一、天猫词云
1.天猫评论数据爬取
爬虫代码:
import re
import requests
'''
获取淘宝指定商品所有评论
自动获取评论页码数
'''
def main():
#模拟浏览器访问
headers = {'user-agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}
url = "https://rate.tmall.com/list_detail_rate.htm?itemId=536695141637&spuId=692024154&sellerId=202224264&order=3"
payload = {'currentPage':1} #g构建字典传递页码参数到url
file = open('五谷磨房红豆薏米粉红枣薏仁粉五谷杂粮磨坊现磨营养代餐粥粉.txt', 'w', encoding='utf-8')
# 自动获取所有评论页码
pageNum = re.findall(r'"lastPage":[^,"]+', requests.get(url, params=payload, headers=headers).text, re.I)
for page_Num in pageNum:
last_page = int(page_Num.strip('lastPage":'))
for k in range(0,last_page):
payload['currentPage'] = k + 1
resp = requests.get(url, params=payload, headers=headers)
#resp.encoding = 'gbk'
# 正则保存所有resp.text的内容,款式,评论内容,评论时间
sku = re.findall(r'"auctionSku":"([^"]+)"', resp.text, re.I)
content = re.findall(r'"rateContent":"([^"]+)"', resp.text, re.I)
data = re.findall(r'"rateDate":"([^"]+)"', resp.text, re.I)
# 每一页评论的数量
x = len(content)
# 把评论数据保存到文件中
for i in range(0, x):
file.write(content[i] + '\n')
print("正在写入第",20 * k + i + 1,"条")
#file.write(str( 20 * k + i + 1 ) + '款式:' + sku[i] + '\n' + '评价内容:' + content[i] + '\n' + '日期:' + data[i] + '\n'+ '\n\n')
#print("正在写入第",20 * k + i + 1,"条")
file.close()
if __name__ == '__main__':
main()
2 词频统计

词频统计.png
3 词云

易词云.png
二、淘宝词云
1.淘宝评论数据爬取
import requests
import json
def getCommodityComments(url):
if url[url.find('id=')+14] != '&':
id = url[url.find('id=')+3:url.find('id=')+15]
else:
id = url[url.find('id=')+3:url.find('id=')+14]
file = open('淘宝五谷磨房红豆薏米粉红枣薏仁粉五谷杂粮磨坊现磨营养代餐粥粉.txt', 'w', encoding='utf-8')
url = 'https://rate.taobao.com/feedRateList.htm?auctionNumId='+id+'¤tPageNum=1'
res = requests.get(url)
jc = json.loads(res.text.strip().strip('()'))
max = jc['total']
users = []
comments = []
count = 0
page = 1
print('该商品共有评论'+str(max)+'条,具体如下: loading...')
while count>',comments[count])
count = count + 1
# 每一页评论的数量
x = len(comments)
# 把评论数据保存到文件中
for i in range(0, x):
file.write(comments[i] + '\n')
file.close()
getCommodityComments('https://item.taobao.com/item.htm?id=536613323530&')
2 词频统计
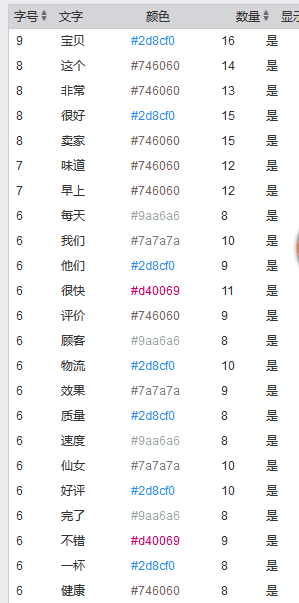
词频统计.png
3 词云

易词云.png
三、京东词云
1.京东评论数据爬取
import requests
import json
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36'}
#url = 'https://sclub.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98vv12345&productId=19523497981&score=0&sortType=5&page=0&pageSize=10&isShadowSku=0&fold=1'
url='https://sclub.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98vv158&productId=3914278&score=0&sortType=5&page=0&pageSize=10&isShadowSku=0&fold=1'
res = requests.get(url,headers=headers)
jd=json.loads(res.text.lstrip('fetchJSON_comment98vv12345(').rstrip(');'))
#上面这行真是让我蛋疼半天的元首,记住要去掉无关字符
com_list=jd['comments']
file = open('京东五谷磨房红豆薏米粉红枣薏仁粉五谷杂粮磨坊现磨营养代餐粥粉.txt', 'w', encoding='utf-8')
for i in com_list:
content =i['content']
file.write(content) #写入文件
print(i['content'])
file.close()
2 词频统计
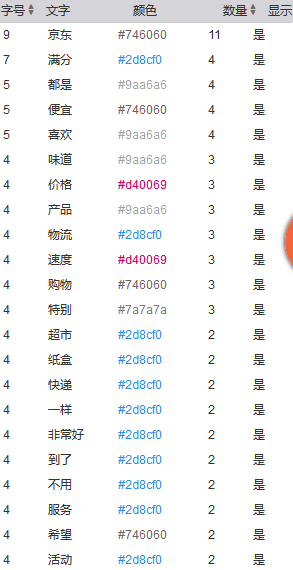
词频统计.png
3 词云

易词云(2).png
4 Python 制作词云
主要用到jieba分词包、numpy计算包、pandas数据分析包、WordCloud词云包、codecs语言代码处理包、matplotlib绘图功能包。
推荐安装anaconda,其中会集成numpy、pandas、codecs、matplotlib等包。
安装jieba分词包,WordCloud词云包
pip3 install jieba
pip3 install wordcloud
代码如下:
#coding:utf-8
import jieba #分词包
import numpy #numpy计算包
import codecs #codecs语言代码处理包
import pandas #数据分析包
import matplotlib.pyplot as plt
from wordcloud import WordCloud#词云包
file=codecs.open(u"京东五谷磨房红豆薏米粉红枣薏仁粉五谷杂粮磨坊现磨营养代餐粥粉.txt",'r',encoding='utf-8')
content=file.read()
file.close()
segment=[]
segs=jieba.cut(content) #切词
for seg in segs:
if len(seg)>1 and seg!='\r\n':
segment.append(seg)
words_df=pandas.DataFrame({'segment':segment})
words_df.head()
stopwords=pandas.read_csv("stopwords.txt",index_col=False,quoting=3,sep="\t",names=['stopword'],encoding="gb18030")
words_df=words_df[~words_df.segment.isin(stopwords.stopword)]
#词频计数
words_stat=words_df.groupby(by=['segment'])['segment'].agg({"计数":numpy.size})
words_stat=words_stat.reset_index().sort_values(by="计数",ascending=False)
words_stat #打印统计结果
#根据背景图制作词云
from scipy.misc import imread
import matplotlib.pyplot as plt
from wordcloud import WordCloud,ImageColorGenerator
%matplotlib
bimg=imread('tuoyuan.jpg')
wordcloud=WordCloud(background_color="white",mask=bimg,font_path='simhei.ttf')
#wordcloud=wordcloud.fit_words(words_stat.head(4000).itertuples(index=False))
words = words_stat.set_index("segment").to_dict()
wordcloud=wordcloud.fit_words(words["计数"])
bimgColors=ImageColorGenerator(bimg)
plt.axis("off")
plt.imshow(wordcloud.recolor(color_func=bimgColors))
plt.show()
词频统计:

词频统计.png
词云图:

京东词云.png
四、遇到的问题:
1)数据量大,工程化存储问题
2)包含未填写评论数据,需清洗处理
参考资料:
Project 1 :Python爬虫源码实现抓取淘宝指定商品所有评论并保存到文件
利用Python爬虫爬取淘宝商品做数据挖掘分析实战篇,超详细教程
Python爬虫 获得淘宝商品评论
【Python】【爬虫】爬取京东商品用户评论(分析+可视化)
从京东评论中挖掘出用户关注的关键字,并使其可视化
京东评论用jieba分词并用词云可视化
京东商城评论爬虫
用柱状图,圆饼图,散点图等来显示词频,可视化
用Python生成词云
超简单:快速制作一款高逼格词云图
Python + wordcloud + jieba 十分钟学会用任意中文文本生成词云
利用python做微信聊天记录词云分析——记录美好回忆
京东的验证码和反爬都很烦人吧?那又怎样,照样轻松爬取京东数据
手把手教你写电商爬虫-第五课 京东商品评论爬虫 一起来对付反爬虫
Python 爬虫 爬取京东 商品评论 数据,并存入CSV文件
Python 模拟京东登录
京东商品和评论的分布式爬虫
京东评论爬虫(详解)