1、简述rpm与yum命令的常见选项,并举例
rpm命令
rpm -i 安装某个程序包
rpm -v 显示过程
rpm -h 显示进度条
rpm -q 查询某个程序包
rpm -e 删除安装的的程序包
rpm -U -F 升级与更新命令
-U升级安装
-F 只有安装了老版本需要升级新版本
rpm -V 校验
rpm -builddb -initdb 数据库维护
组合:
rpm -ivh
rpm -Uvh -Fvh
rpm -qa -qf -qi -qd ..(根据文件种类来查询)
rpm安装一般以组合命令为主
如最平常的-ivh
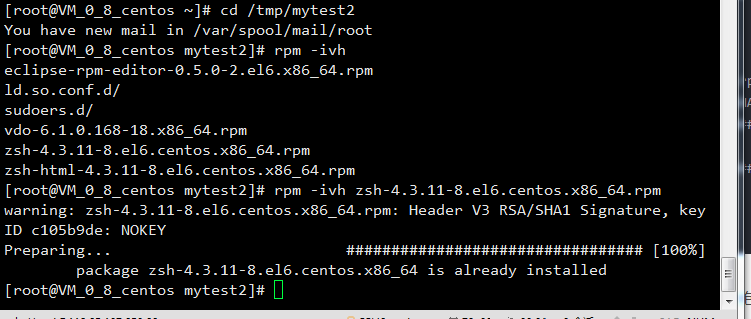
因为我之前已经安装了zsh安装包,所以显示is already installed
不过我们测试-e来删除重新安装
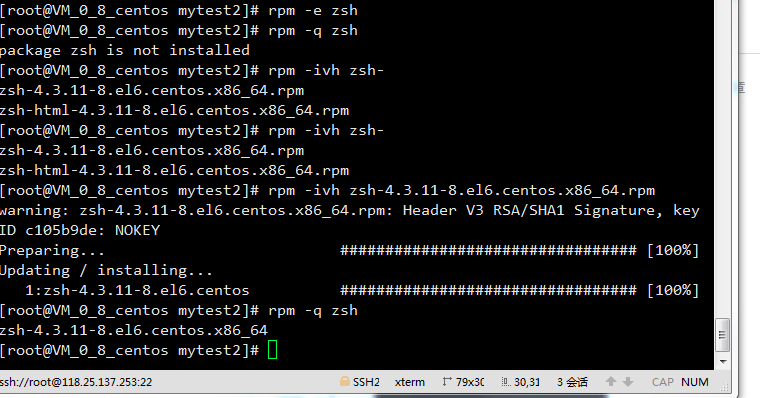
这时候我们可以看到在-e 后重新安装-ivh 成功,并通过-q来查询zsh ,发现之前删除后提示的not installed 现在已经有安装了,所以就是这么简单。但是rpm无法解决依赖关系。
rpm -i 安装rpm包有安装属性选项,如以下属性选项:
--test 测试安装,检查并报告其依赖关系和冲突消息等,用法:rpm -i --test PACKAGE_NAME;
--nodeps 忽略依赖关系,不建议使用,用法:rpm -ivh --nodeps;
--replacepkgs 重新安装,主要应用于配置文件遭改动等,用法:rpm -i --replacepkgs;
rpm -e 也有选项属性:比如:
--allmatches 卸载所有匹配指定名称的程序包的各个版本;
--nodeps 忽略依赖关系卸载;
--test 测试卸载,不是真正的卸载,只是测试使用,如dry run(干跑)模式。
rpm -q 为查询,其附加命令有很多
如:
-qa 查询已经安装的所以程序包
-qf 查询指定文件是由哪个程序包提供的
-qd 查询程序包提供哪些帮助文件
-qp 查询系统未安装的程序包
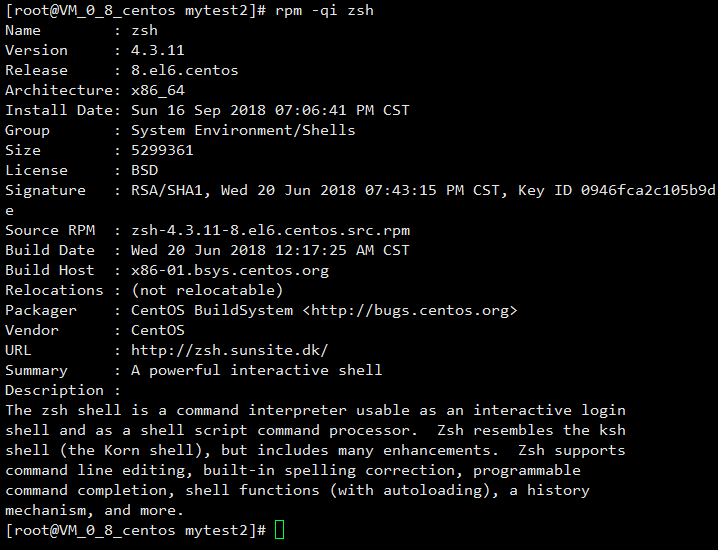
-qi 查询程序包的相关信息
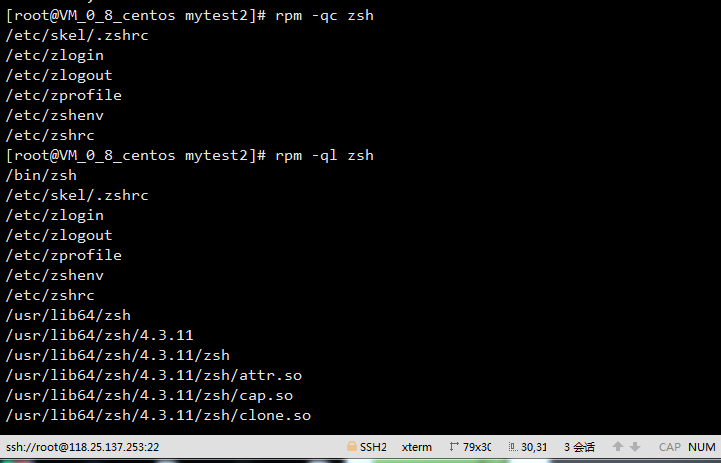
-qc 查询程序包的配置文件
-ql 查看程序包生成的所有文件
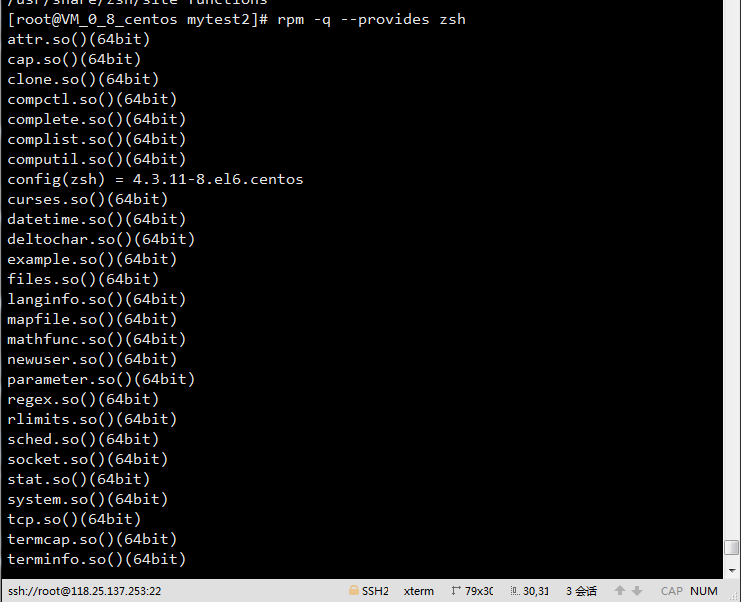
-q --provides 查询指定的程序包提供的所有的CAPABILITY
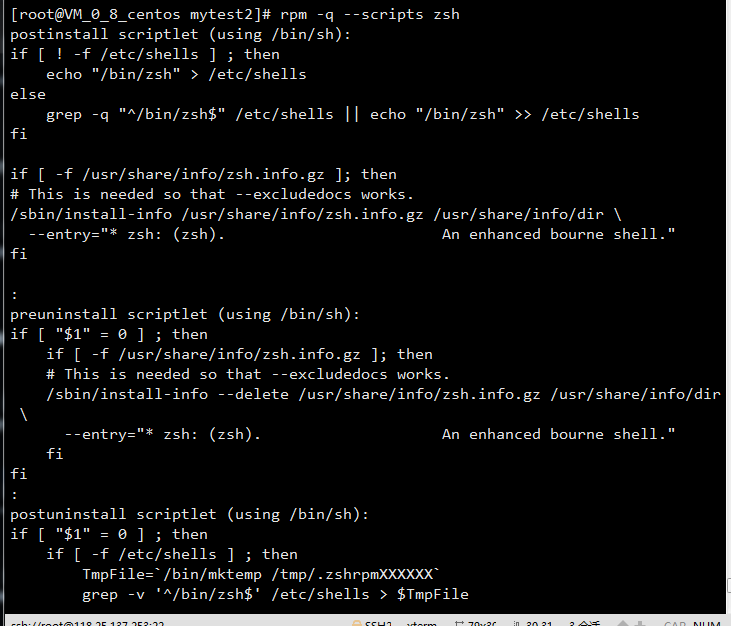
-q --scripts 查询程序包自带的脚本信息

rpm -V 校验:
rpm -V [select options | verify options]
verify options:包来源合法性验证和完整性验证
来源合法性验证通过数字签名,完整性验证通过获取并导入信任的包制作者的密钥;
数据库重建:
rpm数据库的位置路径为:/var/lib/rpm/,查询操作,通过此处的数据库进行;
rpm --initdb | --rebuilddb
--initdb 初始化数据库,当前无任何数据库可初始化创建一个新的,当前有时不执行任何操作;
--rebuilddb 重新构建,通过读取当前系统上所有已经安装过的程序包进行重新构建;
yum命令
主要命令有:
yum install 安装程序包
yum update [yum update-to] 升级程序包
yum check-update 检查可用升级
yum upgrade
yum remove 卸载程序包
yum provides 查看指定文件是哪个程序包提供
yum clear 清理本地缓存
yum makecache 构建缓存
yum list 显示程序包
yum info 查看程序包信息
yum groupinstall 安装包组
yum groupupdate 升级包组
yum grouplist 包组列表
yum groupremove 包组卸载
yum groupinfo' 包组相关信息查询
yum search 通过关键字来搜索程序包及相关信息
yum localinstall 本地程序包安装
yum localupdate 本地程序包升级
yum reinstall 安装程序包
yum resolvedep
yum deplist 查看指定包所依赖的包组件
yum repolist 显示仓库列表
yum version 查看当前yum版本
yum history 查看yum历史
options:yum的命令选项(常用选项)
-y --assumeyes 避免交互式安装,交互回答时,自动回答为“yes”;
-c --config=[config file] 指明安装时的配置文件安装,可为HTTP,FTP,本地文件路径;
-q --quiet 静默安装模式 不输出安装信息;
--nogpgcheck 安装时禁止进行gpg检查;
--disablerepo=repoidglob 临时禁用此处指定的repo仓库
--enablerepo=repoidglob 临时启用此处指定的repo仓库
--noplugins 禁用所有的插件安装
2、自建yum仓库,分别为网络源和本地源
yum客户端:
配置文件:
/etc/yum.conf:为所有仓库提供公共配置
/etc/yum.repos.d/*.repo:为仓库的指向提供配置
keepcache=0(是否缓存)
debuglevel=2(调试级别)
logfile=/var/log/yum.log(指向日志文件)
exactarch=1(精确平台匹配)
obsoletes=1
gpgcheck=1(包完整性)
plugins=1(yum支持的插件机制)
installonly_limit=5(同时安装的的包个数)
distroverpkg=centos-release(支持centos)
仓库指向的定义:
[repositoryID]
name=Some name for this repository
baseurl=url://path/to/repository/
enabled={1|0}
gpgcheck={1|0}
gpgkey=URL
enablegroups={1|0}
failovermethod={roundrobin|priority}
默认为:roundrobin,意为随机挑选;
cost=
默认为1000
1. 本地源,一般是指通过系统光盘制作仓库,或者直接指向本地网络的FTP服务器仓库路径;
首先需要挂载光盘文件,可用mount命令查看是否挂载文件,再用mount -r -t iso9660 /dev/cdrom /media/cdrom挂载。
[root@localhost ~]#
[root@localhost ~]# mount -r -t iso9660 /dev/cdrom /media/cdrom/
[root@localhost ~]# ls /media/cdrom/
CentOS_BuildTag EFI EULA GPL images isolinux LiveOS Packages repodata RPM-GPG-KEY-CentOS-7 RPM-GPG-KEY-CentOS-Testing-7 TRANS.TBL
[root@localhost ~]# cd /media/cdrom/repodata/
[root@localhost repodata]# ls
115749f609bb070c1a0524edbe39312defa896eab1b8c8ff9844f078d1efdd95-primary.xml.gz
281832be789b989fe8c543f9de47992c0b1de080a4c7f7971a587cfa64d58f86-other.sqlite.bz2
283c19e8d3c6ff8541ddc19ea36d974e6afdc2770257a04622fc0aa5280b4322-filelists.xml.gz
38b60f66d52704cffb8696750b2b6552438c1ace283bc2cf22408b0ba0e4cbfa-c7-x86_64-comps.xml
6addbbcab39d561cf037917505807e1547d0d06937b539a01ae1d55a62d2a552-other.xml.gz
9346184be1deb727caf4b1ecf4a7949155da5da74af9b92c172687b290a773df-c7-x86_64-comps.xml.gz
ce678501a07f940dbe16d3e4fcb495050fd48ec429c5e8ea955e681594f90934-filelists.sqlite.bz2
f64ccdaf79da59bd21f7cf17f252ff62f2e56ea55bce5b4de16cf8ef1d13a7c8-primary.sqlite.bz2
repomd.xml
TRANS.TBL
[root@localhost repodata]#
挂载之后的目录repodata里面显示的就是CentOS系统提供的仓库镜像文件,只是对于版本没有更新,但大部分程序包都有。
[root@localhost ~]# cat /etc/yum.repos.d/mybase.repo
[mybase]
name=my base repo
baseurl=file:///media/cdrom/repodata
gpgcheck=0
enable=1
[root@localhost ~]#
这里是我写的一个简单的本地源仓库配置文件,虽然简单但是可以用,baseurl指向的是挂载后的光盘仓库路径,如果是ftp也可以改为ftp路径,切记路径的最后指向要是repodate这个目录。
2. 网络源yum仓库即把baseurl改成网络地址即可,这里我找到国内比较快的镜像站点,aliyun,163,sohu都可以,也可指向多个镜像站点,或者指向mirrorlist。
[root@localhost ~]#
[root@localhost ~]# cat /etc/yum.repos.d/mybase.repo
[mybase]
name=my base repo
baseurl=https://mirrors.aliyun.com/centos/7.5.1804/os/x86_64/repodata/
gpgcheck=0
enable=1
[root@localhost ~]#
当然这里需要你查看下自己的系统版本号,来找网上对应的版本仓库镜像文件,你也可以用/$releasever/$basearch等变量引用来找对应的系统版本镜像文件。
3、简述at和crontab命令,制定 每周三凌晨三、五点10分执行某个脚本,输出当前时间,时间格式为 2017-12-28 10:00:00
at和crontab都是计划任务执行命令,未来的某个时间点执行一次某任务用at,而周期性在某个时间点执行任务用crontab。
at
TIME时间表示法有精确表示和模糊表示两种;
精确表示:HH:MM [YYYY-mm-dd] 例如:10:10 2018-07-11 表示。如设定时间是过去的某个时间,将再下一次时间执行。
模糊表示:noon,midnight,teatimeata,tomorrow等
从当前时间开始计算表示:at now+#[unit] 这里的unit可为min,hours,days,years。例如now +1min表示从当前时间往后的1分钟之后开始执行任务。
常用的选项:
-l:查看作业队列,相当于atq
-f /PATH/FROM/SOMEFILE:从指定文件中读取作业任务,而不用再交互式输入;
-d:删除指定的作业,相当于atrm;
-c:查看指定作业的具体内容;
-q QUEUE:指明队列;
crond命令:
区别于at命令的执行一次失效性结束,crond是周期性执行某一任务。
crond分为
1.系统crond任务 编辑/etc/crontab文件
2.用户crond任务 编辑 /var/spool/cron/USERNAME
时间表示法:
(1) 特定值;
给定时间点有效取值范围内的值;注意:day of week和day of month一般不同时使用;
(2) * 给定时间点上有效取值范围内的所有值;
表“每..”(3) 离散取值:,在时间点上使用逗号分隔的多个值;#,#,#
(4) 连续取值:-在时间点上使用-连接开头和结束
#-#(5) 在指定时间点上,定义步长:
/#:#即步长;
而这里编辑文件内容用5个*来表示周期性不同时间段执行任务
* * * * * 第一星表示每分钟 第二个星表示每小时 第三个星表示每天 第四个星表示每月 第五个星表示每周星期几
数字表示位置前的与数字最近的表示方式来确定(有点绕)
举例来说明:
4 * * * * 就是表示每小时执行一次,但是表示每小时的第4分钟执行一次
4 5 * * * 就是表示每天执行一次,但是每天的5点4分执行一次
3 4 * * 5 表示每周执行一次 ,但是每周星期5 的4点3分执行
5 6 4 * * * 表示每个月执行一次,表示每个月每周的4号的6点5分执行一次
5 7 8 9 * 表示每年执行一次,表示每年9月8,7点5分执行一次
通过时间表示法来写:
9 8 * * 3,7 表示每周执行两次,但是每周的星期3和星期天 8点9分执行
0 8,20 * * 3,7 表示每周执行次数,表示的是每周三早上8点和晚上8点执行和星期天早上8点和晚上8点执行
0 9-18 * * 1-5 表示每周1到5 9点到18点每隔一个小时执行一次
*/5 * * * * 每5分钟执行一次
* */12 * * * 每隔12小时执行一次
crontab命令:
选项:-e 编辑任务
-l 列出任务
-r 移除所有任务,即删除用户的cron配置文件
如果需要删除单个任务,crontab -e 编辑文件之后进入删除单行任务即可;
-i 在使用-r移除所有任务时提示用户确认,与用户交互的选项;
-u username root用户可以为指定的用户定义其任务内容;
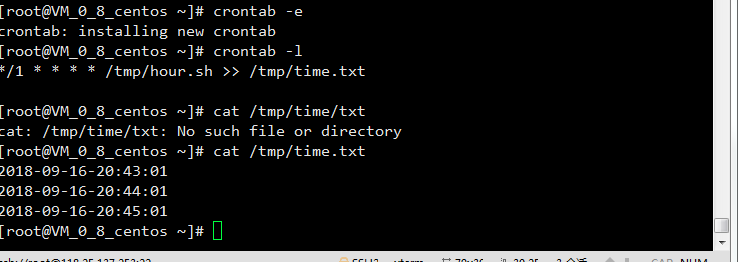
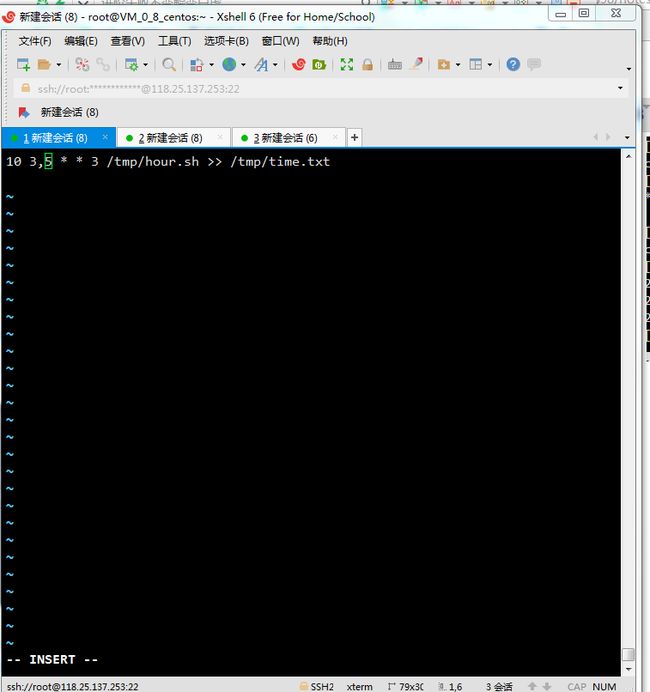
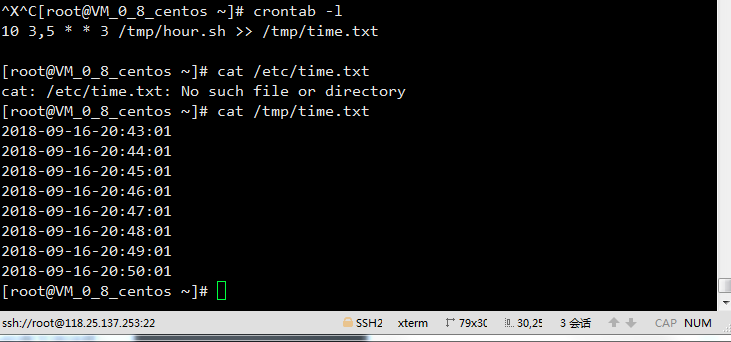
示例:每周三凌晨三、五点10分执行某个脚本,输出当前时间,时间格式为 2017-12-28 10:00:00
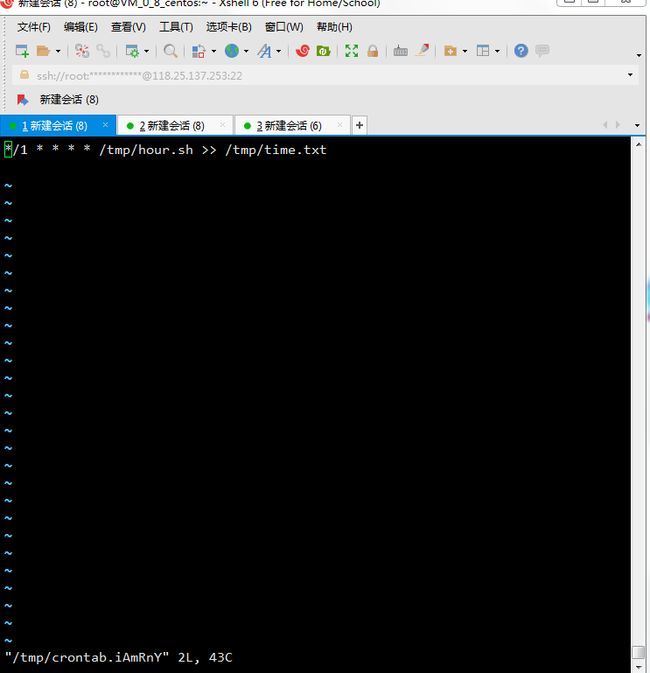

根据题目我把时间修改为要求
4、简述sed常用操作命令,并举例。
文本处理三剑客:
grep, egrep, fgrep:文本过滤器
sed:Stream EDitor,流编辑器,行
awk:文本格式化工具,报告生成器
常用选项:
-n:不输出模式空间中的内容至屏幕;
-e script, --expression=script:多点编辑;
-f /PATH/TO/SED_SCRIPT_FILE 指定编辑命令脚本文件;脚本文件中每一行为一个编辑命令;
地址定界:
1. 如果为空字符,则表示对全文进行处理,编辑查看操作;
2. # (number)数字,表示单地址,指定行(这里所说的操作对象都是文本文件,故有行数之说);也可定义/pattern/被模式匹配到的每一行;
3. 地址范围定义,#,#:1,3表示第1行到第3行的内容;#,+#;#,/pattern1/;/pat1/,/pat2/;$表示最后一行;
4. 步进地址,用~表示:“1~2”表示从第一行步进2行,就是1,3,5,7,9...行数,可表示为所有奇数行;“2~2”表示从第二行步进2行,就是2,4,6,8...行数,可表示所有偶数行。
地址定界后的编辑命令类型:
d 删除操作,表示地址定界模式匹配到的行做删除操作;整行删除;
p 显示模式空间中的行;一般与-n选项配合使用,但是要搞清楚逻辑是非关系,否则会很晕;
a \text 表示在行下方追加“text”内容,支持使用\n实现多行追加;
i \text 表示在行上方插入“text”内容,支持使用\n实现多行插入;
c \text 表示把匹配到的行替换为此处指定的文本“text”内容;
w /PATH/TO/SOMEFILE 保存模式空间中匹配到的行至指定文件中;
r /PATH/TO/SOMEFILE 读取指定的文件内容至当前文件被模式匹配待的行的后面,实现文件合并;
= 为模式空间匹配到的行打印行号;
! 条件取反;一般格式例如:地址定界!编辑命令 模式匹配到的行不执行什么编辑操作;
s///,s@@@,s###,查找替换,也支持vim编辑器命令行模式下的s查找替换功能,s@@@g修饰符g表示全局替换;
高级编辑命令:
h:把模式空间中的内容覆盖至保持空间中;
H:把模式空间中的内容追加至保持空间中;
g:把保持空间中的内容覆盖至模式空间中;
G:把保持空间中的内容追加至模式空间中;
x:把模式空间中的内容与保持空间中的内容互换;
n:覆盖读取匹配到的行的下一行至模式空间中;
N:追加读取匹配到的行的下一行至模式空间中;
d:删除模式空间中的行;
D:删除多行模式空间中的所有行;
现在主要以高级编辑命令来说明:
sed编辑视图
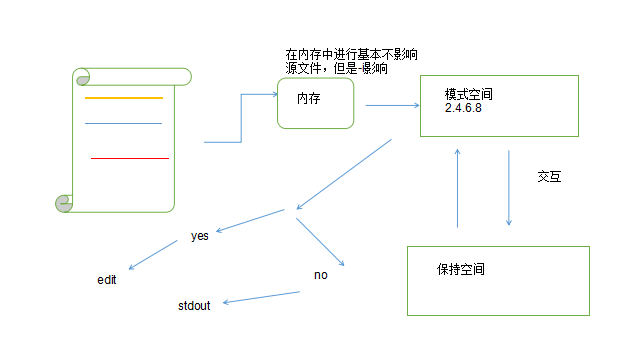
sed 在其自有程序内部进行,根据匹配模式/pattern/ 要求进行,并分为模式空间与保持空间,首先当我使用编辑时模式空间根据匹配模式进行选择匹配的内容并显示出来。

1.sed -n 'n;p' FILE:
1.sed -n 'n;p'FILE 进行的图片详解
当第一行进行模式匹配发现n即向下匹配一行并在模式空间输出,接下来sed进行第二行匹配发现p即显示匹配内容,又因为-n 不显示匹配模式内容,2跳过,接下到第三行,发现n 即向下匹配一行在模式空间输出,即偶数行匹配
2.sed '1!G;h;$!d' FILE:
第二题我们发现要用到与保持空间的关系,首先sed匹配第一行,发现1!G,即第一行不要把保持空间的内容添加到模式空间中,然后遇到h,把模式空间内容覆盖至保持空间,即现在保持空间为1,遇到$!d,最后一行不删除,即模式空间1删除。sed匹配第二行,遇到1!G,即把保持空间内容添加至模式空间,即模式空间为2,1,保持空间为1,遇到h,即把模式空间内容覆盖至保持空间,即模式空间为0,保持空间为2,1.遇到$!d,即不是最后一行删除,所以模式空间为0,保持空间为2,1. 然后sed匹配最后一行,遇到1!G,把保持空间内容添加至模式空间,即模式空间3,2,1,保持空间为2,1,然后遇到h,即把模式空间内容覆盖至保持空间,即模式为3,2,1,保持为3,2,1,遇到$!d,即最后一行不删除并输出发现逆序显示

3.sed ’$!d' FILE:取出最后一行;

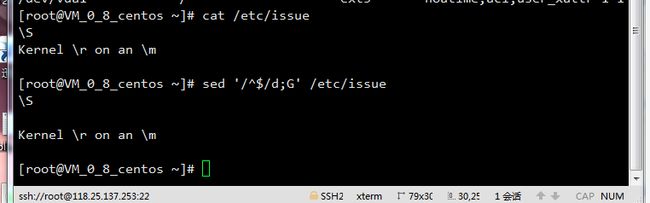
4.sed '/^$/d;G' FILE:
也是以三行为列,假如二行是空白行,13不是空白行, 首先sed模式匹配发现/^$/d 正则表达式,即删除空白行,第一行不是不删除,遇到G添加命令,保持空间为0,所以模式空间1,0,sed模式匹配第二行发现/^$/d,第二行即空白行删除,发现G,即模式空间为1,0,,第三行发现/^$/d,非空白行不删除,又把保持空间为0添加至模式空间,模式空间发现1,0,3,0规律,得出,该命令为删除空白行并为非空白行向后添加1个空白行