背景
Apache Spark作为当前最为流行的开源大数据计算框架,广泛应用于数据处理和分析应用,它提供了两种方式来处理数据:一是交互式处理,比如用户使用spark-shell或是pyspark脚本启动Spark应用程序,伴随应用程序启动的同时Spark会在当前终端启动REPL(Read–Eval–Print Loop)来接收用户的代码输入,并将其编译成Spark作业提交到集群上去执行;二是批处理,批处理的程序逻辑由用户实现并编译打包成jar包,spark-submit脚本启动Spark应用程序来执行用户所编写的逻辑,与交互式处理不同的是批处理程序在执行过程中用户没有与Spark进行任何的交互。
两种处理交互方式虽然看起来完全不一样,但是都需要用户登录到Gateway节点上通过脚本启动Spark进程。这样的方式会有什么问题吗?
首先将资源的使用和故障发生的可能性集中到了这些Gateway节点。由于所有的Spark进程都是在Gateway节点上启动的,这势必会增加Gateway节点的资源使用负担和故障发生的可能性,同时Gateway节点的故障会带来单点问题,造成Spark程序的失败。
其次难以管理、审计以及与已有的权限管理工具的集成。由于Spark采用脚本的方式启动应用程序,因此相比于Web方式少了许多管理、审计的便利性,同时也难以与已有的工具结合,如Apache Knox。
同时也将Gateway节点上的部署细节以及配置不可避免地暴露给了登陆用户。
为了避免上述这些问题,同时提供原生Spark已有的处理交互方式,并且为Spark带来其所缺乏的企业级管理、部署和审计功能,本文将介绍一个新的基于Spark的REST服务:Livy。
Livy
Livy是一个基于Spark的开源REST服务,它能够通过REST的方式将代码片段或是序列化的二进制代码提交到Spark集群中去执行。它提供了以下这些基本功能:
提交Scala、Python或是R代码片段到远端的Spark集群上执行;
提交Java、Scala、Python所编写的Spark作业到远端的Spark集群上执行;
提交批处理应用在集群中运行。
从Livy所提供的基本功能可以看到Livy涵盖了原生Spark所提供的两种处理交互方式。与原生Spark不同的是,所有操作都是通过REST的方式提交到Livy服务端上,再由Livy服务端发送到不同的Spark集群上去执行。说到这里我们首先来了解一下Livy的架构。
Livy的基本架构
Livy是一个典型的REST服务架构,它一方面接受并解析用户的REST请求,转换成相应的操作;另一方面它管理着用户所启动的所有Spark集群。具体架构可见图1。
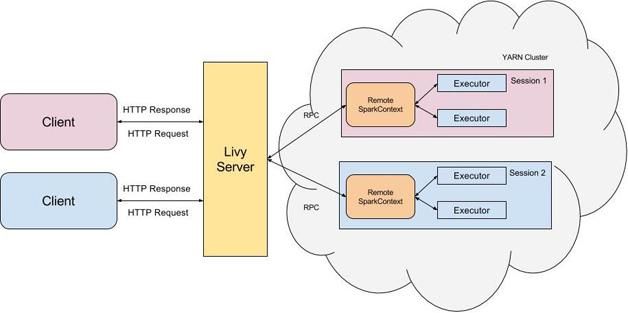
图1 Livy的基本架构
用户可以以REST请求的方式通过Livy启动一个新的Spark集群,Livy将每一个启动的Spark集群称之为一个会话(session),一个会话是由一个完整的Spark集群所构成的,并且通过RPC协议在Spark集群和Livy服务端之间进行通信。根据处理交互方式的不同,Livy将会话分成了两种类型:
交互式会话(interactive session),这与Spark中的交互式处理相同,交互式会话在其启动后可以接收用户所提交的代码片段,在远端的Spark集群上编译并执行;
批处理会话(batch session),用户可以通过Livy以批处理的方式启动Spark应用,这样的一个方式在Livy中称之为批处理会话,这与Spark中的批处理是相同的。
可以看到,Livy所提供的核心功能与原生Spark是相同的,它提供了两种不同的会话类型来代替Spark中两类不同的处理交互方式。接下来我们具体了解一下这两种类型的会话。
交互式会话(Interactive Session)
使用交互式会话与使用Spark所自带的spark-shell、pyspark或sparkR相类似,它们都是由用户提交代码片段给REPL,由REPL来编译成Spark作业并执行。它们的主要不同点是spark-shell会在当前节点上启动REPL来接收用户的输入,而Livy交互式会话则是在远端的Spark集群中启动REPL,所有的代码、数据都需要通过网络来传输。
我们接下来看看如何使用交互式会话。
创建交互式会话
POST /sessions

使用交互式会话的前提是需要先创建会话。当我们提交请求创建交互式会话时,我们需要指定会话的类型(“kind”),比如“spark”,Livy会根据我们所指定的类型来启动相应的REPL,当前Livy可支持spark、pyspark或是sparkr三种不同的交互式会话类型以满足不同语言的需求。
当创建完会话后,Livy会返回给我们一个JSON格式的数据结构表示当前会话的所有信息:
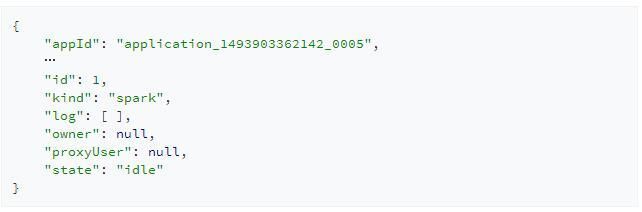
其中需要我们关注的是会话id,id代表了此会话,所有基于该会话的操作都需要指明其id。
提交代码
POST /sessions/{sessionId}/statements
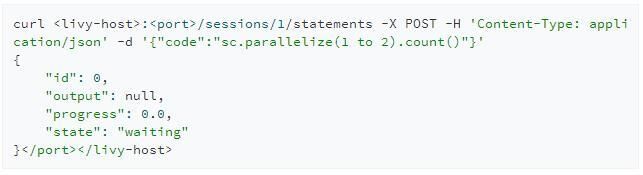
创建完交互式会话后我们就可以提交代码到该会话上去执行。与创建会话相同的是,提交代码同样会返回给我们一个id用来标识该次请求,我们可以用id来查询该段代码执行的结果。
查询执行结果
GET /sessions/{sessionId}/statements/{statementId}

Livy的REST API设计为非阻塞的方式,当提交代码请求后Livy会立即返回该请求id而并非阻塞在该次请求上直到执行完成,因此用户可以使用该id来反复轮询结果,当然只有当该段代码执行完毕后用户的查询请求才能得到正确结果。
当然Livy交互式会话还提供许多不同的REST API来操作会话和代码,在这就不一一赘述了。
使用编程API
在交互式会话模式中,Livy不仅可以接收用户提交的代码,而且还可以接收序列化的Spark作业。为此Livy提供了一套编程式的API供用户使用,用户可以像使用原生Spark API那样使用Livy提供的API编写Spark作业,Livy会将用户编写的Spark作业序列化并发送到远端Spark集群中执行。表1就是使用Spark API所编写PI程序与使用Livy API所编写的程序的比较。

表1 使用Spark API所编写PI程序与使用Livy API所编写程序的比较
可以看到除了入口函数不同,其核心逻辑完全一致,因此用户可以很方便地将已有的Spark作业迁移到Livy上。
Livy交互式会话是Spark交互式处理基于HTTP的实现。有了Livy的交互式会话,用户无需登录到Gateway节点上去启动Spark进程并执行代码。以REST的方式进行交互式处理提供给用户丰富的选择,也方便了用户的使用,更为重要的是它方便了运维的管理。
批处理会话(Batch Session)
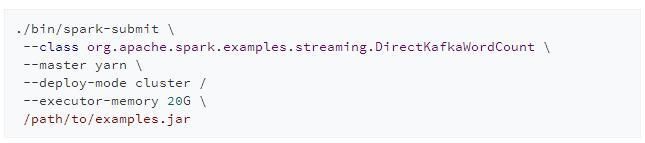
在Spark应用中有一大类应用是批处理应用,这些应用在运行期间无须与用户进行交互,最典型的就是Spark Streaming流式应用。用户会将业务逻辑编译打包成jar包,并通过spark-submit启动Spark集群来执行业务逻辑:
Livy也为用户带来相同的功能,用户可以通过REST的方式来创建批处理应用:
通过用户所指定的“className”和“file”,Livy会启动Spark集群来运行该应用,这样的一种方式就称为批处理会话。
至此我们简单介绍了Livy的两种会话类型,与它相对应的就是Spark的两种处理交互方式,因此可以说Livy以REST的方式提供了Spark所拥有的两种交互处理方式。
企业级特性
前面我们介绍了Livy的核心功能,相比于核心功能的完整性,Livy的企业级特性则更体现了其相比于原生Spark处理交互方式的优势。本章节将介绍Livy几个关键的企业特性。
多用户支持
假定用户tom向Livy服务端发起REST请求启动一个新的会话,而Livy服务端则是由用户livy启动的,这个时候所创建出来Spark集群用户是谁呢,会是用户tom还是livy?在默认情况下这个Spark集群的用户是livy。这会带来访问权限的问题:用户tom无法访问其拥有权限的资源,而相对的是他却可以访问用户livy所拥有的资源。
为了解决这个问题Livy引入了Hadoop中的代理用户(proxy user)模式,代理用户模式广泛使用于多用户的环境,如HiveServer2。在此模式中超级用户可以代理成普通用户去访问资源,并拥有普通用户相应的权限。开启了代理用户模式后,以用户tom所创建的会话所启动的Spark集群用户就会是tom。
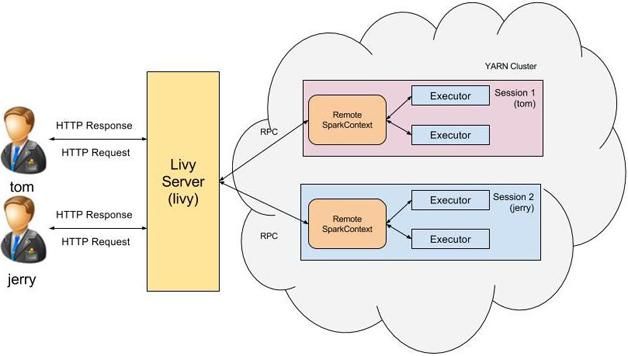
图2 Livy多用户支持
为了使用此功能用户需要配置“livy.impersonation.enabled”,同时需要在Hadoop中将Livy服务端进程的用户配置为Hadoop proxyuser 。当然还会有一些Livy的额外配置就不在这展开了。
有了代理用户模式的支持,Livy就能真正做到对多用户的支持,不同用户启动的会话会以相应的用户去访问资源。
端到端安全
在企业应用中另一个非常关键的特性是安全性。一个完整的Livy服务中有哪些点是要有安全考虑的呢?
客户端认证
当用户tom发起REST请求访问Livy服务端的时候,我们如何知道该用户是合法用户呢?Livy采用了基于Kerberos的Spnego认证。在Livy服务端配置Spnego认证后,用户发起Http请求之前必须先获得Kerberos认证,只有通过认证后才能正确访问Livy服务端,不然的话Livy服务端会返回401错误。
HTTPS/SSL
那么如何保证客户端与Livy服务端之间HTTP传输的安全性呢?Livy使用了标准的SSL来加密HTTP协议,以确保传输的Http报文的安全。为此用户需要配置Livy服务端SSL相关的配置已开启此功能。
SASL RPC
除了客户端和Livy服务端之间的通信,Livy服务端和Spark集群之间也存在着网络通信,如何确保这两者之间的通信安全性也是需要考虑的。Livy采用了基于SASL认证的RPC通信机制:当Livy服务端启动Spark集群时会产生一个随机字符串用作两者之间认证的秘钥,只有Livy服务端和该Spark集群之间才有相同的秘钥,这样就保证了只有Livy服务端才能和该Spark集群进行通信,防止匿名的连接试图与Spark集群通信。
将上述三种安全机制归结起来就如图3所示。
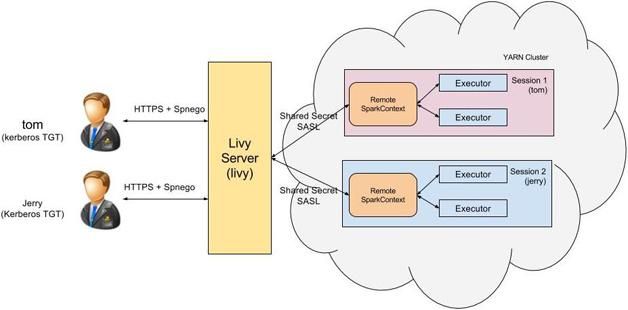
图3 Livy端到端安全机制
这样构成了Livy完整的端到端的安全机制,确保没有经过认证的用户,匿名的连接无法与Livy服务中的任何一个环节进行通信。
失败恢复
由于Livy服务端是单点,所有的操作都需要通过Livy转发到Spark集群中,如何确保Livy服务端失效的时候已创建的所有会话不受影响,同时Livy服务端恢复过来后能够与已有的会话重新连接以继续使用?
Livy提供了失败恢复的机制,当用户启动会话的同时Livy会在可靠的存储上记录会话相关的元信息,一旦Livy从失败中恢复过来它会试图读取相关的元信息并与Spark集群重新连接。为了使用该特性我们需要配置Livy使其开启此功能:
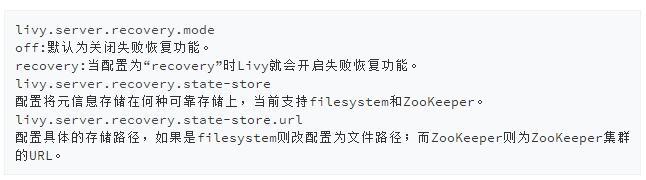
失败恢复能够有效地避免因Livy服务端单点故障造成的所有会话的不可用,同时也避免了因Livy服务端重启而造成的会话不必要失效。
结语
本文从Spark处理交互方式的局限引出了Livy这样一个基于Spark的REST服务。同时全面介绍了其基本架构、核心功能以及企业级特性,Livy不仅涵盖了Spark所提供了所有处理交互方式,同时又结合了多种的企业级特性,虽然Livy项目现在还处于早期,许多的功能有待增加和改进,我相信假以时日Livy必定能成为一个优秀的基于Spark的REST服务。
为了帮助大家让学习变得轻松、高效,给大家免费分享一大批资料,帮助大家在成为大数据工程师,乃至架构师的路上披荆斩棘。在这里给大家推荐一个大数据学习交流圈:658558542 欢迎大家进群交流讨论,学习交流,共同进步。
当真正开始学习的时候难免不知道从哪入手,导致效率低下影响继续学习的信心。
但最重要的是不知道哪些技术需要重点掌握,学习时频繁踩坑,最终浪费大量时间,所以有有效资源还是很有必要的。
最后祝福所有遇到瓶疾且不知道怎么办的大数据程序员们,祝福大家在往后的工作与面试中一切顺利。