概念:
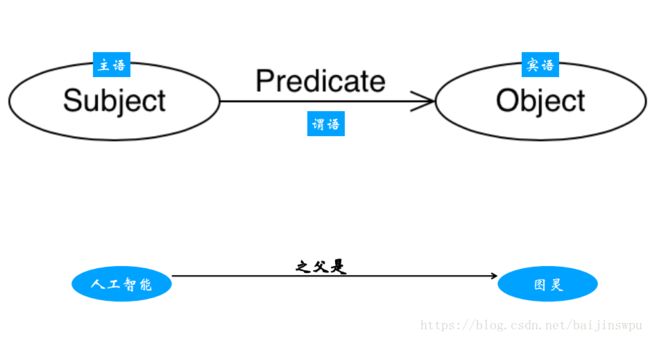
知识图谱是由一些相互连接的实体和他们的属性构成的。换句话说,知识图谱是由一条条知识组成,每条知识表示为一个SPO三元组(Subject-Predicate-Object)。
表示方法:传统+向量
传统的知识图谱表示方法是采用OWL、RDF、RDFS(改进)等本体语言进行描述;
RDF:(Resource Description Framework,资源描述框架)
RDF由节点和边组成,节点表示实体/资源、属性,边则表示了实体和实体之间的关系以及实体和属性的关系,其本质是一个数据模型(Data Model)。它提供了一个统一的标准,用于描述实体/资源。简单来说,就是表示事物的一种方法和手段。RDF形式上表示为SPO三元组,资源——关系——资源。
表示方法一:
表示方法二:N-Triples表示
<http://www.kg.com/person/2> <http://www.kg.com/ontology/chineseName> "川普"^^string. <http://www.kg.com/person/2> <http://www.kg.com/ontology/position> "美利坚第45任总统"^^string. <http://www.kg.com/person/2> <http://www.kg.com/ontology/wife> "梅拉尼娅-特朗普"^^string. <http://www.kg.com/person/2> <http://www.kg.com/ontology/nation> "USA"^^string. <http://www.kg.com/person/2> <http://www.kg.com/ontology/age> "72"^^int. <http://www.kg.com/person/2> <http://www.kg.com/ontology/belongparty> <http://www.kg.com/Party/2018>. <http://www.kg.com/party/2018> <http://www.kg.com/ontology/name> "republic"^^string. <http://www.kg.com/party/2018> <http://www.kg.com/ontology/fonder> "汉尼巴尔·哈姆林"^^string. <http://www.kg.com/party/2018> <http://www.kg.com/ontology/born> "1854"^^data.
@prefix person: <http://www.kg.com/person/> . @prefix party: <http://www.kg.com/party/> . @prefix : <http://www.kg.com/ontology/> . person:1 :chineseName "川普"^^string; :position "美利坚第45任总统"^^string; :wife "梅拉尼娅-特朗普"^^string; :nation "USA"^^string; :age "72"^^int; party:2018 :name "汉尼巴尔·哈姆林"^^string; :born "1854"^^data.
RDFS:(RDF Schema)
RDFS在RDF的基础上定义了类(class)、属性(property)以及关系(relation)来描述资源,并且通过属性的定义域(domain)和值域(range)来约束资源。RDFS在数据层(data)的基础上引入了模式层(schema),模式层定义了一种约束规则,而数据层是在这种规则下的一个实例填充。
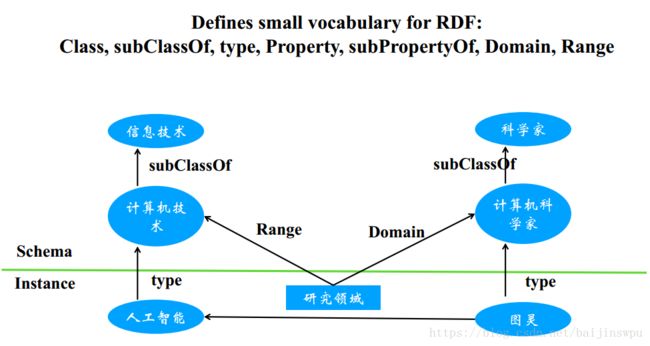
OWL:(Web Ontology Language,网络本体语言)
OWL是对RDFS关于描述资源词汇的一个扩展,OWL中添加了额外的预定于词汇来描述资源,具备更好的语义表达能力。在OWL中可以声明资源的等价性,属性的传递性、互斥性、函数性、对称性等等,具体见OWL的词汇扩展。



向量Embedding:TranE、TranH、TranM等
随着深度学习的发展与应用,我们期望采用一种更为简单的方式表示,那就是【向量】,采用向量形式可以方便我们进行之后的各种工作,比如:推理,所以,我们现在的目标就是把每条简单的三元组< subject, relation, object > 编码为一个低维分布式向量。
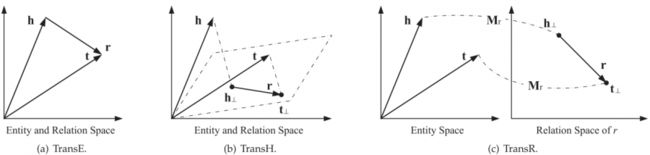
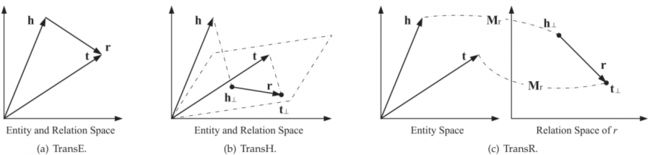
TranE:
将每个三元组实例(head,relation,tail)中的关系relation看做从实体head到实体tail的翻译,通过不断调整h、r 和 t(head、relation和tail的向量),使(h + r) 尽可能与 t 相等,即 h + r = t
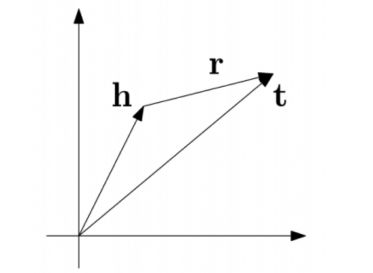
TransE 是基于实体和关系的分布式向量表示,由 Bordes 等人于2013年提出,受word2vec启发,利用了词向量的【平移不变现象】。
例如:C(king)−C(queen)≈C(man)−C(woman) 其中,C(w)就是word2vec学习到的词向量表示。
TransE 定义了一个距离函数 d(h + r, t),它用来衡量 h + r 和 t 之间的距离,在实际应用中可以使用 L1 或 L2 范数。在模型的训练过程中,transE采用最大间隔方法,最小化目标函数,目标函数如下:
![]()
其中,S是知识库中的三元组即训练集,S’是负采样的三元组,通过替换 h 或 t 所得,是人为随机生成的。γ 是取值大于0的间隔距离参数,是一个超参数,[x]+表示正值函数,即 x > 0时,[x]+ = x;当 x ≤ 0 时,[x]+ = 0 。算法模型比较简单,梯度更新只需计算距离 d(h+r, t) 和 d(h’+r, t’)。
缺点:
虽然TransE模型的参数较少,计算的复杂度显著降低,并且在大规模稀疏知识库上也同样具有较好的性能与可扩展性。但是TransE 模型不能用在处理复杂关系上 ,原因如下:以一对多为例,对于给定的事实,以姜文拍的民国三部曲电影为例,即《让子弹飞》、《一步之遥》和《邪不压正》。可以得到三个事实三元组即(姜文,导演,让子弹飞)、(姜文,导演,一步之遥)和(姜文,导演,邪不压正)。按照上面对于TransE模型的介绍,可以得到,让子弹飞≈一步之遥≈邪不压正,但实际上这三部电影是不同的实体,应该用不同的向量来表示。多对一和多对多也类似。
TranH:
TranH为了解决TranE一对多的问题:
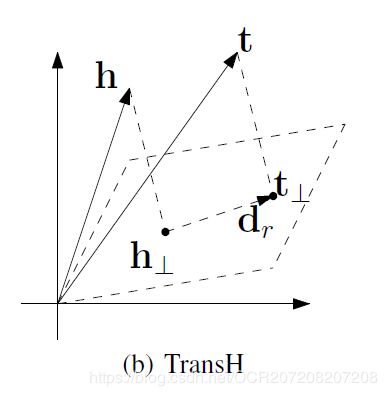

把h和t 投影到一个超平面,得到投影向量h⊥,r⊥,然后关系作为在这两个投影向量之间的平移。
对于每一种关系都要训练出一个超平面和与之对应的关系r,参数量有所增加。
TranR:
TransR 认为实体空间和关系空间应该是不同的。
实体 h 和 t 映射到关系空间中再做这种平移变换。
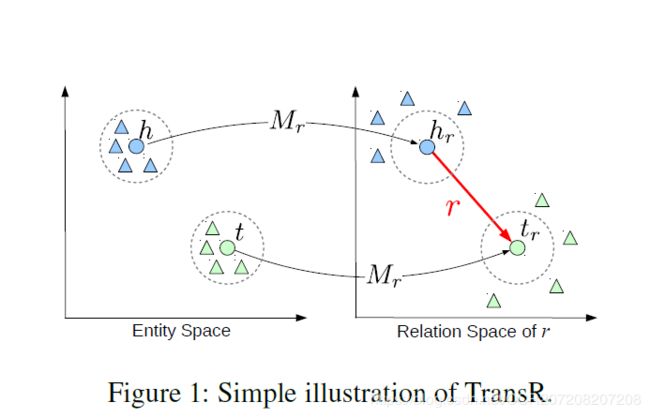

对于每一个关系有一个与之对应的r和 Mr
摘抄:
https://blog.csdn.net/baijinswpu/article/details/81185965
https://blog.csdn.net/weixin_40871455/article/details/83341561
https://blog.csdn.net/OCR207208207208/article/details/93490339