当你喜欢一个女生的时候,你会付出你的所有,和我好像。
1.文本相似度计算——文本向量化
1.前言
在自然语言处理过程中,经常会涉及到如何度量两个文本之间的相似性,我们都知道文本是一种高维的语义空间,如何对其进行抽象分解,从而能够站在数学角度去量化其相似性。
有了文本之间相似性的度量方式,我们便可以利用划分法的K-means、基于密度的DBSCAN或者是基于模型的概率方法进行文本之间的聚类分析;另一方面,我们也可以利用文本之间的相似性对大规模语料进行去重预处理,或者找寻某一实体名称的相关名称(模糊匹配)。
而衡量两个字符串的相似性有很多种方法,如最直接的利用hashcode,以及经典的主题模型或者利用词向量将文本抽象为向量表示,再通过特征向量之间的欧式距离或者皮尔森距离进行度量。这里将对NLP中文本相似度计算第一步文本向量化做一个简述。
2. 文本向量化
无论文本式中文还是英文,我们首先要把它转化为计算机认识的形式。转化为计算机认识的形式的过程叫文本向量化。
向量化的粒度我们可以分为几种形式:
1.以字或单词为单位,中文就是单个字,英文可以是一个单词。
2.以词为单位,就需要加入一个分词的过程。分词算法本身是一个NLP中重要的基础课题,本文不详细讲解。
3.以句子为单位,提炼出一句话的高层语义,简而言之就是寻找主题模型。当然如果我们已经拿到了一句话的所有词的向量,也可以简单的通过取平均或者其他方式来代表这个句子。
下面我们主要介绍以词为单位的文本向量化方法,词集模型、词代模型、n-gram、TF-IDF、word2vec。和以句子为单位的主题模型,LSA、NMF、pLSA、LDA等。
2.1 词集模型和词代模型
词集模型和词代模型都是将所有文本中单词形成一个字典vocab,然后根据字典来统计单词出现频数。不同的是:
1.词集模型是单个文本中单词出现在字典中,就将其置为1,而不管出现多少次。
2.词代模型是单个文本中单词出现在字典中,就将其向量值加1,出现多少次就加多少次。
词集模型和词代模型都是基于词之间保持独立性,没有关联为前提。这使得其统计方便,但同时也丢失了文本间词之间关系的信息。
2.2 n-gram
n-gram是一种基于统计语言模型的算法。它的基本思想是将文本里面的内容按照字节进行大小为n的滑动窗口操作,形成了长度是n的字节片段序列。
以“我爱中国”为例:
一元模型(unigram model)分为“我”“爱”“中”“国”
二元模型(bigram model)分为“我爱”“爱中”“中国”
三元模型(trigram model)分为“我爱中”“爱中国”
以此类推,分好词后,就可以像词代模型的处理方式,按照词库去比较句子中出现的次数。n-gram能够比较好的记录句子中词之间的联系,n越大句子的完整度越高,但是随之而来的是词的维度成指数级增长。所以一般取n=2,n=3。
2.3 TF-IDF
TF-IDF是Term Frequency - Inverse Document Frequency的缩写,即“词频-逆文本频率”。它由两部分组成,TF和IDF。
前面的TF也就是我们前面说到的词频,我们之前做的向量化也就是做了文本中各个词的出现频率统计,并作为文本特征,这个很好理解。关键是后面的这个IDF,即“逆文本频率”如何理解。前面,我们讲到几乎所有文本都会出现的"的"其词频虽然高,但是重要性却应该比词频低的"西瓜"和“中国”要低。我们的IDF就是来帮助我们来反应这个词的重要性的,进而修正仅仅用词频表示的词特征值。
所以一个词的定量化表示比较合理的是(词频X词的权重)。
TF−IDF(x)=TF(x)∗IDF(x)
2.4 word2vec
word2vec是google在2013年推出的一个NLP工具,它的特点是将所有的词向量化,这样词与词之间就可以定量的去度量他们之间的关系,挖掘词之间的联系。word2vec一般有CBOW和Skip-Gram模型。
CBOW模型的训练输入是某一个特征词的上下文相关的词对应的词向量,而输出就是这特定的一个词的词向量。通过深度学习训练出相应的固定维度的词向量。Skip-Gram模型和CBOW模型反一反,输入是中心词,输出是上下文。
2.5 主题词模型
设想一下一个问题,如果我有两个文本,分别是“星期天”和“周日”,从词的角度,它们没有相交的词,那它们用统计词频的方法就会比较难处理。但是这两个词,我们一看就知道意思完全一样的。这里就可以用主题模型对它们进行处理,假设我们找到它们的2个隐含主题“假期”,“休息”,然后计算它们和隐含主题间的距离的相似度。
主题模型主要有以下几种,LSA、NMF、pLSA、LDA。
LSA是通过奇异值分解的方式把文本分解成如下,UilUil 对应第ii个文本和第ll个主题的相关度。VjmVjm对应第jj个词和第mm个词义的相关度。ΣlmΣlm对应第ll个主题和第mm个词义的相关度。
Am×n≈Um×kΣk×kVTk×n
NMF虽然也是矩阵分解,它却使用了不同的思路,它的目标是期望将矩阵分解为两个矩阵。这样速度更快,而且不会出现LSA中相关度为负数的情况,可解释性强。
Am×n≈Wm×kHk×n
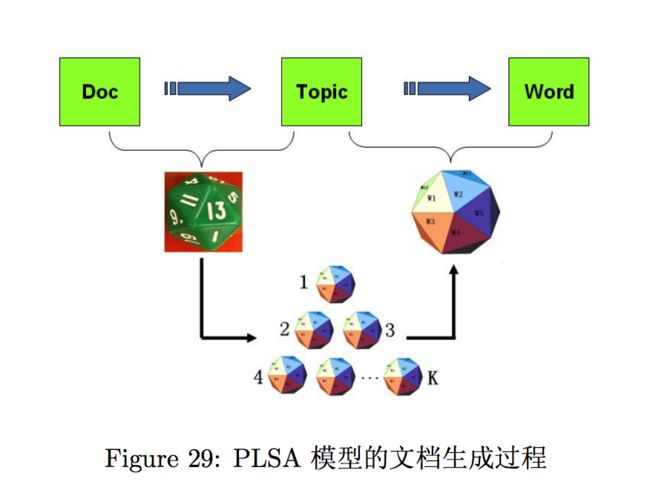
pLSA可以从概率的角度解释了主题模型
按照概率p(dm)选择一篇文档dm
根据选择的文档dmdm,从从主题分布中按照概率p(zk|dm)即(θmzθmz)选择一个隐含的主题类别zk
根据选择的主题zk, 从词分布中按照概率p(wj|zk)即(φzwφzw)选择一个词wj。
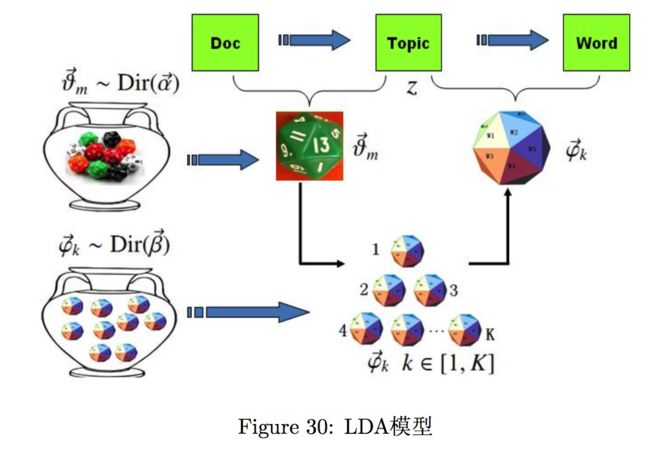
LDA模型考虑了主题概率分布的先验知识,比如文本中出现体育主题的概率肯定比哲学主题的概率要高,这点来源于我们的先验知识。
这里主要介绍了文本相似度计算的第一步,文本的向量化。向量化好后,我们就可以通过一些常用的距离计算公式计算文本之间的相似度。
1. 前言
上文介绍了文本的向量化处理,本文是在上文的向量化处理后的数据进行距离的计算。距离度量的方式有多种多样,但是一种相似度计算方式并不适用与所有的情况,需要根据不同的情况和数据类型进行选择。
2.相似度计算公式:
相似度就是比较两个事物的相似性。一般通过计算事物的特征之间的距离,如果距离小,那么相似度大;如果距离大,那么相似度小。
简化问题:假设有两个对象XX、YY,都包括NN维特征,X=(x1,x2,x3,..,xn),Y=(y1,y2,y3,..,yn)X=(x1,x2,x3,..,xn),Y=(y1,y2,y3,..,yn),计算XX和YY的相似性。常用的方法如下:
3.欧氏距离和余弦相似度的公式及其适用场景:
3.1余弦相似度:
余弦相似度用向量空间中两个向量夹角的余弦值作为衡量两个个体间差异的大小。相比距离度量,余弦相似度更加注重两个向量在方向上的差异,而非距离或长度上。适合word2vec模型向量化的数据。
cosθ=∑ni=1xi∗yi∑ni/∑ni=1xi的平方*yi的平方分母开根号
最近在做“判断两段文本的语义相似度”的事情,实验中用doc2vec做文本向量化,用余弦值衡量文本相似度。
## 那么为什么选用余弦呢?
如向量的维度是3,有三段文本a、b、c,文本向量化之后的结果假如如下:a=(1,0,0)、b=(0,1,0)、c=(10,0,0)。
我们知道doc2vec的每一个维度都代表一个特征,观察向量的数字,主观看来a和c说的意思应该相似,阐述的都是第一个维度上的含义,a和b语义应该不相似。那么如果用欧式距离计算相似度,a和b的相似度就比a和c的相似度高,而如果用余弦计算,则答案反之。
## 那么欧式距离和余弦相似度的区别是什么呢?
余弦相似度衡量的是维度间取值方向的一致性,注重维度之间的差异,不注重数值上的差异,而欧氏度量的正是数值上的差异性。
## 那么欧式距离和余弦相似度的应用场景是什么呢
以下场景案例是从网上摘抄的。
如某T恤从100块降到了50块(A(100,50)),某西装从1000块降到了500块(B(1000,500)),那么T恤和西装都是降价了50%,两者的价格变动趋势一致,可以用余弦相似度衡量,即两者有很高的变化趋势相似度,但是从商品价格本身的角度来说,两者相差了好几百块的差距,欧氏距离较大,即两者有较低的价格相似度。
如果要对电子商务用户做聚类,区分高价值用户和低价值用户,用消费次数和平均消费额,这个时候用余弦夹角是不恰当的,因为它会将(2,10)和(10,50)的用户算成相似用户,但显然后者的价值高得多,因为这个时候需要注重数值上的差异,而不是维度之间的差异。
两用户只对两件商品评分,向量分别为(3,3)和(5,5),显然这两个用户对两件商品的偏好是一样的,但是欧式距离给出的相似度显然没有余弦值合理。
3.2欧氏距离
欧氏距离是最常用的距离计算公式,衡量的是多维空间中各个点之间的绝对距离,当数据很稠密并且连续时,这是一种很好的计算方式。
因为计算是基于各维度特征的绝对数值,所以欧氏度量需要保证各维度指标在相同的刻度级别,如在KNN中需要对特征进行归一化。
d=∑ni=1(xi−yi)2−−−−−−−−−−√
4.曼哈顿距离的简介及其适用场景:
首先介绍一下曼哈顿,曼哈顿是一个极为繁华的街区,高楼林立,街道纵横,从A地点到达B地点没有直线路径,必须绕道,而且至少要经C地点,走AC和 CB才能到达,由于街道很规则,ACB就像一个直角3角形,AB是斜边,AC和CB是直角边,根据毕达格拉斯(勾股)定理,或者向量理论,都可以知道用AC和CB可以表达AB的长度。
在早期的计算机图形学中,屏幕是由像素构成,是整数,点的坐标也一般是整数,原因是浮点运算很昂贵,很慢而且有误差,如果直接使用AB的距离,则必须要进行浮点运算,如果使用AC和CB,则只要计算加减法即可,这就大大提高了运算速度,而且不管累计运算多少次,都不会有误差。因此,计算机图形学就借用曼哈顿来命名这一表示方法。
曼哈顿距离:两点在南北方向上的距离加上在东西方向上的距离,即d(i,j)=|xi-xj|+|yi-yj|。对于一个具有正南正北、正东正西方向规则布局的城镇街道,从一点到达另一点的距离正是在南北方向上旅行的距离加上在东西方向上旅行的距离。
通过分析下面的题目,可知其可以应用曼哈顿距离计算至(1,1)点最近的点,依据曼哈顿距离即可计算出结果值。若不明白曼哈顿的定义及应用,通过画图观察,其实也可以得到答案。显然若之前就明白曼哈顿距离的定义及应用,问题手到擒来!
即曼哈顿距离主要适用于分析图形的距离。
曼哈顿距离简单来说就是统计相同坐标轴上的距离的和。
d=∑ni=1|xi−yi|
5.闵可夫斯基距离的公式及其适用场景:
大家有没发现欧式距离和曼哈顿距离在形式上比较相近。是的,其实它们是闵可夫斯基距离的特殊化。适合TF-IDF向量化后的数据或者提炼出来的主题模型数据。
d=(∑ni=1(xi−yi)p)p分之1次方
6.皮尔森相关系数(pearson)
皮尔森相关系数是衡量线性关联性的程度。
两个连续变量(X,Y)(X,Y)的pearson相关性系数PX,YPX,Y等于它们之间的协方差cov(X,Y)cov(X,Y)除以它们各自标准差的乘积σXσX,σYσY。系数的取值总是在-1.0到1.0之间,接近0的变量被成为无相关性,接近1或者-1被称为具有强相关性。
PX,Y=cov(X,Y)/σXσY
7.Jaccard相似性系数
Jaccard(杰卡德)相似性系数主要用于计算符号度量或布尔值度量的样本间的相似度。若样本间的特征属性由符号和布尔值标识,无法衡量差异具体值的大小,只能获得“是否相同”这样一种结果,而Jaccard系数关心的是样本间共同具有的特征。适合词集模型向量化的数据。
J(X,Y)=|X⋂Y|/|X⋃Y|
这里介绍的相似度计算方式,总的来说还是比较简单、易于理解。相似度计算方式的不同对最终结果的影响没有向量化方式不同影响大,但是相似度计算方式不同对计算时间影响比较大。