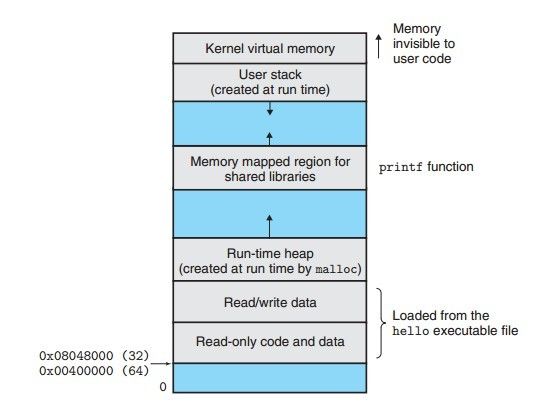
这里的地址自下向上依次增大,可以看出,图中标注了起始地址,分别为0x08048000(32位)以及0x00400000(64位),然后向上分别是 只读代码和数据、读写数据、运行时堆、共享库的内存映射区间、用户栈以及内核虚拟内存区域.
程序代码和数据:这些内容的起始地址就是0x08048000,首先是代码,然后是一些全局变量。
堆:是运行时可以动态扩展的一部分内存区域,它可以由malloc和free这样的标准库函数操作。
共享库:用于存放共享库的代码和数据。
栈:在用户虚拟地址空间的顶部是栈,这部分区域与函数的执行有密切的关系。
内核虚拟存储区域:内核是操作系统的一部分,内核也可以看做是一个进程,它在计算机运行期间总是在运行着,因此这部分内存区域对用户程序是不可见的,通俗的说就是不能用。
文件
文件是I/O设备逻辑上的概念,它其实就是字节序列,也就是1和0组成的一些信息。因此所有的I/O设备,包括磁盘、键盘、鼠标、显示器都可以看成是文件.系统中所有输入输出都是通过Unix I/O的系统函数调用读写文件实现.
网络
所有的I/O设备其实都是文件这一抽象概念的具体表现,那么网络其实也是文件的一种,因为说到底,它也可以被看做是一系列的字节序列。网络适配器的作用就是给计算机输入一堆被传送过来的字节序列,这里面可能包括图片、文字,甚至可能是代码等等.
并发与并行
书中的解释是并发是指一个同时具有多个活动的系统,而并行则是指的用并发使得一个系统运行的更快.实际上通俗来讲,在单cpu,并发是一种切换来切换去执行任务过程,而如果有多cpu,并行是真正可以同时执行不同任务的.
我们按照系统层次结构由高到低强调三个层次.
- 线程级并发:
在进程的抽象概念下引入了线程,而线程级并发的概念,就是指的多个线程在同一时间(并非是绝对同时的)活动。
操作系统从单处理器,直到现在多核多处理器系统,乃至超线程技术,已经经历了很大的变化。这也使得针对多线程编程变得更加重要,否则就无法利用多处理器带来的好处。
针对多处理器系统来说,比较好理解,其实就是物理上将多个CPU集中在一个集成电路的芯片上。而对于超线程技术来说,则是利用N个物理内核,模拟出2N个逻辑内核的技术。在硬件上来讲,超线程需要CPU的某些部分有多个备份,比如寄存器和程序计数器,但是其它部分只有一份,比如ALU. - 指令级并发
指令级并行的解释是,如果处理器可以同时执行多条指令,则称这种属性为指令级并行。其实指令级并行就是利用了指令的执行过程中会有不同的阶段,或者更精确的说,是在同一时间只会利用部分CPU的硬件,因此可以利用这一点做到多个指令并行执行。
更好的情况下,现代的很多处理器能够做到执行一条指令的平均时间尚且不到一个周期,这种处理器就称为超标量处理器。 - 单指令,多数据并行
单指令、多数据的概念是指一条指令可以产生多个并行执行的操作的方式。当今的一些处理器中配备了特殊的硬件,可以达到这个效果。由于产生了多个并行执行的操作,因此就会涉及到多个数据,通俗的讲也可以理解为,一条指令操作多个数据。比如书中所提到的例子,一些处理器具有并行地对4对单精度浮点数做加法的指令.
层次结构从高到低,从并发到并行,区别应该很明显了.
抽象
抽象的重要性就不需要再强调了,它在计算机科学领域有着不言而喻的地位。抽象可以使得一些具体的实现变的更加易于描述,而且也可以针对一些实现的方式作出规定.
计算机系统提供的一些抽象.
思考几个问题
先上一幅图再说,假设我们要对一些数字做相加运算,显然我们需要一个加法器,图中选取了全加器:
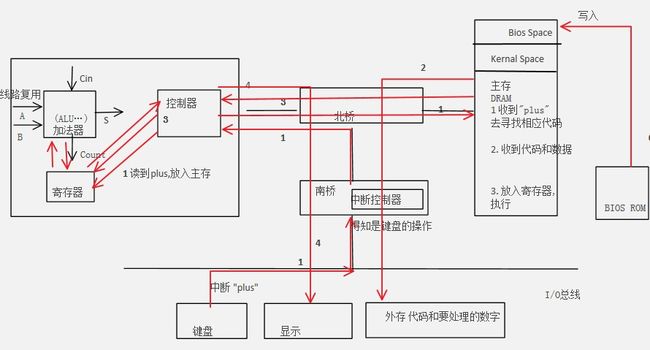
这幅图和前面书上的图类似,但是多添加了几点,需要考虑的地方
加电自检:首先操作系统是怎么运行起来的,通电时首先进行自检,通过post程序检查有没有哪里坏了,完了芯片bios上的rom写入到内存的特定区域,完了再另外一个单独区域(Kernal Space)加载内核系统,才能开始运作.
中断:我们想要通过键盘输入,那么系统怎么知道我们敲的是键盘呢?难道每时每刻保持监视键盘么?其实是我们敲键盘时候会给出一个中断,信号到南桥后,内部会集成一个可编程中断控制器,得知做出行为的是键盘.然后再到北桥,控制器等等...
二进制?:为什么计算机要用二进制?假设我们用八进制,那么我们也许需要八根线.因为元器件是通过电压来标识自身,那么可以设计类似1v,2v,..8v分别代表八进制的1,2..8.但是如果是小数怎么办?一个高精度小数,用电压来标识十分困难.而二进制异常简单,有电和没电就能标识1和0.
加法器:图上我们画的是全加器,它会由两个输入数字,一个输出和,一个输入低位,一个输出高位(注意这里的一根线可不代表实际上的一根线,一个数字用二进制表示意味着可能会需要多根线).看上去很不错,但是如果我们除了输入数字需要线以外,输入指令也需要线.那怎么样一根线才能又输入数据又可以输入指令呢.可以用线路复用,添加一个控制位,标识输入类型.
寄存器:要处理连续的运算,前面得出的结果要重新作为被加数,而后面的电压因为新数字的输入不断变化,那么前面的数存到哪里去?寄存器应运而生.
缓存:需要了解高度缓存出现的理由,cpu运算速度太快,而主存运算速度太慢,时间都被浪费了,才需要高速缓存.而之所以高速缓存有存在价值,在于程序局部性原理.这和 伸展树是很类似的嘛...

多任务:早期的系统是所谓单道批处理系统,也就是一次执行一个作业,然后一个接着一个直到完成.后来有了所谓多道批处理,也就是多任务了.那么考虑一个问题,不同的作业之间可能需要的内存也不一样,怎么分配呢,分配的话每次访问的地址怎么办,把前面的内存空间地址加进来?我们在对cpu进行时间切片的同时也会对内存进行切片(slice),地址则会重新编写各自内部的地址,如图中都是从101开始...
虚拟内存地址:前面说过,虚拟存储空间为让每个进程都看到一致的存储空间.试想一个问题,编程时候每个程序需要内存空间,但每台机器的各自不同,那怎么统一呢?为每台机器的内存容量分别编一个?这就用到虚拟内存地址了,32位的机器不管实际内存是多少,默认就是4g,64位同样.
系统层次:前面提过存储器层次,那么现在会有系统层次,底部自然是一堆硬件,其次我们需要内核(系统)对硬件进行管理,完了就是程序,程序可以对内核进行直接操作,称为系统调用但是这种程序编码十分复杂.而库则是进一层的封装,所以有更多的程序是调用库进行编写的.另外一个需要提的是,系统怎么知道用户对哪个程序进行了操作?这时候需要shell这种程序了,shell分为图形化(GUI)与命令行模式(CLI).
兼容性:显然对于兼容的库开发的程序在不同平台上也能运行,只要库一样.而如果程序是直接调用系统内核的,那么在不同系统由于硬件可能不兼容的问题,那么也许就没法运行了.这在另一方面也就是API(Application Programming Interface)和ABI(Application Binary Interface)比较大的区别,前者是定义了源代码和库之间的接口,后者则是描述了应用程序(或者其他类型)和内核之间的低级接口.