原帖地址:https://www.cnblogs.com/lx3822/p/8808845.html
继承
1:什么是继承
继承是一种创建新类的方式,在python中,新建的类可以继承一个或多个父类,也就是说在python中支持一个儿子继承多个爹。
新建的类成为子类或者派生类。
父类又可以成为基类或者超类。
子类会遗传父类的属性。
2:为什么要用继承
减少代码冗余(也就是重复写代码)。
3:怎么用继承:
我们定义两个类;
class parenclass1:
pass
class parenclass2:
pass
在定义两个类:
class subclass1: pass class subclass2: pass 我想让 : class parenclass1: 作为 class subclass1: 的父类。 pass pass
应该这样用: class subclass1( parenclass1): 这就表示subclass1是子类,parenclass 是subclass1 的父类 pass
两个父类的话怎么表达呢?如下: class subclass2(parenclass1,parenclass2): pass 这就表示subclass2的父类是parenclass1,parenclass2 这两个
想要查看子类的父类 应该怎样查看呢: 用__bases__ 如下:
class ParentClass1:
pass
class ParentClass2:
pass
class Subclass1(ParentClass1): pass class Subclass2(ParentClass1,ParentClass2): pass print(Subclass1.__bases__) #打印结果:(<class '__main__.ParentClass1'>,) print(Subclass2.__bases__) #打印结果: (<class '__main__.ParentClass1'>, <class '__main__.ParentClass2'>)
经典类与新式类
1、只有在python2中才分新式类和经典类,python3中统一都是新式类
2、在python2中 没有显示继承的object类的类,以及该类的子类都是经典类
3、在python2中,显示的声明继承object的类,以及该类的子类都是新式类 4、在python3中,无论是否继承object,都默认 继承object,即python3中所有类均为新式类 至于经典类 与新式类的区别,后面会有讨论。 提示:如果没有指定基类, python的类会默认继承object类, object是所有python类的基类。
二、继承与抽象
继承描述的是子类与父类之间的关系,是一种什么的关系呢? 要找出这种关系, 必须先抽象在继承。
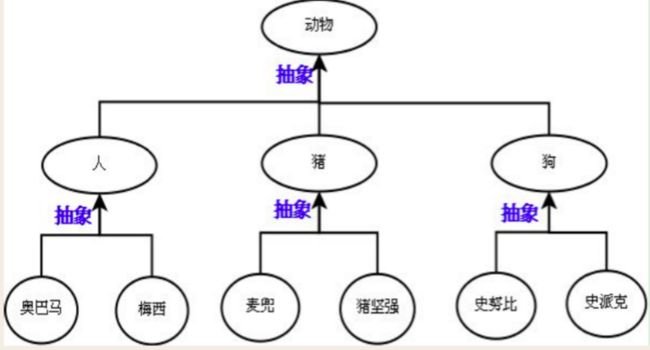
抽象即抽取类似或者说比较像的部分。
抽象分成两个层次:
1.将奥巴马和梅西这俩对象比较像的部分抽取成类;
2.将人,猪,狗这三个类比较像的部分抽取成父类。
抽象最主要的作用是划分类别(可以隔离关注点,降低复杂度)
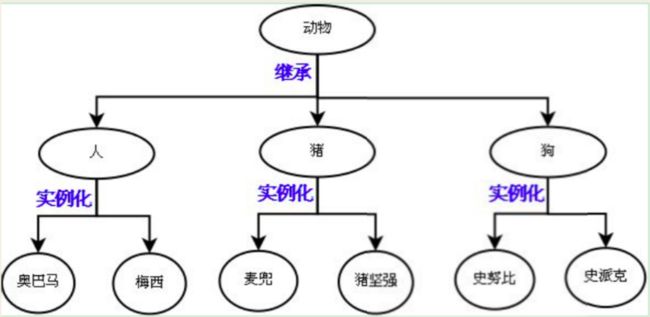
继承:是基于抽象的结果,通过编程语言去实现它,肯定是先经历抽象合格过程, 才能通过继承的方式去表达抽象的结构。
抽象只是分析和设计的过程,一个动作或者说一种技巧,通过抽象可以得到类
例如:我们写一个老男孩的老师与学生的类,若是不涉及到继承的话 我们正常是这样写
class OldboyTeacher:
school = 'oldboy' def __init__(self,name,age,sex): self.name=name self.age=age self.sex=sex def change_score(self): print('teacher %s is changing score ' %self.name) class Oldboystudent:
school = 'oldboy’
def __init__(self,name,age,sex):
self.name=name
self.age=age
self.sex=sex
def choose(self):
print('student %s choose course' %self.name) tea1 = OldboyTeacher('egon', 18, 'male') #OldboyTeacher.__init__(...) stu1=Oldboystudent('alex',73,'female') print(tea1.name,tea1.age,tea1.sex) # egon 18 male
print(stu1.name) #alex
但是我们经过分析 发现里面里面有许多重复代码, 这时我们可以用到类的继承来写了。如下:
class OldboyPeople:
school ='oldboy' def __init__(self,name,age,sex): self.name=name self.age=age self.sex=sex class Oldboyteacher(OldboyPeople): def change_score(self): print('teacher %s is changing score ' %self.name)
class Oldboystudent(OldboyPeople): def choose(self): print('student %s choose course'%self.name) tea1 = Oldboyteacher('egon', 18, 'male') stu1=Oldboystudent('alex',73,'female')
print(tea1.name,tea1.age,tea1.sex)#egon 18 male print(stu1.name) #alex
三、基于继承在看属性查找
我们先看一个列子
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
class
Foo:
def f1(self):
print(
'Foo.f1'
)
def f2(self): #self=obj
print(
'Foo.f2'
) #在父类中找到发 f2属性,第3步打印这一行
self.f1() #obj.f1() 第4步再去掉用self的f1属性
class
Bar(Foo):
def f1(self):#第五步, 在回到
object
自身的名称空间找f1属性,找到后调用
print(
'Bar.f1'
) #第6步 执行
obj=Bar() #第一步 :类的实例化, 先得到一个空对象,
obj.f2() #第2步:空对象调用f2属性 在自身寻找f2属性, 没有找到就去父类中寻找
|
Foo.f2
Bar.f1
注意子类的属性查找,一定是优先查找子类自己本身的属性与特征, 在本身没有的情况下 在去父类中查找。
这个还是非常有意思的,当执行obj.f2时,自己没有该属性,寻找父类属性,当找到f2属性时,执行self.f1,又优先取寻找自己的self.f1属性了,确实够贱。
self很重要,哪个self进去,属性都是先找self身上自己的。
四、派生
派生:子类定义自己新的属性,如果与父类同名,以子类自己的为准。
class OldboyPeople:
school = 'oldboy' def __init__(self, name, age, sex): self.name = name self.age = age self.sex = sex def f1(self): print('爹的f1') class OldboyTeacher(OldboyPeople): def change_score(self): print('teacher %s is changing score' %self.name) def f1(self): print('儿子的f1') tea1 = OldboyTeacher('egon', 18, 'male') tea1.f1()
#调用显示:儿子的f1
# 父类和子类中都有f1, 优先调用自己的属性,所以结果调用的是儿子的f1
五、在子类中派生出的新方法重用父类的功能
拿上一案例来举例 在oldboyteacher 这个类中要添加薪水与级别。 然后调用。 有两种方式。
方式一:指名道姓的调用(与继承没有什么关系)
class OldboyPeople:
school ='oldboy' def __init__(self,name,age,sex): self.name=name self.age=age self.sex=sex def tell_info(self): print( ''' ====个人信息==== 姓名:%s 年龄:%s 性别:%s '''%(self.name,self.age,self.sex)) class OldboyTeacher(OldboyPeople): def __init__(self,name,age,sex,level,salary): OldboyPeople.__init__(self,name,age,sex) #在这里指明道姓来调用这一个函数里的属性 self.level =level self.salary=salary def tell_info(self): OldboyPeople.tell_info(self) #指名道姓的来调用这个函数里的属性 print(""" 等级:%s 薪资:%s """ %(self.level,self.salary)) tea1 = OldboyTeacher('egon', 18, 'male', 9, 3.1) print(tea1.name, tea1.age, tea1.sex, tea1.level, tea1.salary) tea1.tell_info() #打印结果: egon 18 male 9 3.1 ====个人信息==== 姓名:egon 年龄:18 性别:male 等级:9 薪资:3.1
方法二、
用super()调用(严格依赖于继承)
super() 的返回值是一个特殊的对象,该对象专门用来调用父类中的属性, 一般在python2中,需要super(自己的类名,self), 而python3中,括号里面一般不填类名
class OldboyPeople:
school = 'oldboy' def __init__(self, name, age, sex): self.name = name self.age = age self.sex = sex def tell_info(self): print(""" ===========个人信息========== 姓名:%s 年龄:%s 性别:%s """ %(self.name,self.age,self.sex)) class OldboyTeacher(OldboyPeople): def __init__(self, name, age, sex, level, salary): super().__init__(name,age,sex) self.level = level self.salary = salary def tell_info(self): super().tell_info() print(""" 等级:%s 薪资:%s """ %(self.level,self.salary)) tea1 = OldboyTeacher('egon', 18, 'male', 9, 3.1) print(tea1.name, tea1.age, tea1.sex, tea1.level, tea1.salary) tea1.tell_info() #调用结果: egon 18 male 9 3.1 ===========个人信息========== 姓名:egon 年龄:18 性别:male 等级:9 薪资:3.1
六:经典类 与新式类
1新式类:
继承object的类,以及该类的子类,都是新式类
在python3中,如果一个类没有指定继承的父类,默认就继承object
所以说在python3中所有的类都是新式类
2经典类:(只有在python2才区分经典类和新式类):
没有继承object的类,以及该类的子类 都是经典类
1 经典类:深度优先
2 新式类:广度优先
如果继承关系为非菱形结果吗则会按照先找B 这一条分支,然后在找c这一条分支,最后找D这一条分支的顺序,直到找到我们想要的属性
当继承关系为菱形结构时
经典类查找顺序:
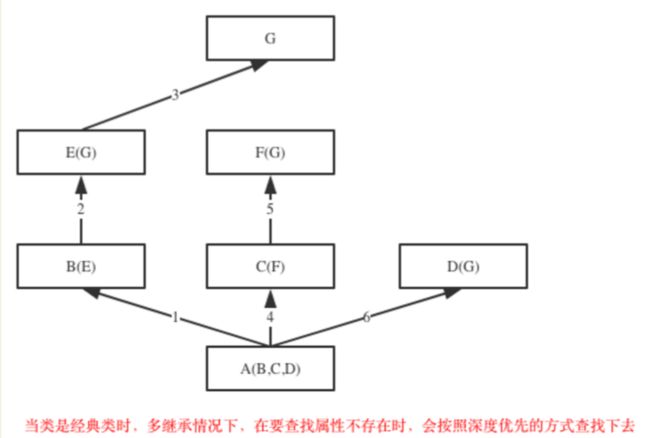
若是在A 类里自己没找到, 则会先去B类里去找, B类里没找到,就会在E类里找, 然后在G类里找,
G类里没找到 会去C 类里找, 然后去F 类里找,最后去D 类里找。
新式类查找顺序:

按照图中1 ,2 , 3, 4,5,6的顺序查找, 这个为广度优先的查找方式
这个图 蛮好的,缺少了两个线,应该E(G)与F(G)也指向G(object),其实对于新式类的继承,基于广度与深度,我自己根本无法定论。
C3算法我没去仔细研究,但根据我自己的经验来看,会根据继承的类的顺序与深度相关。
下面上我自己写的测试代码:
class A(object):
def ping(self):
print('ping', self)
class B(A):
def pong(self):
print('pong', self)
class E(B):
...
class F(object):
...
class H(F):
...
class C(H):
def pong(self):
print('PONG', self)
class D(C, E):
def ping(self):
super(D, self).ping()
print('post-ping', self)
if __name__ == '__main__':
print(D.__mro__)
/usr/local/bin/python3.7 /Users/shijianzhong/study/Fluent_Python/第十二章/diamond.py (, , , , , , , ) Process finished with exit code 0
从运行结果来看,C线继承到object之前,一致沿着C走,后面再沿着E走。
object是两个父类的相交的基类结合点。
class A(object):
def ping(self):
print('ping', self)
class B(A):
def pong(self):
print('pong', self)
class E(B):
...
class F(object):
...
class H(A):
...
class C(H):
def pong(self):
print('PONG', self)
class D(C, E):
def ping(self):
super(D, self).ping()
print('post-ping', self)
if __name__ == '__main__':
print(D.__mro__)
/usr/local/bin/python3.7 /Users/shijianzhong/study/Fluent_Python/第十二章/diamond.py (, , , , , , ) Process finished with exit code 0
我把上面代码的H继承到了A,这样D的两个父类的基类相交点到A了,从继承来看,先寻找C线到A之前的类,然后再用E寻找到最后的object。
七: super()依赖继承
super()会严格按照mro列表从当前查找到的位置继续往后查找
class A:
def test(self):
print('A.test') #2 执行这一步 打印 super().f1 #3 然后在调用父类里的f1, 根据C.mro里的查找顺序执行到A 往后继续执行到B里去查找 class B: def f1(self): #4找到f1, 执行 print('from B') #5打印 class C(A,B): pass c=C() print(C.mro()) #调用属性的顺序 [, , , ] c.test() #1:C里没有 ,去A里调用
#打印结果
A.test
from B