这篇文章讲解用于评估句子相似度的孪生LSTM深度神经网络
论文地址:Siamese Recurrent Architectures for Learning Sentence Similarity
Tensorflow 实现:GitHub - dhwajraj/deep-siamese-text-similarity: Tensorflow based implementation of deep siamese LSTM network to capture phrase/sentence similarity using character/word embeddings
Keras实现:[[NLP]基于Simaese LSTM的句子相似度计算 - CSDN博客
论文翻译
(本人水平有限,其中部分句子为谷歌翻译,不足之处敬请指出):
摘要
我们提出了一个可适应变长序列对组成的标记数据的孪生LSTM网络。我们的模型被用来评估句子之间的相似度,达到了 state of the art的程度, 效果胜过精心的手工特征和最近提出的更复杂的神经网络。对于这些应用,我们提供了向LSTMs补充同义信息的词嵌入向量,它使用固定大小的矢量来编码句子表达的基本含义(不论具体的措辞/句法)。通过限制后续操作依赖于简单的曼哈顿度量,我们强迫我们的模型学习的句子表示形成高度结构化的空间,其几何形状反映了复杂的语义关系。我们的研究成果是一系列研究结果中的最新成果,它展示了LSTM作为强大的语言模型能够完成需要复杂理解的任务。
简介
文本理解和信息检索是重要的任务,可以通过对句子/短语之间潜在的语义相似性进行建模而得到极大促进。特别地,一个好的模型不应该受到用于表达相同想法的措词/句法的变化的影响。因此学习这样的文本语义相似性度量产生了大量的研究兴趣(Marelli et al. 2014)。然而,这一直是一个难题,因为缺乏标注数据,句子长度不定而且结构复杂,并且在NLP中占统治地位的 词袋模型/TF-IDF模型受到它们固有的术语特异性(term-specificity)限制((c.f. Mihalcea, Corley, and Strapparava 2006)。
作为这些想法的替代方案,Mikolov等人(2013)和其他人已经证明了神经词表征在类比和其他NLP任务中的有效性。最近,兴趣已经转向将这些想法延伸到单个单词级以外的更大的文本体,例如句子,其中一个就是学习将句子表示为固定长度的向量(Kiros et al. 2015; Tai, Socher, and Manning 2015; Le and Mikolov 2014)。递归神经网络(RNN),天生地适用于像句子这样的可变长度输入,尤其是Hochreiter和Schmidhuber(1997)的长期短期记忆模型,被特别成功地用于文本分类(Graves 2012)和语言翻译(Sutskever,Vinyals和Le 2014)。RNN网络是标准前馈神经网络经过改造以适应序列数据,对于序列数据(x1,...,xT ),在每一个时间t∈ {1,...,T},隐藏藏状态向量
虽然Siegelmann and Sontag (1995)已经证明基本RNN图灵完备的,但是权重矩阵的优化是困难的,因为它的反向传播门在经过长序列之后会变得非常小。实际上,LSTM在学习long range dependencies方面比RNN要优秀,它的记忆单元可以保存/访问冗长输入序列的信息。与RNN类似,LSTM按顺序更新隐藏状态表示,但这些步骤也依赖于包含四个组件(实值矩阵)的记忆单元,四个组件:一个记忆状态ct, 一个输出门ot(决定记忆状态如何影响记忆单元),和一个基于每个输入和当前状态控制记忆内容和遗忘内容的输入(和遗忘)门 it(和ft)。下面是LSTM在每一个时刻t ∈ {1,...,T}的更新公式,参数是权重矩阵Wi, Wf , Wc, Wo, Ui, Uf , Uc, Uo 和偏置向量bi, bf , bc, bo:

对LSTM模型及变体更全面的阐述见Graves (2012) and Greff et al. (2015)的工作。
虽然LSTM语言模型的成功在现在并没有理论解释,但Sutskever,Vinyals和Le(2014)凭经验验证了一种直觉,即有效训练的网络将每个句子映射到一个固定长度的向量上,该向量编码文本中表达的基本含义。最近的工作已经提出了许多其他LSTM变体,例如Cho等的简单门循环单元(GRU) (2014)。经过广泛的实证分析后,Greff等人(2015年)质疑所提出的修改是否真正地超过了基本的LSTM模型。为了建模文本,大量的顺序RNN模型也被提出,包括双向 (Graves 2012),多层和递归树结构(Socher 2014)。
在这项工作中,我们发现,给定足够的数据,LSTM的简单变形可以通过配对示例进行训练,以学习能够捕捉丰富语义的高度结构化的句子表示空间。我们的结果与Sutskever,Vinyals和Le(2014)的语言翻译实验一样,表明标准LSTM可以很好地处理看起来复杂的NLP问题。尽管简单,我们的方法在评估句子相似度方面达到了比现有state of the art更好的效果。
我们考虑一个有监督学习的场景,每个训练数据都由一对固定大小的向量序列(x(a)1 ,...,x(a)Ta ), (x(b)1 ,...,x(b)Tb )和一个标签y组成。注意每对序列的长度Ta,Tb可能是不同的,并且不同数据的长度也可能是不同的。虽然我们把两个序列看作是对称的,我们的方法可以很容易的从一个领域扩展到另一个领域。假设y的值表示相似度,我们的算法产生从一般的变长序列空间到固定维度的可解释的结构化度量空间(其可以应用于不存在于数据中的新例子,不像流形嵌入诸如多维缩放的技术)的映射。
我们的激励性例子是在语句相似性之间进行评分的任务,给定数据对的的语义相似度已被人工标记为y。在这种情况下,每个x(a)i表示来自第一句子的单词的矢量,而x(b)j表示来自第二句子的单词矢量。Thus, we employ LSTMs with the explicit goal to learn a metric that reflects semantics, in contrast to the work of Sutskever, Vinyals, and Le (2014), where such properties emerge in the learned representations as indirect effects of the translation task.
相关工作
由于它在多种任务中的重要性,语义相似度评估被作为SemEval 2014的第一个任务。这些数据的竞争方法都使用了异构特征(例如词汇重叠/相似性,否定建模,句子/短语组合)以及外部资源(例如Wordnet(Miller,1995)),并且已经应用了各种各样的学习算法(如SVM,随机森林,k-最近邻居和模型集成)。最好的原作之一来自Zhao,Zhu和Lan(2014),使用潜藏语义分析和许多其他手工特征来学习向量空间表示。另一个高性能系统,来自Bjerva等人(2014)使用形式语义和逻辑推理,结合从Mikolov等人流行的word2vec神经语言模型得到的特征(2013),将这些词向量作为模型的唯一输入。
近来,三个和我们的方法更相似的神经网络方法已经取得了显著的性能提升。Gimpel, and Lin (2015)提出了一个精心制作的卷及网络变体,这个网络通过集成不同尺度的卷积来推断语义相似度。这几个作者解释说,由于标记数据的可用性限制,大量的构建工程是必需的,我们的一个解决办法就是扩增数据集。
Kiros等人(2015)提出了skip-thoughts模型,是word2vec跳字模型从词到句子级别的扩展。这个模型将每个句子送人一个RNN编码-解码器(使用GRU激活),试图重构当前和后面的句子。为了将他们的方法应用到语义相似度任务,Kiros等人首先让一个句子通过RNN编码器(在初始语料上训练后它的权重是固定的)去获得一个 skip-thought向量。然后,使用从skip-thought向量间的差异和内积中提取的特征在SICK数据上训练一个单独的分类器 随后,使用从SICK数据中每个训练实例中求出的一对skip-thought向量之间的差异和内积得出的特征训练一个单独的分类器。就像Sutskever, Vinyals, and Le (2014),的编码器-解码器框架一样,skip-thought表示间接的表达语义而不是直接表示。
Tai, Socher, and Manning (2015)提出了Tree-LSTMs,将顺序敏感,链式结构的标准LSTM泛化为一个树型结构。每个句子都首先被转化成一个解析树(使用一个独立地预训练解析器)。Tree-LSTM的隐藏状态由相应词的给定树节点以及所有子节点的隐藏状态组成。(the Tree-LSTM composes its hidden state at a given tree node from the corresponding word as well as the hidden states of all child nodes.)希望通过映射一个句子的句法属性,由解析书构造的网络能够比顺序限制网路更有效地传播必要的信息。这个模型已经被用于语义相似度,就像Kiros等人的模型一样,输入句子的表示由Tree-LSTMs产生而不是skip-thought(不过最后在SICK数据上的分类器是和LSTM语句表示一起训练的)。
我们提出的模型也是用神经网络表示句子,它的输入是从一个大语料库学习的词向量。不过我们的表示学习目标直接反映了给定的语义相似度标签而不像Kiros等人的方法。尽管这些前面提到的神经网络利用复杂的学习器从句子表示中预测语义相似性,但是我们强加了更强的要求:即应该学习语义结构化的表示空间,使得简单的度量足以捕获句子相似度。这个观点也存在于由Chopra, Hadsell, and LeCun (2005)提出的用于面部识别的孪生结构,不过这个结构使用对称卷积网络,我们的网络使用LSTM。孪生网络已经被提出用于大量的度量学习任务(Yih et al. 2011; Chen and Salman 2011),但是据我们所知,循环连接仍然有很大的探索空间。
曼哈顿LSTM模型
曼哈顿LSTM模型可以用图1来概括。
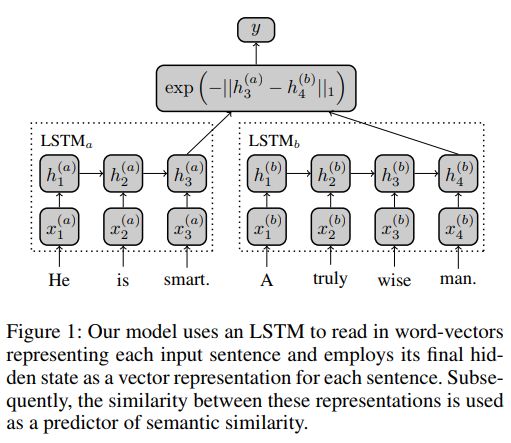
有两个网络LSTMa和LSTMb,分别处理一对句子中的一个,但是我们只集中于孪生结构,绑定网络的权重使LSTMa=LSTMb。不过,这个模型的非绑定的一般版本可能会在非对称领域的应用比如信息检索(搜索查询在文体上与存储的文档不同)上更有效。
这里的LSTM学习从din维向量的变长序列的空间到drep维空间的映射。更具体地说,将每个句子(表示为一个单词向量序列)x1,...,xT传递给LSTM,LSTM通过等式(2) - (7)更新每个序列索引处的隐藏状态。句子的最终表示由模型最后的隐藏状态hT ∈ Rdrep编码。给定一对句子,我们的方法使用一个预定义的相似度函数g : Rdrep × Rdrep → R到LSTM表示。表示空间的相似度随后被用于推断句子的语义相似度。
注意不像传统的语言模型RNN那样通常被用于给定文本预测下一个单词,我们的LSTM就像 Sutskever, Vinyals, and Le (2014)的编码器。因此,训练期间反向传播的唯一误差信号源于句子表示h(a)Ta,h(b)Tb之间的相似性,以及这种预测相似度如何偏离人为标注的基本事实相关性。我们仅限于简单的相似度函数
这会迫使LSTM在训练时彻底地捕捉语义差异,而不是用更复杂的学习器替代RNN,这样可以帮助解决Kiros et al. (2015) and Tai, Socher, and Manning (2015)所做的表示学习的缺陷。
像 Chopra, Hadsell, and LeCun (2005)指出的那样,在相似度函数中使用L2而不是L1正则会导致在整体目标函数中出现undesirable plateaus。这是因为在训练的早期阶段,基于L2的模型无法纠正由于欧几里德距离的梯度弥散而使语义上不同的句子几乎相同的错误。经验地,我们的结果在不同种类的简单相似度函数中是相当稳定的,但是我们发现使用曼哈顿距离的性能比其他有合理解释的选择比如余弦相似度有稍微好一点的效果。
语义相关性得分
SICK数据有9927个句子对,分成5000训练集,4927测试集(Marelli et al. 2014)。每一对都标注了位于区间【1,5】的相关性标签,标签来自10个不同的人评判的均值。Kiros et al. (2015)指出虽然他们的skip-thought RNN在一个巨大的语料库训练了两周,但表1中展示的大部分测试集句子它仍不能区分,突出了这个任务的难度。

为了让我们的模型能够泛化超出SICK训练集中有限的词汇,我们给LSTM提供了能够反应单词间关系的输入,超出了可以从少量训练集句子推断出的关系。LSTM由于大量的参数需要大量的数据才能达到好的泛化结果。因此我们用许多额外的数据去扩充训练集,a common practice in SemEval systems (Marelli et al. 2014) as well as high-performing neural networks。像许多高性能语义相似度系统一样,我们的LSTM以外部预料预训练的词向量为输入。我们使用300维的Word2vec词嵌入(由Mikolov et al. (2013)证明能够捕捉复杂的词间关系比如vec(king) − vec(man) + vec(woman) ≈vec(queen).)。我们鼓励使用精确措辞的不变性,并扩展我们的数据集,通过使用基于同义词库的增强,其中通过用在Wordnet中找到的其中一个同义词随机替换单词来生成10,022个额外的训练示例(Miller 1995)。类似的策略也被Zhang, Zhao, and LeCun (2015).成功使用。不像SemEval 2014,我们的方法除了单独训练word2vec向量外不需要大量的手工特征。
MaLSTM通过函数g(h(a)Ta , h(b)Tb )预测一对句子的相关性,并且我们先将训练集的相关性标签收缩到区间【0,1】,然后在均方误差损失函数下使用backpropagation-through-time训练孪生网络。SemEval根据三个度量指标评估预测的相似度:Pearson(皮尔森)相关性,Spearman(斯皮尔曼)相关性和MSE。因为我们的相似度函数的简单结构,模型的预测值会遵从exp(−x)曲线,因此不会符合那些评估度量。训练完模型后,我们增加一个非参数回归步骤来获得更好的校准预测(关于MSE)。Over the training set, the given labels (under original [1, 5] scale) are regressed against the univariate MaLSTM g-predicted relatedness as the sole covariate, and the fitted regression function is evaluated on the MaLSTM-predicted relatedness of the test pairs to produce adjusted final predictions.We use the classical local-linear estimator discussed in Fan and Gijbels (1992) with bandwidth selected using leave-one-out cross-validation. This calibration step serves as a minor correction for our restrictively simple similarity function (which is necessary to retain interpretability of the sentence representations).
训练细节
我们的LSTM使用50维的隐藏表示ht和记忆单元ct。参数的优化使用Zeiler(2012)的Adadelta方法以及梯度剪切(缩放范数超过阈值的梯度)以避免梯度爆炸问题(Pascanu, Mikolov, and Bengio 2013)。我们基于包含30%训练数据的验证机做早停止。
众所周知,LSTMs的成功关键依赖于初始化,并且通常从用于不同任务所训练的神经网络传递的参数可以作为一个强大的优化起点。我们首先用高斯随机初始化我们的LSTM权重(用一个单独的大数值为2.5作为遗忘门偏置,以促进对长距离依赖的建模)。然后,我们的LSTM就像之前所说的那样,在单独的句子对上(预)训练,这些数据是为更早的的SemEval 2013 Semantic Textual Similarity任务 (Agirre and Cer 2013)提供的数据。从这个预训练得到的权重成为在SICK数据上的训练起点,这明显比随机初始化权重要好。
结果
MaLSTM可以给表1中的示例精确打分,而这对于Kiros et al.的skip-thoughts模型却很难。尽管针对MSE进行了校正,但对于语义相关的任务我们的方法在这所有三个评估指标上的表现最好(见表2)。注意因为表2中的所有结果都依赖额外的特征提取(比如 dependency parses)或者数据增强,所以这只是一个完整的对相关性打分系统的评估,而不是对不同学习算法的公平比较。尽管如此,为了更好地理解我们的方法,我们做了一些对比发现皮尔森相关性(主要的SemEval性能度量)在一些情况下会变差,在没有回归校正时会降低0.01,没有预训练会降低0.02,没有同义词增强会降低0.04。由于可靠的训练数据有限,我们无法通过切换到多层或双向LSTM来实现性能提升。

在表3中Tai, Socher, and Manning展示了使用Tree-LSTM发现的针对三个给定句子最相近的测试集示例以及它们的相似度得分。我们将我们的模型应用到这些相同的示例上,发现虽然顺序MaLSTM在识别等价主被动句上稍微有些差,但是在区别动词和宾语上比Tree-LSTM更好。Tree-LSTM似乎总是会过高的估计表3中句子的相关性。 For example, the ground truth labeling between “Tofu is being sliced by a woman” and “A woman is slicing butter” is only 2.7 in the SICK test set (and substituting “potatoes” for “butter” should not greatly increase relatedness between the two statements).