ElasticSearch中常用的中文切词器为 analysis-ik, 是个第三方插件;
ik主要有两种切词方式,一个是细粒度,一个是粗粒度,分别对应“ik_max_word”和“ik_smart”。
下面分别用实例看下他们切词结果的差异:


query: 北京百度网讯科技有限公司
ik_max_word: 北京;京;百度网;百度;百;度;网讯;网;讯;科技有限公司;科技有限;科技;有限公司;有限;有;限;公司;
ik_smart: 北京;百度;网讯;科技有限公司;
query: 重庆百业兴科技有限公司
ik_max_word: 重庆;庆;百业;百;业;兴;科技有限公司;科技有限;科技;有限公司;有限;有;限;公司;
ik_smart: 重庆;百业;兴;科技有限公司;
query: 查看通过分析器进行切词的结果
ik_max_word: 查看;通过;通;过分;分析器;分析;析;器;进行;行;切;词;结果;结;果;
ik_smart: 查看;通过;分析器;进行;切;词;结果;
(ik_max_word 竟然连“过分”都可以切出来,所以在生成倒排索引的时候,会比ik_smart多一倍以上的索引量,所以,效果虽好,评估好自己的ES存储空间再做合适的选择)
那么问题来了,既然ik_max_word要多占用非常大的空间,我就选择了ik_smart,但是ik_smart对特定的词切的简直太粗了,比如“科技有限公司”是作为一个完整的词切出来的,如果我的doc是“小米科技北京有限公司”,那这时候用“科技有限公司”是召回不了这条结果的;所以这种情况下,能不能认为进行干预呢?
是可以的,上面的情况中,其实我们是想“科技有限公司”最好是切成“科技”和“有限公司”,也就是说,如果我们把“技”作为一个停止词,那么就可以得到“科技”和“有限公司”。
ik插件的配置在 $root/es/plugins/analysis-ik/config/的 IKAnalyzer.cfg.xml 中,

我们只需要将“技”添加到custom/ext_stopword.dic这个词表文件中,然后重启ES,就能切出来了。
test:
我把“有”也加到了停止词里:ik_smart得到的结论是:并没有任何变化;
我又把“有”从停止词中去除了,放进了“限”去,ik_smart得到的结论是:依然没变化,这时候得去别的词表看看了,可能是另外的词表给干扰了。
还真是: 我在main.dic词表下(这是默认词库文件),找到了“有限公司”:
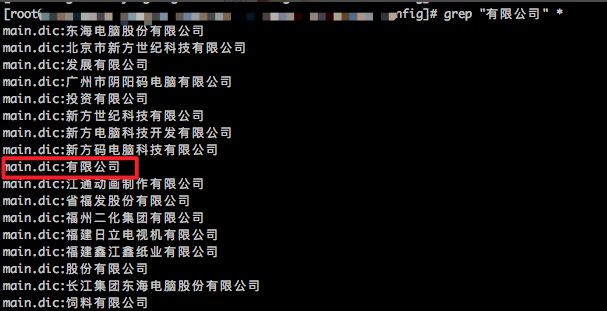
也就是说,遇到“有限公司”,直接就相当于已经切完了,不继续进行了,后面的停止词这些逻辑都不走了。
为了验证上面这一点:我从main.dic词表中,把“有限公司”删掉了,然后重启ES验证最终切词结果:
query: 北京百度网讯科技有限公司
ik_smart: 北京;百度;网讯;科技;有限;公司;
符合预期:OK了。
在main.dic词典中,我们发现有将近27万的词,其中有个“福州二化集团有限公司”,为了确认下是不是这里面的词都不切词,我就又做了下面的测试。

果真一点都不切了
那我加个字试试:

只切出了“幸”和“福州二化集团有限公司”,连“幸福”都切不出来了。
要想切出来,还得用ik_max_word,ik_max_word应该就是先按照本身的逻辑切词,再把命中后的完成的加进去。
那么这个词表是从上往下还是从下往上呢?通过下面的例子就可以看出来了:

实际上"长江集团东海电股份有限公司"和“东海电脑股份有限公司”都可以完整的切出来,也就是个最长匹配了啦,具体可以看下ik的源码。
参考:
https://blog.csdn.net/yangshangwei/article/details/99126548
https://github.com/medcl/elasticsearch-analysis-ik
https://www.cnblogs.com/zlslch/p/6441315.html?utm_source=itdadao&utm_medium=referral