上一节中我们介绍了一个特殊的MDP模型:线性二次型调节控制(LQR)。事实上很多问题都可以用LQR来解决,即使动态模型是非线性的。尽管LQR是一个非常漂亮的解决方案,但它还不够通用。我们以倒摆(inverted pendulum)问题为例来引出这一节的主题。倒摆问题的状态转换过程为:

其中函数F取决于角度的余弦值,显然这是一个非线性函数。那么我们的问题是:如何将该系统线性化处理?
动态模型的线性化
假设在t时刻,系统大部分时间都处于状态s-t,并且采取的行动在a-t附近。对于倒摆问题来说,当系统到达最优解时,很显然系统采取的行动范围很小,且不会偏离竖直方向太远。
我们将会使用泰勒展开(Taylor expansion)的方法将动态模型线性化。先考虑一个简单的场景,当状态是一维的并且状态转换函数F与行动无关,我们可以得到:
更一般地,当F是关于状态和行动的函数时,我们有:

所以st + 1是关于st和at的线性函数,这是因为我们可以把上式改写成:
其中κ是一个常数,A和B是矩阵。这种形式和我们之前在LQR中做的假设非常相似。
微分动态规划
当我们的目标是停留在某个状态s*附近时,上面介绍的方法可以很有效地解决。然而在某些情况下,目标会变得更为复杂。
假设我们的目标是遵循某条轨迹(trajectory),那么就需要用到微分动态规划(Differential Dynamic Programming (DDP))的方法了。这个方法会将轨迹按照时间片进行离散化,并为每个时间片建立中间目标。DDP的主要步骤如下:
步骤1: 选定标称轨迹(nominal trajectory),这个是对我们想要追随的轨迹的近似。
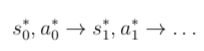
步骤2: 对每一个在s*t附近的轨迹线性化,即:

其中st和at是我们当前的状态和行动。既然我们现在有了当前点的线性近似,我们可以利用上一小节的结论将下一个状态改写成:
注意:我们也可以对奖励函数R(t)利用泰勒展开作类似的推导:

其中Hxy指的是R关于x和y在(st*, at*)处的Hessian矩阵。这个式子也可以被写成:
其中Ut和Wt是矩阵的形式。
步骤3: 现在我们证明了这个问题已经被转化成了LQR问题了,因此我们只需要用LQR的方法求解出最优策略πt。
步骤4: 现在我们有了最优策略πt,我们用它来产生新的轨迹:
注意当我们生成新的轨迹时,我们应该用F而不是近似函数来计算下一个状态,也就是说:
计算出下一个状态后,我们再回到步骤2,不断重复这几步,直到收敛到某个值结束。
总结
- LQR只适用于状态转换函数是线性的场景,当状态转换函数是非线性时,我们可以使用泰勒展开的方法做线性近似
- 当大部分状态和行动在某个小的局部范围内,我们可以选择局部中心做线性近似
- 当状态转换函数遵循某条轨迹时,可以使用微分动态规划(DDP)算法,其思想是在状态转换函数的多个点上依次做线性近似
参考资料
- 斯坦福大学机器学习课CS229讲义 LQR, DDP and LQG
- 网易公开课:机器学习课程 双语字幕视频