概述
在分析树形结构之前,先看一下树形结构在整个数据结构中的位置
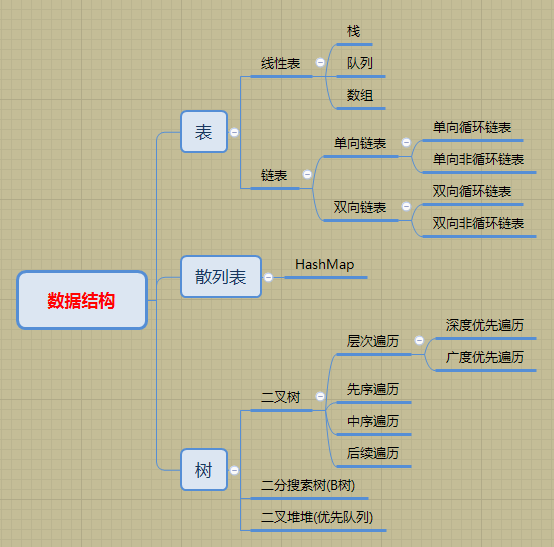
当然,没有图,现在还没有足够的水平去分析图这种太复杂的数据结构,表数据结构包含线性表跟链表,也就是经常说的数组,栈,队列等,在前面的Java容器类框架中已经分析过了,上面任意一种数据结构在java中都有对应的实现,比如说ArrayList对应数组,LinkedList对应双向链表,HashMap对应了散列表,JDK1.8之后的HashMap采用的是红黑树实现,下面单独把二叉树抽取出来:

由于树的基本概念基本上大家都有所了解,现在重点介绍一下二叉树
正文
二叉树
二叉树(binary tree)是一棵树,其中每个节点都不能有多于两个的儿子。
分类
- 满二叉树:若设二叉树的高度为h,除第 h 层外,其它各层 (1~h-1) 的结点数都达到最大个数,第h层有叶子结点,并且叶子结点都是从左到右依次排布,这就是完全二叉树。
- 完全二叉树:除了叶结点外每一个结点都有左右子叶且叶子结点都处在最底层的二叉树。
- 平衡二叉树:称为AVL树(区别于AVL算法),它是一棵二叉排序树,且具有以下性质:它是一棵空树或它的左右两个子树的高度差的绝对值不超过1,并且左右两个子树都是一棵平衡二叉树。
对于完全二叉树,若某个节点数为i,左子节点位2i+1,右子节点为2i+2。
实现
下面用代码实现一个二叉树
public class BinaryNode {
Object data;
BinaryNode left;
BinaryNode right;
}
遍历
二叉树的遍历有两种:按照节点遍历与层次遍历
节点遍历
- 前序遍历:遍历到一个节点后,即刻输出该节点的值,并继续遍历其左右子树(根左右)。
- 中序遍历:遍历一个节点后,将其暂存,遍历完左子树后,再输出该节点的值,然后遍历右子树(左根右)。
- 后序遍历:遍历到一个节点后,将其暂存,遍历完左右子树后,再输出该节点的值(左右根)。
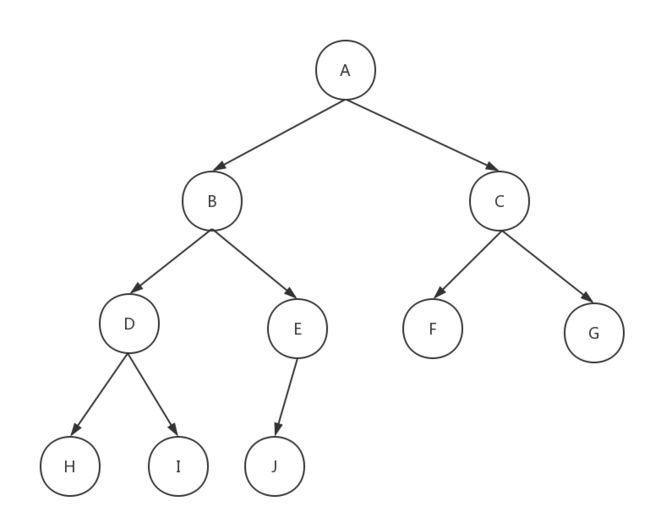
构造完全二叉树
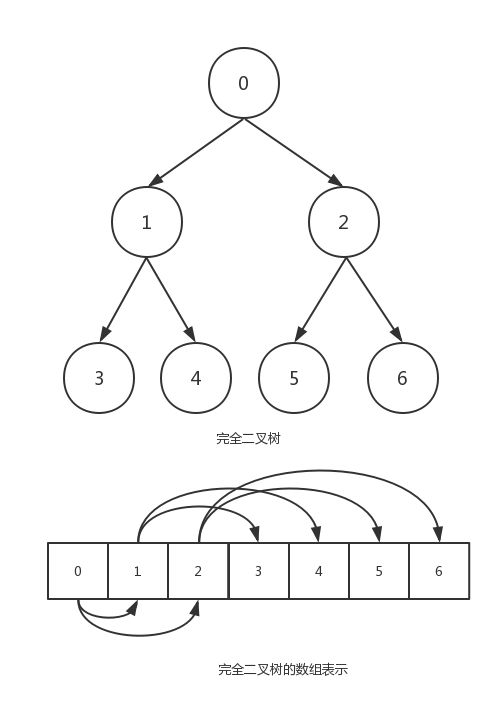
就以上图的二叉树为例,首先用代码构造一棵完全二叉树
节点类TreeNode
public class TreeNode {
private int value;
private TreeNode leftChild;
private TreeNode rightChild;
public TreeNode(int value) {
super();
this.value = value;
}
public int getValue() {
return value;
}
public void setValue(int value) {
this.value = value;
}
public TreeNode getLeftChild() {
return leftChild;
}
public void setLeftChild(TreeNode leftChild) {
this.leftChild = leftChild;
}
public TreeNode getRightChild() {
return rightChild;
}
public void setRightChild(TreeNode rightChild) {
this.rightChild = rightChild;
}
}
生成完全二叉树
//数组
private int[] saveValue = {0,1, 2, 3, 4, 5, 6};
private ArrayList list = new ArrayList<>();
public TreeNode createTree() {
//将所有的节点保存进一个List集合里面
for (int i = 0; i < saveValue.length; i++) {
TreeNode treeNode = new TreeNode(saveValue[i]);
list.add(treeNode);
}
//根据完全二叉树的性质,i节点的左子树是2*i+1,右节点字数是2*i+2
for (int i = 0; i < list.size() / 2; i++) {
TreeNode treeNode = list.get(i);
//判断左子树是否越界
if (i * 2 + 1 < list.size()) {
TreeNode leftTreeNode = list.get(i * 2 + 1);
treeNode.setLeftChild(leftTreeNode);
}
//判断右子树是否越界
if (i * 2 + 2 < list.size()) {
TreeNode rightTreeNode = list.get(i * 2 + 2);
treeNode.setRightChild(rightTreeNode);
}
}
return list.get(0);
}
前序遍历
//前序遍历
public static void preOrder(TreeNode root) {
if (root == null)
return;
System.out.print(root.value + " ");
preOrder(root.left);
preOrder(root.right);
}
遍历结果: 0 1 3 4 2 5 6
中序遍历
//中序遍历
public static void midOrder(TreeNode root) {
if (root == null)
return;
midOrder(root.left);
System.out.print(root.value + " ");
midOrder(root.right);
}
遍历结果:3 1 4 0 5 2 6
后序遍历
//后序遍历
public static void postOrder(TreeNode root) {
if (root == null)
return;
postOrder(root.left);
postOrder(root.right);
System.out.print(root.value + " ");
}
遍历结果:3 4 1 5 6 2 0
上述三种方式都是采用递归的方式进行遍历的,当然也可以迭代,感觉迭代比较麻烦,递归代码比较简洁,仔细观察可以发现,实际上三种遍历方式都是一样的,知识打印value的顺序不一样而已,是一种比较巧妙的方式。
层次遍历
二叉树的层次遍历可以分为深度优先遍历跟广度优先遍历
- 深度优先遍历:实际上就是上面的前序、中序和后序遍历,也就是尽可能去遍历二叉树的深度。
- 广度优先遍历:实际上就是一层一层的遍历,按照层次输出二叉树的各个节点。
深度优先遍历
由于上面的前序、中序和后续遍历都是采用的递归的方式进行遍历,下面就以前序遍历为例,采用非递归的方式进行遍历
步骤
- 若二叉树为空,返回:
- 用一个stack来保存二叉树
- 然后遍历节点的时候先让右子树入栈,再让左子树入栈,这样右子树就会比左子树后出栈,从而实现先序遍历
//2.前序遍历(迭代)
public static void preorderTraversal(TreeNode root) {
if(root == null){
return;
}
Stack stack = new Stack();
stack.push(root);
while( !stack.isEmpty() ){
TreeNode cur = stack.pop(); // 出栈栈顶元素
System.out.print(cur.data + " ");
//先压右子树入栈
if(cur.right != null){
stack.push(cur.right);
}
//再压左子树入栈
if(cur.left != null){
stack.push(cur.left);
}
}
}
遍历结果:0 1 3 4 2 5 6
广度优先遍历
所谓广度优先遍历就是一层一层的遍历,所以只需要按照每层的左右顺序拿到二叉树的节点,再依次输出就OK了
步骤
- 用一个LinkedList保留所有的根节点
- 依次输出即可
//分层遍历
public static void levelOrder(TreeNode root) {
if (root == null) {
return;
}
LinkedList queue = new LinkedList<>();
queue.push(root);
while (!queue.isEmpty()) {
//打印linkedList的第一次元素
TreeNode cur = queue.removeFirst();
System.out.print(cur.value + " ");
//依次添加每个节点的左节点
if (cur.left != null) {
queue.add(cur.left);
}
//依次添加每个节点的右节点
if (cur.right != null) {
queue.add(cur.right);
}
}
}
遍历结果:0 1 2 3 4 5 6
二叉堆
二叉堆是一棵完全二叉树或者是近似完全二叉树,同时二叉堆还满足堆的特性:父节点的键值总是保持固定的序关系于任何一个子节点的键值,且每个节点的左子树和右子树都是一个二叉堆。
分类
- 最大堆:父节点的键值总是大于或等于任何一个子节点的键值
-
最小堆:父节点的键值总是小于或等于任何一个子节点的键值
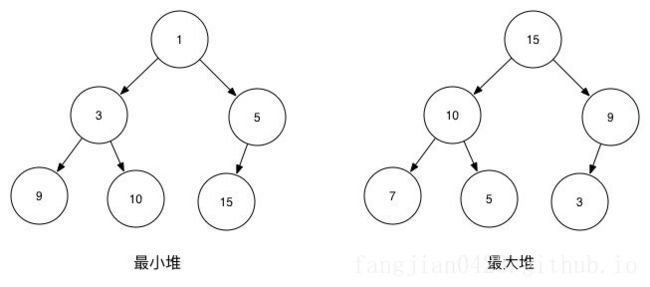 二叉堆的分类
二叉堆的分类
由于二叉堆 的根节点总是存放着最大或者最小元素,所以经常被用来构造优先队列(Priority Queue),当你需要找到队列中最高优先级或者最低优先级的元素时,使用堆结构可以帮助你快速的定位元素。
性质
-
结构性质:堆是一棵被完全填满的二叉树,有可能的例外是在底层,底层上的元素从左到右填入。这样的树称为完全二叉树。
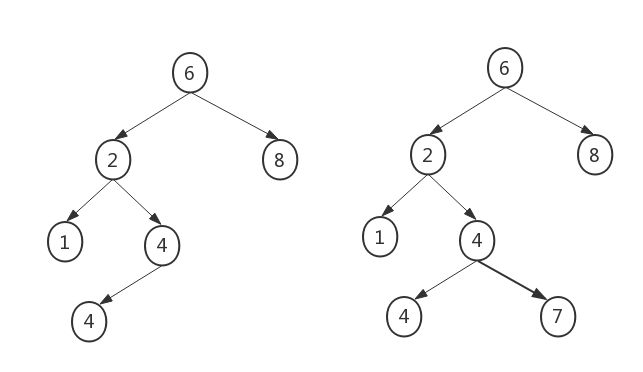
 一棵完全二叉树
一棵完全二叉树
实现
二叉堆可以用数组实现也可以用链表实现,观察上述的完全二叉树可以发现,是比较有规律的,所以完全可以使用一个数组而不需要使用链。下面用数组来表示上图所对应的堆结。

对于数组中任意位置i的元素,其左儿子在位置2i上,右儿子在左儿子后的单元(2i+1)中,它的父亲则在位置[i/2上面]
public class MaxHeap- {
protected Item[] data;
protected int count;
protected int capacity;
// 构造函数, 构造一个空堆, 可容纳capacity个元素
public MaxHeap(int capacity) {
data = (Item[]) new Comparable[capacity + 1];
count = 0;
this.capacity = capacity;
}
// 返回堆中的元素个数
public int size() {
return count;
}
// 返回一个布尔值, 表示堆中是否为空
public boolean isEmpty() {
return count == 0;
}
// 像最大堆中插入一个新的元素 item
public void insert(Item item) {
assert count + 1 <= capacity;
data[count + 1] = item;
count++;
shiftUp(count);
}
// 交换堆中索引为i和j的两个元素
private void swap(int i, int j) {
Item t = data[i];
data[i] = data[j];
data[j] = t;
}
//调整堆中的元素,使其成为一个最大堆
private void shiftUp(int k) {
// k/2表示k节点的父节点
while (k > 1 && data[k / 2].compareTo(data[k]) < 0) {
//子节点跟父节点进行比较,如果父节点小于子节点则进行交换
swap(k, k / 2);
k /= 2;
}
}
}
构造一个二叉堆
// 测试 MaxHeap
public static void main(String[] args) {
MaxHeap maxHeap = new MaxHeap<>(100);
int N = 50; // 堆中元素个数
int M = 100; // 堆中元素取值范围[0, M)
for (int i = 0; i < N; i++)
maxHeap.insert((int) (Math.random() * M));
System.out.println(maxHeap.size());
}
insert操作
public void insert(Item item) {
//从第1个元素开始赋值
assert count + 1 <= capacity;
data[count + 1] = item;
count++;
//上虑操作
shiftUp(count);
}
上虑操作
先将新插入的元素加到数组尾部,然后跟父节点进行比较,如果比父节点大就进行交换
private void shiftUp(int k) {
// k/2表示k节点的父节点
while (k > 1 && data[k / 2].compareTo(data[k]) < 0) {
//子节点跟父节点进行比较,如果父节点小于子节点则进行交换
swap(k, k / 2);
k /= 2;
}
}
获取最大元素
public Integer extractMax(){
assert count > 0;
Integer ret = data[1];
swap( 1 , count );
count --;
//下虑操作
shiftDown(1);
return ret;
}
下虑操作
先将根节点跟最后一个元素进行交换,然后将count减1,然后根节点再跟左子树与右子树之间的最大值进行比较
private void shiftDown(int k){
while( 2*k <= count ){
int j = 2*k; // 在此轮循环中,data[k]和data[j]交换位置
if( j+1 <= count && data[j+1].compareTo(data[j]) > 0 )
j ++;
// data[j] 是 data[2*k]和data[2*k+1]中的最大值
if( data[k].compareTo(data[j]) >= 0 )
//当前节点比根节点大,中断循环
break;
//交换节点跟子树
swap(k, j);
k = j;
}
}
二叉查找树
二叉查找树:对于树中的每个节点X,它的左子树中所有项的值小于X中的项,而它的右子树中的所有项的值大于X中的项。
实现
public class BST, Value> {
private class Node {
private Key key;
private Value value;
private Node left, right;
public Node(Key key, Value value) {
this.key = key;
this.value = value;
left = right = null;
}
public Node(Node node){
this.key = node.key;
this.value = node.value;
this.left = node.left;
this.right = node.right;
}
}
// 构造函数, 默认构造一棵空二分搜索树
public BST() {
root = null;
count = 0;
}
// 返回二分搜索树的节点个数
public int size() {
return count;
}
// 返回二分搜索树是否为空
public boolean isEmpty() {
return count == 0;
}
}
contains方法
// 调用contains (root,key)
public boolean contain(Key key){
return contain(root, key);
}
// 查看以node为根的二分搜索树中是否包含键值为key的节点, 使用递归算法
private boolean contain(Node node, Key key){
if( node == null )
return false;
//根节点的key跟查询的key相同,直接返回true
if( key.compareTo(node.key) == 0 )
return true;
//key小的话遍历左子树
else if( key.compareTo(node.key) < 0 )
return contain( node.left , key );
//key大的话遍历右子树
else // key > node->key
return contain( node.right , key );
}
insert方法
// 向二分搜索树中插入一个新的(key, value)数据对
public void insert(Key key, Value value){
root = insert(root, key, value);
}
// 向以node为根的二分搜索树中, 插入节点(key, value), 使用递归算法
// 返回插入新节点后的二分搜索树的根
private Node insert(Node node, Key key, Value value){
//空树直接返回
if( node == null ){
count ++;
return new Node(key, value);
}
//如果需要插入的key跟当前的key相同,则将值替换成最新的值
if( key.compareTo(node.key) == 0 )
node.value = value;
//如果需要插入的key小于当前的key,从左子树进行插入
else if( key.compareTo(node.key) < 0 )
node.left = insert( node.left , key, value);
else
//如果需要插入的key大于当前的key,从右子树进行插入
node.right = insert( node.right, key, value);
return node;
}
finMin方法
// 寻找二分搜索树的最小的键值
public Key minimum(){
assert count != 0;
Node minNode = minimum( root );
return minNode.key;
}
// 返回以node为根的二分搜索树的最小键值所在的节点
private Node minimum(Node node){
//递归遍历左子树
if( node.left == null )
return node;
return minimum(node.left);
}
finMax方法
// 寻找二分搜索树的最大的键值
public Key maximum(){
assert count != 0;
Node maxNode = maximum(root);
return maxNode.key;
}
// 返回以node为根的二分搜索树的最大键值所在的节点
private Node maximum(Node node){
//递归遍历右子树
if( node.right == null )
return node;
return maximum(node.right);
}
search方法
// 在二分搜索树中搜索键key所对应的值。如果这个值不存在, 则返回null
public Value search(Key key){
return search( root , key );
}
// 在以node为根的二分搜索树中查找key所对应的value, 递归算法
// 若value不存在, 则返回NULL
private Value search(Node node, Key key){
if( node == null )
return null;
if( key.compareTo(node.key) == 0 )
return node.value;
else if( key.compareTo(node.key) < 0 )
return search( node.left , key );
else // key > node->key
return search( node.right, key );
}
上面分析了三种比较特殊的树形结构,二叉树,二叉堆以及二叉搜索树,尤其是二叉堆跟二叉搜索树,尤其是二叉堆主要用于优先队列,二叉搜索树主要用来查找。