
本文首发在个人博客:http://muyunyun.cn/posts/7b9fdc87/
提到 Node.js, 我们脑海就会浮现异步、非阻塞、单线程等关键词,进一步我们还会想到 buffer、模块机制、事件循环、进程、V8、libuv 等知识点。本文起初旨在理顺 Node.js 以上易混淆概念,然而一入异步深似海,本文尝试基于 Node.js 的异步展开讨论,其他的主题只能日后慢慢补上了。(附:亦可以把本文当作是朴灵老师所著的《深入浅出 Node.js》一书的小结)。
异步 I/O
Node.js 正是依靠构建了一套完善的高性能异步 I/O 框架,从而打破了 JavaScript 在服务器端止步不前的局面。
异步 I/O VS 非阻塞 I/O
听起来异步和非阻塞,同步和阻塞是相互对应的,从实际效果而言,异步和非阻塞都达到了我们并行 I/O 的目的,但是从计算机内核 I/O 而言,异步/同步和阻塞/非阻塞实际上是两回事。
注意,操作系统内核对于 I/O 只有两种方式:阻塞与非阻塞。
调用阻塞 I/O 的过程:
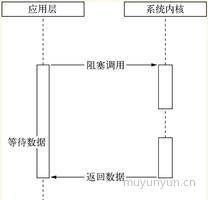
调用非阻塞 I/O 的过程:
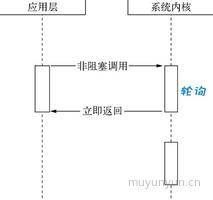
在此先引人一个叫作轮询的技术。轮询不同于回调,举个生活例子,你有事去隔壁寝室找同学,发现人不在,你怎么办呢?方法1,每隔几分钟再去趟隔壁寝室,看人在不;方法2,拜托与他同寝室的人,看到他回来时叫一下你;那么前者是轮询,后者是回调。
再回到主题,阻塞 I/O 造成 CPU 等待浪费,非阻塞 I/O 带来的麻烦却是需要轮询去确认是否完全完成数据获取。从操作系统的这个层面上看,对于应用程序而言,不管是阻塞 I/O 亦或是 非阻塞 I/O,它们都只能是一种同步,因为尽管使用了轮询技术,应用程序仍然需要等待 I/O 完全返回。
Node 的异步 I/O
完成整个异步 I/O 环节的有事件循环、观察者、请求对象以及 I/O 线程池。
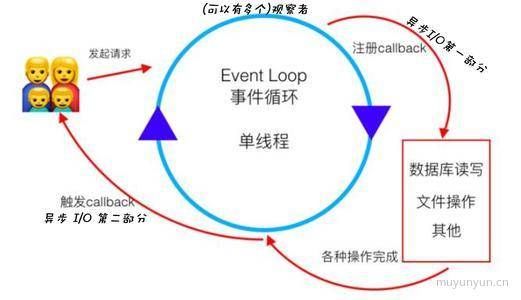
事件循环
在进程启动的时候,Node 会创建一个类似于 whlie(true) 的循环,每一次执行循环体的过程我们称为 Tick。
每个 Tick 的过程就是查看是否有事件待处理,如果有,就取出事件及其相关的回调函数。如果存在相关的回调函数,就执行他们。然后进入下一个循环,如果不再有事件处理,就退出进程。
伪代码如下:
while(ture) {
const event = eventQueue.pop()
if (event && event.handler) {
event.handler.execute() // execute the callback in Javascript thread
} else {
sleep() // sleep some time to release the CPU do other stuff
}
}观察者
每个 Tick 的过程中,如何判断是否有事件需要处理,这里就需要引入观察者这个概念。
每个事件循环中有一个或多个观察者,而判断是否有事件需要处理的过程就是向这些观察者询问是否有要处理的事件。
在 Node 中,事件主要来源于网络请求、文件 I/O 等,这些事件都有对应的观察者。
请求对象
对于 Node 中的异步 I/O 而言,回调函数不由开发者来调用,在 JavaScript 发起调用到内核执行完 id 操作的过渡过程中,存在一种中间产物,它叫作请求对象。
请求对象是异步 I/O 过程中的重要中间产物,所有状态都保存在这个对象中,包括送入线程池等待执行以及 I/O 操作完后的回调处理
以 fs.open() 为例:
fs.open = function(path, flags, mode, callback) {
bingding.open(
pathModule._makeLong(path),
stringToFlags(flags),
mode,
callback
)
}fs.open 的作用就是根据指定路径和参数去打开一个文件,从而得到一个文件描述符。
从前面的代码中可以看到,JavaScript 层面的代码通过调用 C++ 核心模块进行下层的操作。
从 JavaScript 调用 Node 的核心模块,核心模块调用 C++ 内建模块,内建模块通过 libuv 进行系统调用,这是 Node 里经典的调用方式。
libuv 作为封装层,有两个平台的实现,实质上是调用了 uv_fs_open 方法,在 uv_fs_open 的调用过程中,会创建一个 FSReqWrap 请求对象,从 JavaScript 层传入的参数和当前方法都被封装在这个请求对象中。回调函数则被设置在这个对象的 oncomplete_sym 属性上。
req_wrap -> object_ -> Set(oncomplete_sym, callback)对象包装完毕后,在 Windows 下,则调用 QueueUserWorkItem() 方法将这个 FSReqWrap 对象推人线程池中等待执行。
至此,JavaScript 调用立即返回,由 JavaScript 层面发起的异步调用的第一阶段就此结束(即上图所注释的异步 I/O 第一部分)。JavaScript 线程可以继续执行当前任务的后续操作,当前的 I/O 操作在线程池中等待执行,不管它是否阻塞 I/O,都不会影响到 JavaScript 线程的后续操作,如此达到了异步的目的。
执行回调
组装好请求对象、送入 I/O 线程池等待执行,实际上是完成了异步 I/O 的第一部分,回调通知是第二部分。
线程池中的 I/O 操作调用完毕之后,会将获取的结果储存在 req -> result 属性上,然后调用 PostQueuedCompletionStatus() 通知 IOCP,告知当前对象操作已经完成,并将线程归还线程池。
在这个过程中,我们动用了事件循环的 I/O 观察者,在每次 Tick 的执行过程中,它会调用 IOCP 相关的 GetQueuedCompletionStatus 方法检查线程池中是否有执行完的请求,如果存在,会将请求对象加入到 I/O 观察者的队列中,然后将其当做事件处理。
I/O 观察者回调函数的行为就是取出请求对象的 result 属性作为参数,取出 oncomplete_sym 属性作为方法,然后调用执行,以此达到调用 JavaScript 中传入的回调函数的目的。
小结
通过介绍完整个异步 I/O 后,有个需要重视的观点是 JavaScript 是单线程的,Node 本身其实是多线程的,只是 I/O 线程使用的 CPU 比较少;还有个重要的观点是,除了用户的代码无法并行执行外,所有的 I/O (磁盘 I/O 和网络 I/O) 则是可以并行起来的。
异步编程
Node 是首个将异步大规模带到应用层面的平台。通过上文所述我们了解了 Node 如何通过事件循环实现异步 I/O,有异步 I/O 必然存在异步编程。异步编程的路经历了太多坎坷,从回调函数、发布订阅模式、Promise 对象,到 generator、asycn/await。趁着异步编程这个主题刚好把它们串起来理理。
异步 VS 回调
对于刚接触异步的新人,很大几率会混淆回调 (callback) 和异步 (asynchronous) 的概念。先来看看维基的 Callback 条目:
In computer programming, a callback is any executable code that is passed as an argument to other code
因此,回调本质上是一种设计模式,并且 jQuery (包括其他框架)的设计原则遵循了这个模式。
在 JavaScript 中,回调函数具体的定义为:函数 A 作为参数(函数引用)传递到另一个函数 B 中,并且这个函数 B 执行函数 A。我们就说函数 A 叫做回调函数。如果没有名称(函数表达式),就叫做匿名回调函数。
因此 callback 不一定用于异步,一般同步(阻塞)的场景下也经常用到回调,比如要求执行某些操作后执行回调函数。讲了这么多让我们来看下同步回调和异步回调的例子:
同步回调:
function f2() {
console.log('f2 finished')
}
function f1(cb) {
cb()
console.log('f1 finished')
}
f1(f2) // 得到的结果是 f2 finished, f1 finished异步回调:
function f2() {
console.log('f2 finished')
}
function f1(cb) {
setTimeout(cb, 1000) // 通过 setTimeout() 来模拟耗时操作
console.log('f1 finished')
}
f1(f2) // 得到的结果是 f1 finished, f2 finished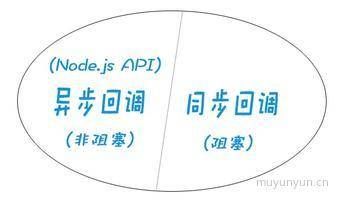
小结:回调可以进行同步也可以异步调用,但是 Node.js 提供的 API 大多都是异步回调的,比如 buffer、http、cluster 等模块。
发布/订阅模式
事件发布/订阅模式 (PubSub) 自身并无同步和异步调用的问题,但在 Node 的 events 模块的调用中多半伴随事件循环而异步触发的,所以我们说事件发布/订阅广泛应用于异步编程。它的应用非常广泛,可以在异步编程中帮助我们完成更松的解耦,甚至在 MVC、MVVC 的架构中以及设计模式中也少不了发布-订阅模式的参与。
以 jQuery 事件监听为例
$('#btn').on('myEvent', function(e) { // 订阅事件
console.log('I am an Event')
})
$('#btn').trigger('myEvent') // 触发事件可以看到,订阅事件就是一个高阶函数的应用。事件发布/订阅模式可以实现一个事件与多个回调函数的关联,这些回调函数又称为事件侦听器。下面我们来看看发布/订阅模式的简易实现。
var PubSub = function() {
this.handlers = {}
}
PubSub.prototype.subscribe = function(eventType, handler) { // 注册函数逻辑
if (!(eventType in this.handlers)) {
this.handlers[eventType] = []
}
this.handlers[eventType].push(handler) // 添加事件监听器
return this // 返回上下文环境以实现链式调用
}
PubSub.prototype.publish = function(eventType) { // 发布函数逻辑
var _args = Array.prototype.slice.call(arguments, 1)
for (var i = 0, _handlers = this.handlers[eventType]; i < _handlers.length; i++) { // 遍历事件监听器
_handlers[i].apply(this, _args) // 调用事件监听器
}
}
var event = new PubSub // 构造 PubSub 实例
event.subscribe('name', function(msg) {
console.log('my name is ' + msg) // my name is muyy
})
event.publish('name', 'muyy')至此,一个简易的订阅发布模式就实现了。然而发布/订阅模式也存在一些缺点,创建订阅本身会消耗一定的时间与内存,也许当你订阅一个消息之后,之后可能就不会发生。发布-订阅模式虽然它弱化了对象与对象之间的关系,但是如果过度使用,对象与对象的必要联系就会被深埋,会导致程序难以跟踪与维护。
Promise/Deferred 模式
想象一下,如果某个操作需要经过多个非阻塞的 IO 操作,每一个结果都是通过回调,程序有可能会看上去像这个样子。这样的代码很难维护。这样的情况更多的会发生在 server side 的情况下。代码片段如下:
operation1(function(err, result1) {
operation2(result1, function(err, result2) {
operation3(result2, function(err, result3) {
operation4(result3, function(err, result4) {
callback(result4) // do something useful
})
})
})
})这时候,Promise 出现了,其出现的目的就是为了解决所谓的回调地狱的问题。让我们看下使用 Promise 后的代码片段:
promise()
.then(operation1)
.then(operation2)
.then(operation3)
.then(operation4)
.then(function(value4) {
// Do something with value4
}, function (error) {
// Handle any error from step1 through step4
})
.done()可以看到,使用了第二种编程模式后能极大地提高我们的编程体验,接着就让我们自己动手实现一个支持序列执行的 Promise。(附:为了直观的在浏览器上也能感受到 Promise,为此也写了一段浏览器上的 Promise 用法示例)
在此之前,我们先要了解 Promise/A 提议中对单个异步操作所作的抽象定义,定义具体如下所示:
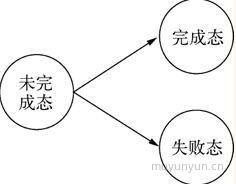
- Promise 操作只会处在 3 种状态的一种:未完成态、完成态和失败态。
- Promise 的状态只会出现从未完成态向完成态或失败态转化,不能逆反。完成态和失败态不能相互转化。
- Promise 的状态一旦转化,将不能被更改。
Promise 的状态转化示意图如下:
除此之外,Promise 对象的另一个关键就是需要具备 then() 方法,对于 then() 方法,有以下简单的要求:
- 接受完成态、错误态的回调方法。在操作完成或出现错误时,将会调用对应方法。
- 可选地支持 progress 事件回调作为第三个方法。
- then() 方法只接受 function 对象,其余对象将被忽略。
- then() 方法继续返回 Promise 对象,已实现链式调用。
then() 方法的定义如下:
then(fulfilledHandler, errorHandler, progressHandler)有了这些核心知识,接着进入 Promise/Deferred 核心代码环节:
var Promise = function() { // 构建 Promise 对象
// 队列用于存储执行的回调函数
this.queue = []
this.isPromise = true
}
Promise.prototype.then = function (fulfilledHandler, errorHandler, progressHandler) { // 构建 Progress 的 then 方法
var handler = {}
if (typeof fulfilledHandler === 'function') {
handler.fulfilled = fulfilledHandler
}
if (typeof errorHandler === 'function') {
handler.error = errorHandler
}
this.queue.push(handler)
return this
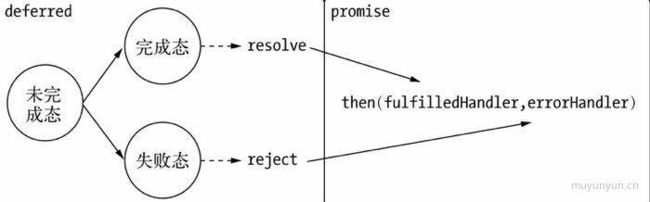
}如上 Promise 的代码就完成了,但是别忘了 Promise/Deferred 中的后者 Deferred,为了完成 Promise 的整个流程,我们还需要触发执行上述回调函数的地方,实现这些功能的对象就叫作 Deferred,即延迟对象。
Promise 和 Deferred 的整体关系如下图所示,从中可知,Deferred 主要用于内部来维护异步模型的状态;而 Promise 则作用于外部,通过 then() 方法暴露给外部以添加自定义逻辑。
接着来看 Deferred 代码部分的实现:
var Deferred = function() {
this.promise = new Promise()
}
// 完成态
Deferred.prototype.resolve = function(obj) {
var promise = this.promise
var handler
while(handler = promise.queue.shift()) {
if (handler && handler.fulfilled) {
var ret = handler.fulfilled(obj)
if (ret && ret.isPromise) { // 这一行以及后面3行的意思是:一旦检测到返回了新的 Promise 对象,停止执行,然后将当前 Deferred 对象的 promise 引用改变为新的 Promise 对象,并将队列中余下的回调转交给它
ret.queue = promise.queue
this.promise = ret
return
}
}
}
}
// 失败态
Deferred.prototype.reject = function(err) {
var promise = this.promise
var handler
while (handler = promise.queue.shift()) {
if (handler && handler.error) {
var ret = handler.error(err)
if (ret && ret.isPromise) {
ret.queue = promise.queue
this.promise = ret
return
}
}
}
}
// 生成回调函数
Deferred.prototype.callback = function() {
var that = this
return function(err, file) {
if(err) {
return that.reject(err)
}
that.resolve(file)
}
}接着我们以两次文件读取作为例子,来验证该设计的可行性。这里假设第二个文件读取依赖于第一个文件中的内容,相关代码如下:
var readFile1 = function(file, encoding) {
var deferred = new Deferred()
fs.readFile(file, encoding, deferred.callback())
return deferred.promise
}
var readFile2 = function(file, encoding) {
var deferred = new Deferred()
fs.readFile(file, encoding, deferred.callback())
return deferred.promise
}
readFile1('./file1.txt', 'utf8').then(function(file1) { // 这里通过 then 把两个回调存进队列中
return readFile2(file1, 'utf8')
}).then(function(file2) {
console.log(file2) // I am file2.
})最后可以看到控制台输出 I am file2,验证成功~,这个案例的完整代码可以点这里查看,并建议使用 node-inspector 进行断点观察,(这段代码里面有些逻辑确实很绕,通过断点调试就能较容易理解了)。
从 Promise 链式调用可以清晰地看到队列(先进先出)的知识,其有如下两个核心步骤:
- 将所有的回调都存到队列中;
- Promise 完成时,逐个执行回调,一旦检测到返回了新的 Promise 对象,停止执行,然后将当前 Deferred 对象的 promise 引用改变为新的 Promise 对象,并将队列中余下的回调转交给它;
至此,实现了 Promise/Deferred 的完整逻辑,Promise 的其他知识未来也会继续探究。
Generator
尽管 Promise 一定程度解决了回调地狱的问题,但是对于喜欢简洁的程序员来说,一大堆的模板代码 .then(data => {...}) 显得不是很友好。所以爱折腾的开发者们在 ES6 中引人了 Generator 这种数据类型。仍然以读取文件为例,先上一段非常简洁的 Generator + co 的代码:
co(function* () {
const file1 = yield readFile('./file1.txt')
const file2 = yield readFile('./file2.txt')
console.log(file1)
console.log(file2)
})可以看到比 Promise 的写法简洁了许多。后文会给出 co 库的实现原理。在此之前,先归纳下什么是 Generator。可以把 Generator 理解为一个可以遍历的状态机,调用 next 就可以切换到下一个状态,其最大特点就是可以交出函数的执行权(即暂停执行),让我们看如下代码:
function* gen(x) {
yield (function() {return 1})()
var y = yield x + 2
return y
}
// 调用方式一
var g = gen(1)
g.next() // { value: 1, done: false }
g.next() // { value: 3, done: false }
g.next() // { value: undefined, done: true }
// 调用方式二
var g = gen(1)
g.next() // { value: 1, done: false }
g.next() // { value: 3, done: false }
g.next(10) // { value: 10, done: true }由此我们归纳下 Generator 的基础知识:
- Generator 生成迭代器后,等待迭代器的
next()指令启动。 - 启动迭代器后,代码会运行到
yield处停止。并返回一个 {value: AnyType, done: Boolean} 对象,value 是这次执行的结果,done 是迭代是否结束。并等待下一次的 next() 指令。 - next() 再次启动,若 done 的属性不为 true,则可以继续从上一次停止的地方继续迭代。
- 一直重复 2,3 步骤,直到 done 为 true。
- 通过调用方式二,我们可看到 next 方法可以带一个参数,该参数就会被当作
上一个 yield 语句的返回值。
另外我们注意到,上述代码中的第一种调用方式中的 y 值是 undefined,如果我们真想拿到 y 值,就需要通过 g.next(); g.next().value 这种方式取出。可以看出,Generator 函数将异步操作表示得很简洁,但是流程管理却不方便。这时候用于 Generator 函数的自动执行的 co 函数库 登场了。为什么 co 可以自动执行 Generator 函数呢?我们知道,Generator 函数就是一个异步操作的容器。它的自动执行需要一种机制,当异步操作有了结果,能够自动交回执行权。
两种方法可以做到这一点:
- Thunk 函数。将异步操作包装成 Thunk 函数,在回调函数里面交回执行权。
- Promise 对象。将异步操作包装成 Promise 对象,用 then 方法交回执行权。
co 函数库其实就是将两种自动自动执行器(Thunk 函数和 Promise 对象),包装成一个库。使用 co 的前提条件是,Generator 函数的 yield 命令后面,只能是 Thunk 函数或者是 Promise 对象。下面分别用以上两种方法对 co 进行一个简单的实现。
基于 Thunk 函数的自动执行
在 JavaScript 中,Thunk 函数就是指将多参数函数替换成单参数的形式,并且其只接受回调函数作为参数的函数。Thunk 函数的例子如下:
// 正常版本的 readFile(多参数)
fs.readFile(filename, 'utf8', callback)
// Thunk 版本的 readFile(单参数)
function readFile(filename) {
return function(callback) {
fs.readFile(filename, 'utf8', callback);
};
}在基于 Thunk 函数和 Generator 的知识上,接着我们来看看 co 基于 Thunk 函数的实现。(附:代码参考自co最简版实现)
function co(generator) {
return function(fn) {
var gen = generator()
function next(err, result) {
if(err) {
return fn(err)
}
var step = gen.next(result)
if (!step.done) {
step.value(next) // 这里可以把它联想成递归;将异步操作包装成 Thunk 函数,在回调函数里面交回执行权。
} else {
fn(null, step.value)
}
}
next()
}
}用法如下:
co(function* () { // 把 function*() 作为参数 generator 传入 co 函数
var file1 = yield readFile('./file1.txt')
var file2 = yield readFile('./file2.txt')
console.log(file1) // I'm file1
console.log(file2) // I'm file2
return 'done'
})(function(err, result) { // 这部分的 function 作为 co 函数内的 fn 的实参传入
console.log(result) // done
})上述部分关键代码已进行注释,下面对 co 函数里的几个难点进行说明:
var step = gen.next(result), 前文提到的一句话在这里就很有用处了:next方法可以带一个参数,该参数就会被当作上一个yield语句的返回值;在上述代码的运行中一共会经过这个地方 3 次,result 的值第一次是空值,第二次是 file1.txt 的内容 I'm file1,第三次是 file2.txt 的内容 I'm file2。根据上述关键语句的提醒,所以第二次的内容会作为 file1 的值(当作上一个yield语句的返回值),同理第三次的内容会作为 file2 的值。- 另一处是
step.value(next), step.value 就是前面提到的 thunk 函数返回的 function(callback) {}, next 就是传入 thunk 函数的 callback。这句代码是条递归语句,是这个简易版 co 函数能自动调用 Generator 的关键语句。
建议亲自跑一遍代码,多打断点,从而更好地理解,代码已上传github。
基于 Promise 对象的自动执行
基于 Thunk 函数的自动执行中,yield 后面需跟上 Thunk 函数,在基于 Promise 对象的自动执行中,yield 后面自然要跟 Promise 对象了,让我们先构建一个 readFile 的
Promise 对象:
function readFile(fileName) {
return new Promise(function(resolve, reject) {
fs.readFile(fileName, function(error, data) {
if (error) reject(error)
resolve(data)
})
})
}在基于前文 Promise 对象和 Generator 的知识上,接着我们来看看 co 基于 Promise 函数的实现:
function co(generator) {
var gen = generator()
function next(data) {
var result = gen.next(data) // 同上,经历了 3 次,第一次是 undefined,第二次是 I'm file1,第三次是 I'm file2
if (result.done) return result.value
result.value.then(function(data) { // 将异步操作包装成 Promise 对象,用 then 方法交回执行权
next(data)
})
}
next()
}用法如下:
co(function* generator() {
var file1 = yield readFile('./file1.txt')
var file2 = yield readFile('./file2.txt')
console.log(file1.toString()) // I'm file1
console.log(file2.toString()) // I'm file2
})这一部分的代码上传在这里,通过观察可以发现基于 Thunk 函数和基于 Promise 对象的自动执行方案的 co 函数设计思路几乎一致,也因此呼应了它们共同的本质 —— 当异步操作有了结果,自动交回执行权。
async
看上去 Generator 已经足够好用了,但是使用 Generator 处理异步必须得依赖 tj/co,于是 asycn 出来了。本质上 async 函数就是 Generator 函数的语法糖,这样说是因为 async 函数的实现,就是将 Generator 函数和自动执行器,包装进一个函数中。伪代码如下,(注:其中 automatic 的实现可以参考 async 函数的含义和用法中的实现)
async function fn(args){
// ...
}
// 等同于
function fn(args) {
return automatic(function*() { // automatic 函数就是自动执行器,其的实现可以仿照 co 库自动运行方案来实现,这里就不展开了
// ...
})
}接着仍然以上文的读取文件为例,来比较 Generator 和 async 函数的写法差异:
// Generator
var genReadFile = co(function*() {
var file1 = yield readFile('./file1.txt')
var file2 = yield readFile('./file2.txt')
})
// 改用 async 函数
var asyncReadFile = async function() {
var file1 = await readFile('./file1.txt')
var file2 = await 1 // 等同于同步操作(如果跟上原始类型的值)
}总体来说 async/await 看上去和使用 co 库后的 generator 看上去很相似,不过相较于 Generator,可以看到 Async 函数更优秀的几点:
- 内置执行器。Generator 函数的执行必须依靠执行器,而 Aysnc 函数自带执行器,调用方式跟普通函数的调用一样;
- 更好的语义。async 和 await 相较于 * 和 yield 更加语义化;
- 更广的适用性。前文提到的 co 模块约定,yield 命令后面只能是 Thunk 函数或 Promise 对象,而 async 函数的 await 命令后面则可以是 Promise 或者原始类型的值;
- 返回值是 Promise。async 函数返回值是 Promise 对象,比 Generator 函数返回的 Iterator 对象方便,因此可以直接使用 then() 方法进行调用;
参考资料
- 深入浅出 Node.js
- 理解回调函数
- JavaScript之异步编程简述
- 理解co执行逻辑
- co 函数库的含义和用法
- async 函数的含义和用法