前言
我是一个机器学习的入门者。看了很多前辈大神的推荐,从西瓜书(周志华老师《机器学习》)或者 Coursera 吴恩达机器学习视频入门比较好。我比较喜欢书籍,因为做起笔记比较方便。有输入同时有输出才能让学习效率更加好,所以边读边做笔记。下面我将按照西瓜书的章节来,如果有不对的地方,还望指导学习。
正文
首先,通过思维导图来描述一下西瓜书第一章的知识内容与结构。
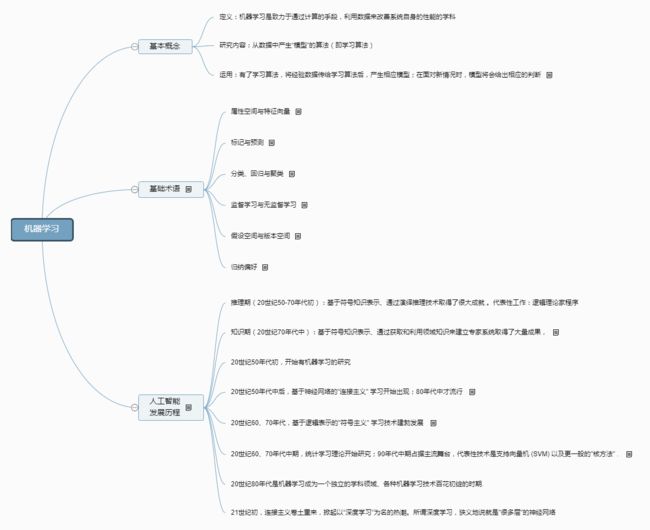
基本概念
在学习机器学习之前,首先要搞清楚它的定义、研究内容等等基本概念。
定义:机器学习是致力于通过计算的手段,利用数据来改善系统自身的性能的学科
研究内容:从数据中产生“模型”的算法(即学习算法)
如何运用:有了学习算法,将经验数据传给学习算法后,产生相应模型;在面对新情况时,模型将会给出相应的判断。
举个日常例子理解机器学习整个过程,当我们有了一些西瓜(训练数据集),且知道哪些是好瓜哪些是坏瓜。这时候我们需要剖开一个个西瓜,看看哪些好瓜/坏瓜,然后总结经验(学习并产生模型);当下次看到一个没剖开的瓜时,通过经验判断它是哪种瓜(运用模型去判断)。
基础术语
要进行机器学习,先要有数据。在机器学习,对数据的描述都有特定的术语。通过下面的例子来讲解机器学习中的基础术语。
假定我们收集了一批关于西瓜的数据,例如(色泽=青绿;根蒂=蜷缩;敲声=浊响), (色泽=乌黑;根蒂=稍蜷;敲声=沉闷), (色泽=浅自;根蒂=硬挺;敲声=清脆),……,每对括号内是一条记录,"=",意思是"取值为"
属性:反映事件或对象在某方面的表现或性质的事项。例如每条记录中的“色泽”、“根蒂”、“敲声”就是西瓜的属性
属性空间:属性张成的空间。例如我们把"色泽" "根蒂" "敲声"作为三个坐标轴,则它们张成一个用于描述西瓜的三维空间就是属性空间
特征向量:每个西瓜都可在这个空间中找到自己的坐标位置。由于空间中的每个点对应一个坐标向量,因此我们也把这个坐标向量称为一个特征向量。
三者的关系总结:将每个属性作为一个坐标轴,多个属性就多个坐标轴,从而形成一个描述物体的属性空间。此空间中的每个样本对应一个点,每个点都有一个坐标向量,把这个坐标向量称为特征向量。
如果希望学得一个能帮助我们判断没剖开的是不是"好瓜"的模型,仅有前面的示例数据显然是不够的要建立这样的关于"预测" 的模型,我们还需获得训练样本的"结果"信息,例如"((色泽=青绿;根蒂=蜷缩;敲声=浊响),好瓜)" 。
标记:关于示例结果的信息,比如上面例子中的 "好瓜" 就属于标记。
样例:拥有了标记信息的示例,则称为样例。一般地,用 表示第 i 个样例,其中 是特征向量, 是这个样本的标记。
机器学习的目标是希望通过对训练集 { } 进行学习,建立一个从输入空间 X 到输出空间 Y 的映射
根据预测结果的类型,可以将机器学习任务分为二类。
- 分类:预测结果的类型是离散值,例如"好瓜","坏瓜";
- 回归:预测结果的类型是连续值,例如西瓜的成熟度0.37、0.95。
根据训练数据是否拥有标记信息,学习任务也可大致划分为两大类。
- 监督学习(supervised learning):训练数据有标记信息,其中分类与回归属于监督学习。
- 无监督学习(unsupervised learning):训练数据没有标记信息,代表有聚类。
聚类:将训练集中的西瓜分成若干组,每组称为一个"簇"; 这些自动形成的簇可能对应一些潜在的概念划分,例如"浅色瓜"与"深色瓜" ,甚至"本地瓜"与"外地瓜"。这个学习过程有助于我们了解数据内在的规律,能为更深入地分析数据建立基础。
需说明的是,在聚类学习中,"浅色瓜"与"本地瓜"这样的概念我们事先是不知道的,而且学习过程中使用的训练样本通常不拥有标记信息。
假设空间与版本空间
假设空间:所有假设构成的集合。
版本空间:只保留了假设空间中与训练数据集中正例一致的假设,由这些正确的假设构成的集合成为版本空间(简单来说,版本空间就是正例的泛化)。
下面介绍假设空间大小计算、构建假设空间以及版本空间。(PS:初学时难点在于对版本空间的理解与构建)
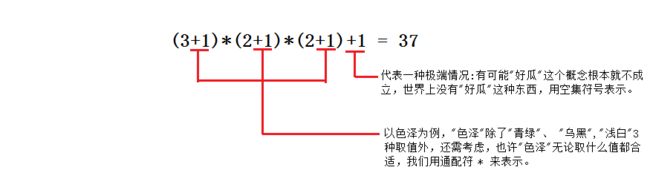
举个例子,假设西瓜的好坏由“色泽”,“根蒂”以及“敲声”决定,且"色泽"、"根蒂"和"敲声"分别有3、2、2 种可能取值。用布尔表达式表示则是
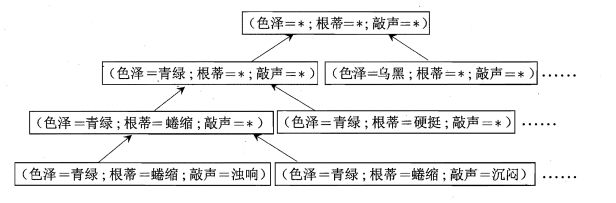

版本空间构建过程:首先对假设空间进行搜索。有许多策略对假设空间搜索,如自顶向下和自底向上。然后在搜索过程中只保留与训练集正例一致的假设。比如搜索到(色泽=青绿,根蒂=蜷缩,敲声=浊响)这个假设时,它本身与训练集第 1 条正例一致,但是与训练集中第 2 条正例不一致,所以需要剔除。因为若这个假设保留到版本空间且根据版本空间的定义,说明色泽非青绿,根蒂非蜷缩,敲声非浊响的瓜都为坏瓜,这与表中第 2 条正例相矛盾。再比如搜索到(色泽=*,根蒂=*,敲声=浊响)这个假设可以保留到版本空间,因为当它成立时,我们可以对于表中的4个训练示例都做出正确的判断,即它与训练集的所有正例一致。最后在上面训练集构建的版本空间如图。(此处西瓜书上图画错了)
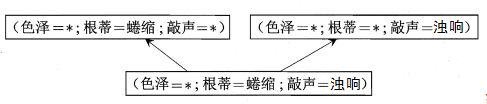
版本空间作用除了能对已知的数据样本做出判断外,版本空间还可以对没有在训练集中出现的示例进行判断。如给一个(色泽=浅白) ⋀ (根蒂=蜷缩) ⋀ (敲声=浊晌) 瓜,通过版本空间判断它是好瓜。
最后,上面求出来了西瓜问题的版本空间,但可以看到版本空间不是很确定,包含有通配符 * 的假设可能会得到正确的判断,也可能得到错误的判断(这句话是针对实际问题,如果针对上表中的训练集,那当然不会有错误的判断)
因此,要想判断的正确,就要全面、大量的训练,以排除更多假设空间中的错误假设。错误假设越少,剩下的假设越少,就越有可能是正确假设,我们判断的结果的正确概率越大。
归纳偏好
从假设空间到版本空间是一个归纳过程(即从特殊到一般的过程)。
现在有一个问题,例如(色泽=青绿,根蒂=蜷缩,敲声=沉闷)这新瓜,如果采用(色泽=*) ⋀ (根蒂=蜷缩) ⋀ (敲声=*)这个假设进行判断,这新瓜就是好瓜;但是采用(色泽=*) ⋀ (根蒂=*) ⋀ (敲声=浊响)这个假设判断,这新瓜就是坏瓜。那么,应该采用哪一个模型(或假设)呢?
若仅有上表中的训练样本,则无法断定上述三个假设中明哪一个"更好".然而,对于一个具体的学习算法而言?它必须要产生一个模型。这时,学习算法本身的"偏好"就会起到关键的作用。
归纳偏好(简称"偏好"):机器学习算法在学习过程中对某种类型假设的偏好。
任何一个有效的机器学习算法必有其归纳偏好,否则它将被假设空间中看似在训练集上"等效"的假设所迷惑,无法产生确定的学习结果。如果没有偏好,刚才那个例子就没有确定的答案了。这样的学习结果显得没有意义。
最后,算法的归纳偏好是否与问题本身匹配,大多数时候直接决定了算法能否取得好的性能。
以上就是西瓜书第一章主要的知识点。主要以介绍机器学习概念和一些基础术语为主。
机器学习小白一个,若有错误之处,还希望大佬们指点指点,也会及时改正。