爬取糗事百科热门段子
效果图:

代码:
# python2
# -*- coding: utf-8 -*-
# Filename: qiushibaike_hot.py
"""
糗事百科爬虫
爬取24小时热门笑话第一页
过滤掉“图片”和“查看全文”
输出到屏幕
"""
import requests
import re
user_agent = ''
headers = {'User-Agent':user_agent}
# 读取网页上的数据
def download_data(url):
url = url
data = requests.get(url, headers = headers).content
return data
# 用正则得到正文数据,返回列表
def get_text(data):
data = data
text_list = re.findall('(.+?)', data, re.S)
return text_list
# 去掉数据中的空格、、
def remove_str(text):
text = text
# 去掉 、
text1 = re.sub('<.+?>', '', text)
# 去掉空格和空行
text2 = text1.replace(" ", "").replace('\n', '')
return text2
# 去掉过短的(一般是图片)和过长的(查看全文)段子
def remove_long(text):
text = text
if len(text) > 111 and len(text) < 600:
return text
def start(url):
url = url
data = download_data(url)
text_list = get_text(data)
for text in text_list:
text1 = remove_str(text)
# 去掉过短的(一般是图片)和过长的(查看全文)段子
if len(text1) > 111 and len(text1) < 600:
print( text1 + '\n')
url = 'https://www.qiushibaike.com/hot/'
start(url)
print 'over'
知识点:
正则表达式
我们前面介绍过 re.findall ,接下来继续
本例的网页源代码是

我们用的正则表达式是 '(.+?)' ,说白了就是选取能把目标文本包起来的唯一的字符串。
贪婪匹配与非贪婪匹配
.* 为贪婪匹配,.*? 为非贪婪匹配
先看示例:
源字符串:aatest1bbtest2cc
正则表达式一:.*
匹配结果一:test1bbtest2
正则表达式二:.*?
匹配结果二:test1(这里指的是一次匹配结果,所以没包括test2)
简单说,贪婪匹配就是匹配尽量长的结果,非贪婪匹配就是匹配尽量短的结果
我们通常用的都是非贪婪匹配
re.sub 方法
re.sub 用于替换字符串中的匹配项,返回替换后的字符串。
语法:
re.sub(pattern, repl, string, count=0, flags=0)
# pattern : 正则中的模式字符串。
# repl : 替换的字符串,也可为一个函数。
# string : 要被查找替换的原始字符串。
# count : 模式匹配后替换的最大次数,默认 0 表示替换所有的匹配。
# flags:标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。
# 参数 count 和 flags 有默认值,可不写
示例:
str_1 = "hello 123 world 456"
# 想把123和456,都换成222
str_2 = re.sub("\d+", "222", str_1)
Python 正则表达式详细语法说明
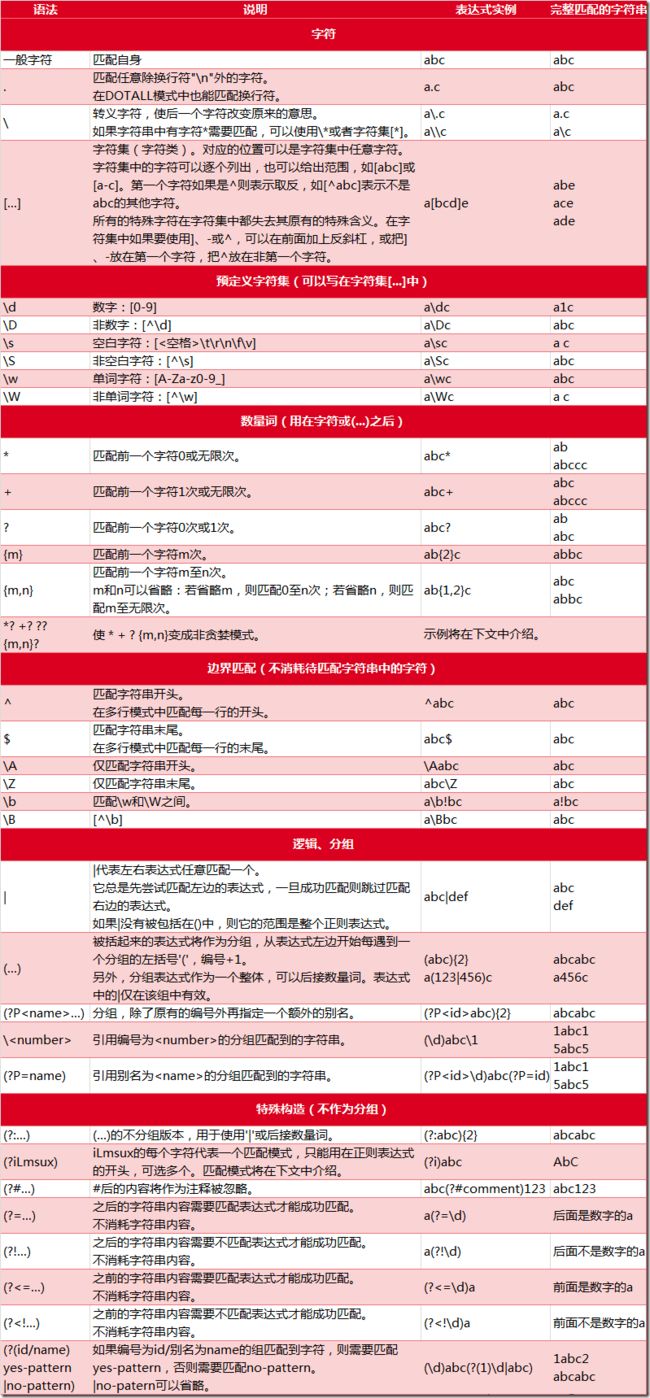
flags 标志位说明
标志位
描述
re.I
使匹配对大小写不敏感
re.L
做本地化识别(locale-aware)匹配
re.M
多行匹配,影响 ^ 和 $
re.S
使 . 匹配包括换行在内的所有字符
re.U
根据Unicode字符集解析字符。这个标志影响 \w, \W, \b, \B.
re.X
该标志通过给予你更灵活的格式以便你将正则表达式写得更易于理解。
replace() 方法
把字符串中的 old(旧字符串) 替换成 new(新字符串),如果指定第三个参数max,则替换不超过 max 次。 返回生成的新字符串。
语法
str.replace(old, new, max)
# old -- 将被替换的子字符串。
# new -- 新字符串,用于替换old子字符串。
# max -- 可选字符串, 替换不超过 max 次
示例:
str = "this is string example....wow!!! this is really string";
print str.replace("is", "was");
print str.replace("is", "was", 3);
# 输出结果:
thwas was string example....wow!!! thwas was really string
thwas was string example....wow!!! thwas is really string
replace() 还可以连用,例如:
text.replace('/p',' ').replace('p', ' ')
len() 函数
返回字符串和序列的长度。示例:
>>> len("aab")
3
>>> len([1,2])
2
if 语句
if 语句的基本形式:
if <判断语句1>:
<执行1>
elif <判断语句2>:
<执行2>
elif <判断语句3>:
<执行3>
else:
<执行4>
if 语句是从上往下运行判断语句,如果某个判断语句结果是True,则运行其对应的缩进块,忽略掉剩下的elif和else。
如果 if 和 elif 的判断语句都为 False,则执行 else 后面的缩进块。
注意:
1.else 后面没有条件判断。
2.if语句 可以只有 if ,没有后面的 elif 、else
3.Python 中任何非 0 和非空(null)值为都为 True,0 或者空值(null)为 False。
示例:
num = 5
if num == 3:
print 'boss'
elif num == 2:
print 'user'
elif num == 1:
print 'worker'
elif num < 0:
print 'error'
else:
print 'roadman'
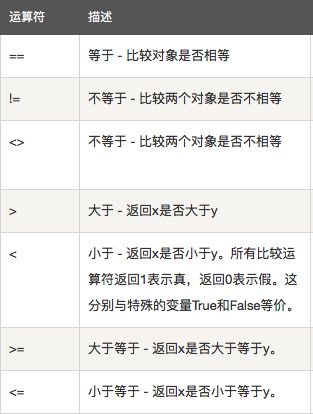
比较运算符
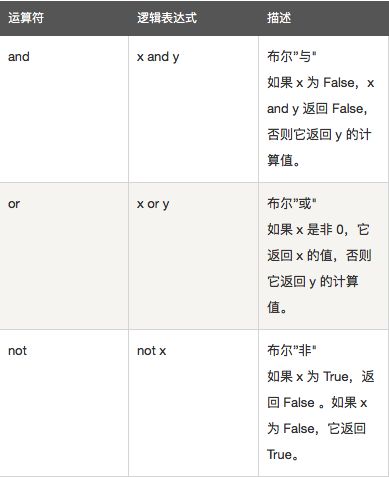
逻辑运算符
代码解释
if len(text1) > 111 and len(text1) < 600:
print( text1 + '\n')
# len(text1) 计算 text1 的长度
# 判断 len(text1) > 111 的结果是 True 还是 False
# 判断 len(text1) < 600 的结果是 True 还是 False
# 把上面两项的结果取 逻辑与
# if 语句,如果 len(text1) > 111 and len(text1) < 600 为 True,则运行下面 print 语句
# 如果为 False ,则跳过下面 print 语句,进行下一轮循环
教程目录:
0.《简介及准备》
1.《爬单个图片》
2.《下载一组网页上的图片》
3.《输出一个网页上的文字》
4.《获取电影天堂最新电影名称》
5.《糗事百科爬虫》
20181203